Clear Sky Science · zh
通过混合颜色、纹理和深度学习特征增强基于内容的图像检索
为何找到合适的图片很重要
从医学影像到旅行照片,我们的生活充斥着图像。然而在庞大的集合中实际找到所需那张图片常常出乎意料地困难。本研究引入了CTD-Net,一种通过直接查看图中内容而非仅依赖标签或文件名来搜索大型图像数据库的新方法。该工作展示了将传统图像分析与现代深度学习相结合,如何使视觉搜索在准确性和实用性上都更适合现实场景。 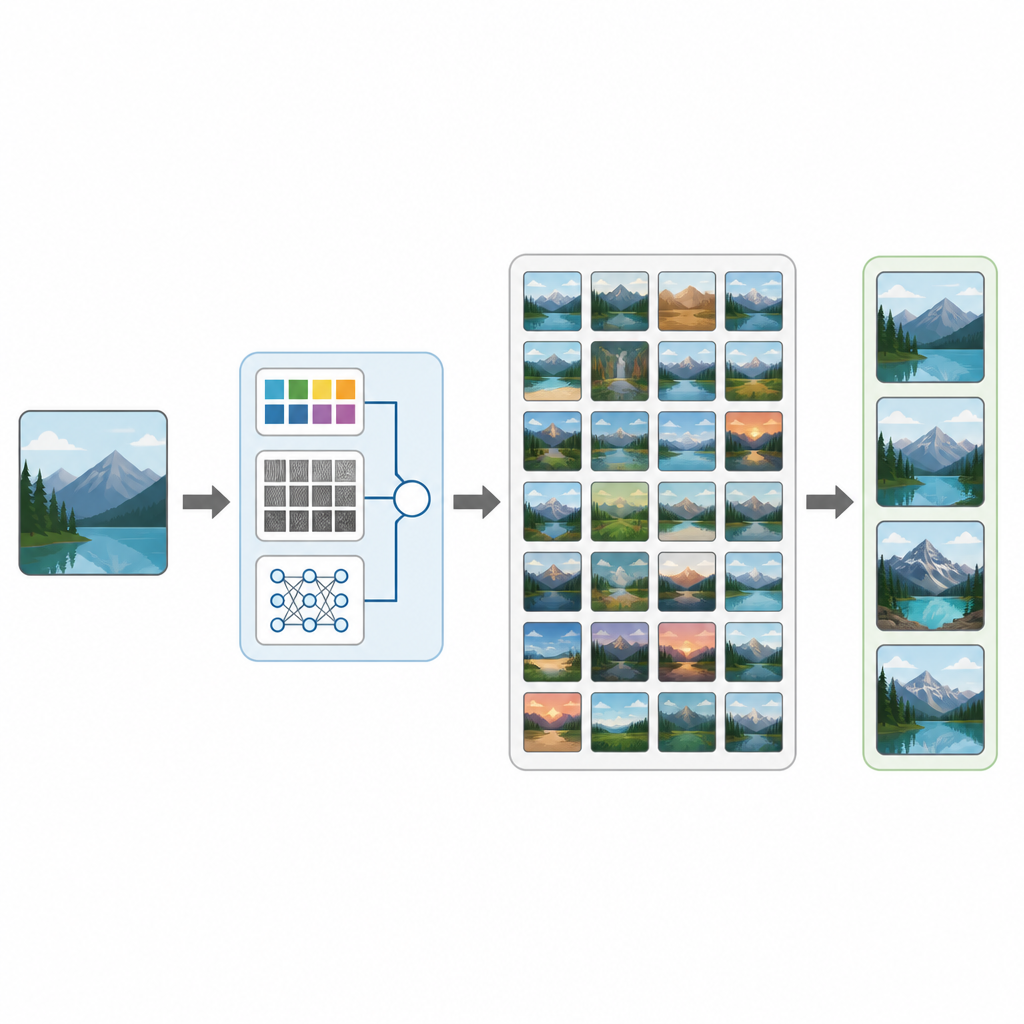
计算机通常如何搜索图像
早期图像搜索工具依赖人工添加的文本,例如说明和关键词。这种方法既慢又昂贵,而且常常不完整,因为不同的人会以不同方式描述相同场景。基于内容的图像检索改变了这一局面,它允许计算机查看每张图片中的颜色、形状和纹理。然而,许多现有系统在处理复杂场景时仍然不足。简单的颜色或纹理公式可能忽略重要细节,而纯深度学习模型可能需要海量数据且有时难以解释。结果是在计算机以数字方式“看到”的内容与人类识别为有意义内容之间存在差距。
将简单的图像线索与深度学习融合
CTD-Net通过结合每张图像的两类线索来弥合这一差距。首先,它提取描述基本视觉属性的手工特征。颜色直方图和颜色矩总结了色调在图像中的分布,而小波变换和局部二值模式则捕获细微的纹理模式和边缘。其次,系统将同一图像输入一种强大的深度神经网络EfficientNet-B7,后者学习更抽象的模式,例如物体部件和复杂布局。所有这些信号经过精细缩放并合并为一个长的特征向量,既包含简单的外观信息,也反映更丰富的场景语义。 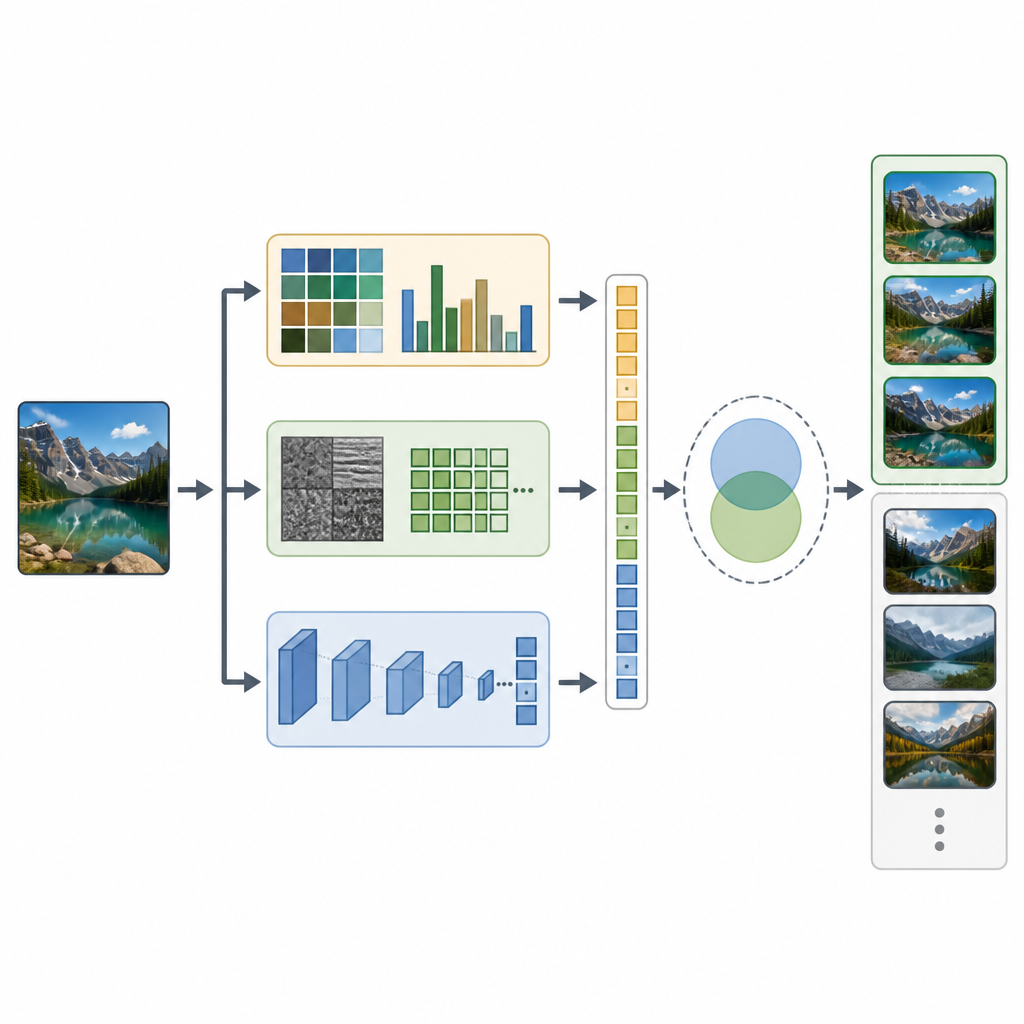
将特征转化为更好的搜索结果
一旦每张图像拥有合并后的指纹,CTD-Net就衡量任意两者指纹的相似度。作者测试了几种数学比较方法,发现余弦相似度给出了最可靠的匹配。实际使用中,用户提交查询图像,CTD-Net将其转换为特征,然后根据特征向量的接近程度对所有数据库图像进行排序。团队在三个知名数据集上评估了性能:Corel-1K、Corel-10K和Caltech-101,这些集合共同覆盖了自然场景、人造物体以及许多不同类别和图像条件。
新系统的性能表现如何
在这三个数据集上,CTD-Net持续优于仅依赖手工特征、仅依赖深度学习或较简单混合方法的系统。在Corel-1K上其精确率接近99%,在Corel-10K上超过92%,在更具挑战性的Caltech-101上接近89%。即使在返回更多查询结果或与许多近期研究方法比较时,这些提升也能保持。尽管混合特征维度更大且计算量更高,作者证明了搜索时间仍然在可接受范围内,尤其适用于对准确性要求较高的批量或服务器端应用。
这对日常图像搜索意味着什么
对非专业读者而言,要点是更智能的图像搜索正变得更像人类识别图片的方式。通过将直接的颜色与纹理测量与更深层次的学习理解相结合,CTD-Net能够找到在视觉上真正看起来和感觉上与查询照片相似的图像,而不仅仅是共享某个关键词的图像。这可能加速诸如查找相似医学影像、匹配艺术品或历史照片,或改进在线商店中的商品搜索等任务。作者指出,未来的工作可将相同思路扩展到更大规模的集合和新型图像,从而让视觉搜索更快、更准确且更值得信赖。
引用: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
关键词: 基于内容的图像检索, 图像搜索, 深度学习, 图像特征, 视觉相似性