Clear Sky Science · he
שיפור משיכת תמונות מבוססת-תוכן באמצעות שילוב צבע, מרקם ותכונות למידה עמוקה
מדוע חשוב למצוא את התמונה הנכונה
מסריקות רפואיות ועד תמונות חופשה, חיינו מוצפים בתמונות. ובכל זאת, למצוא את התמונה הנדרשת באוסף עצום יכול להיות מאתגר באופן מפתיע. במחקר זה מוצג CTD-Net, שיטה חדשה שמאפשרת למחשבים לחפש בבסיסי תמונות גדולים על ידי בחינת מה שבתמונה עצמה במקום להסתמך רק על תיאורים או שמות קבצים. העבודה מראה כיצד שילוב של ניתוח תמונה קלאסי עם למידה עמוקה מודרנית יכול להפוך חיפוש חזותי למדויק ושימושי יותר בהקשרים מעשיים. 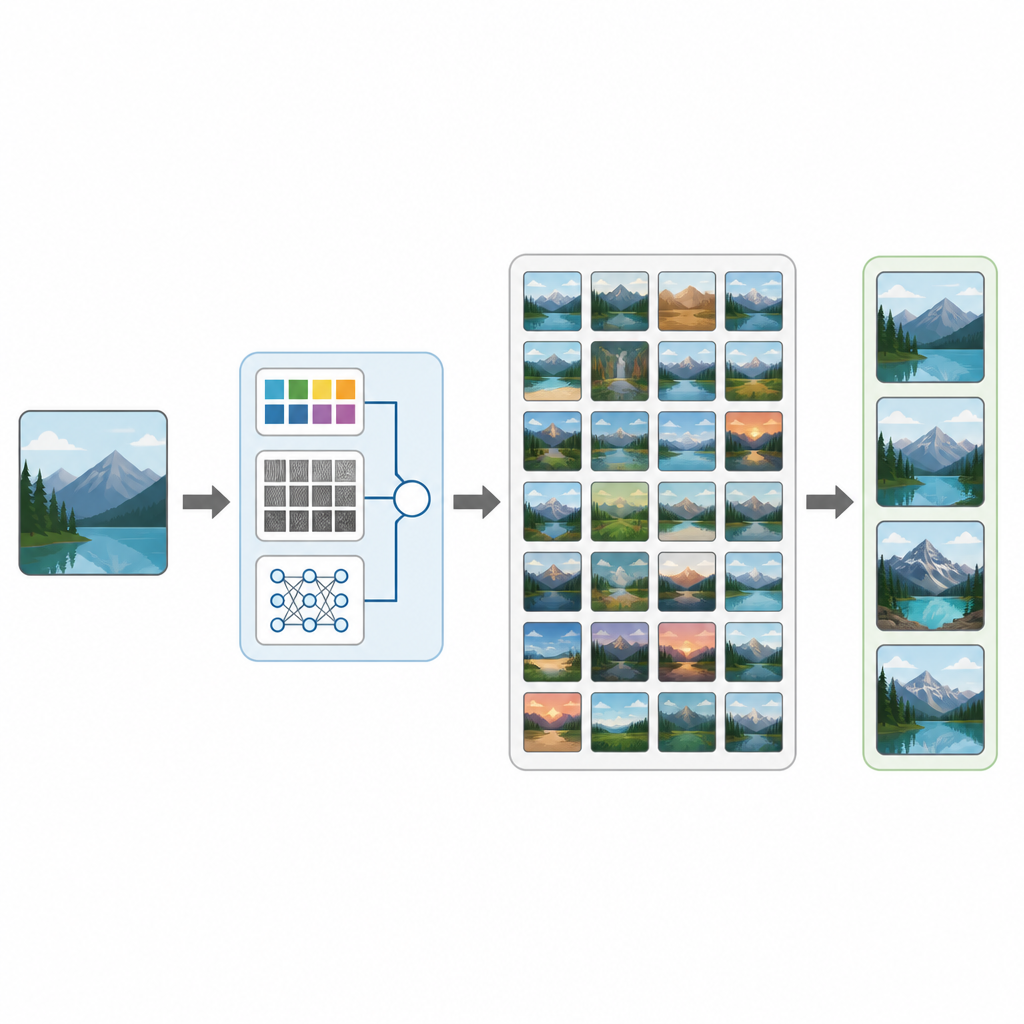
כיצד מחשבים בדרך כלל מחפשים תמונות
כלי חיפוש תמונות מוקדמים הסתמכו על טקסט שמוזן בידי אדם כגון כיתובים ומילות מפתח. גישה זו איטית, יקרה ולעתים קרובות לא שלמה, שכן אנשים שונים מתארים את אותה סצנה באופן שונה. משיכת תמונות מבוססת-תוכן משנה את הכללים בכך שהיא מאפשרת למחשב לבחון צבעים, צורות ומרקמים בתוך כל תמונה. עם זאת, מערכות רבות קיימות עדיין לא מספקות לסצנות מורכבות. נוסחאות פשוטות לצבע או למרקם עלולות לפספס פרטים חשובים, בעוד שמודלים של למידה עמוקה טהורה עשויים להזדקק למאגרי נתונים עצומים ולעיתים קשה לפרש את החלטותיהם. התוצאה היא פער בין מה שהמחשב רואה כמספרים לבין מה שאנשים מזהים כתוכן משמעותי.
שילוב רמזים פשוטים מהתמונה עם למידה עמוקה
CTD-Net מתמודד עם הפער הזה על ידי שילוב שני סוגי רמזים מכל תמונה. תחילה הוא מחלץ תכונות מעשה ידי אדם שמתארות תכונות חזותיות בסיסיות. היסטוגרמות צבע ורגעי צבע מסכמות כיצד הגוונים מפוזרים בתמונה, בעוד שהמרחבים של טרנספורמציות גלים ודוגמות בינאריות מקומיות (LBP) תופסים דפוסי מרקם קלים וקצוות. שנית, המערכת מטפלת באותה תמונה ברשת עמוקה ומתקדמת בשם EfficientNet-B7, שלומדת דפוסים מופשטים יותר כגון חלקי חפצים ופריסות מורכבות. כל האותות הללו מסולקים בקנה מידה מתאים וממוזגים לוקטור תכונה ארוך אחד שתופס גם הופעה פשוטה וגם משמעות סצנתית עשירה יותר. 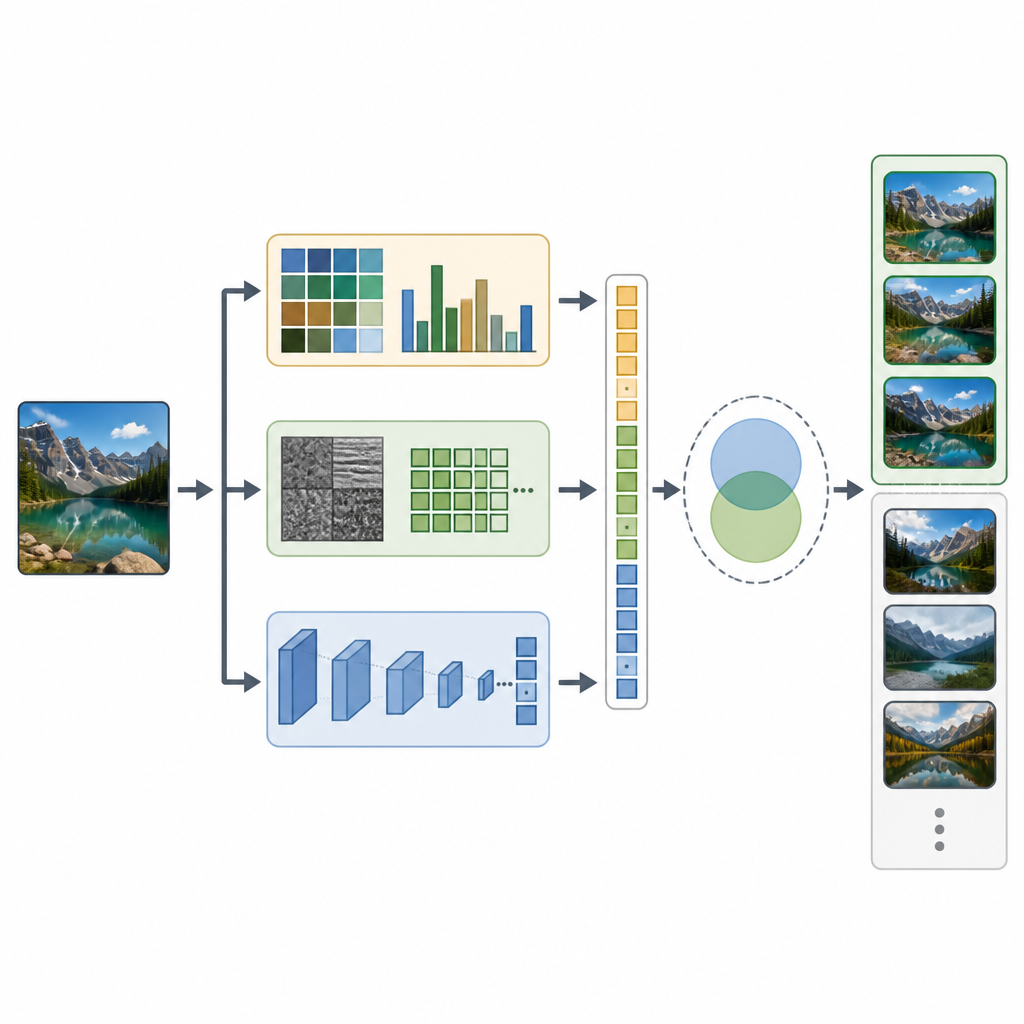
הפיכת תכונות לתוצאות חיפוש טובות יותר
לאחר שלכל תמונה יש טביעת אצבע משולבת, CTD-Net מודד עד כמה שתי טביעות אצבע דומות זו לזו. המחברים בדקו מספר שיטות מתמטיות להשוואה ומצאו כי דמיון קוסינוס סיפק את ההתאמות האמינות ביותר. בפועל, המשתמש מגיש תמונת שאילתה, CTD-Net ממיר אותה לתכונות, ואז מדורגות כל תמונות מסד הנתונים לפי קרבת וקטורי התכונה שלהן. הצוות העריך את הביצועים על שלושה אוספים ידועים: Corel-1K, Corel-10K ו-Caltech-101, שמכסים יחד סצנות טבעיות, חפצים מעשה ידי אדם וריבוי קטגוריות ותנאי תמונה.
כמה טוב המערכת החדשה מתפקדת
בכל שלושת מערכי הנתונים, CTD-Net עקף בעקביות מערכות שהתבססו אך ורק על תכונות מעשה ידי אדם, אך ורק על למידה עמוקה, או על היברידים פשוטים יותר. היא השיגה ערכי דיוק קרובים ל-99 אחוז ב-Corel-1K, מעל 92 אחוז ב-Corel-10K וכמעט 89 אחוז במערך המאתגר יותר Caltech-101. השיפורים הללו נשמרו גם כאשר הוחזרו תוצאות רבות יותר לכל שאילתה וכאשר השוו עם שיטות מחקריות רבות עדכניות. אף על פי שהתכונות ההיברידיות גדולות יותר ודרוש חישוב רב יותר, המחברים מראים שזמני החיפוש נותרו מעשיים, במיוחד לשימוש אצווה או על שרתים שבהם הדיוק קריטי.
מה משמעות הדבר לחיפוש תמונות יומיומי
לאדם שאינו מומחה, המסר הוא שחיפוש תמונות חכם יותר נעשה דומה יותר לאופן שבו בני אדם מזהים תמונות. על ידי שילוב מדידות צבע ומרקם פשוטות עם הבנה עמוקה נלמדת, CTD-Net יכול למצוא תמונות שנראות ומרגישות באמת דומות לתמונת השאילתה, לא רק כאלו שמשתפות מילה מפתח. זה יכול להאיץ משימות כגון מציאת סריקות רפואיות דומות, התאמת יצירות אמנות או תמונות היסטוריות, או שיפור חיפוש מוצרים בחנויות מקוונות. המחברים מציעים שעבודות עתידיות יכולות להתאים את הרעיון לאוספים גדולים יותר ולסוגי תמונות חדשים, מה שיהפוך את החיפוש הוויזואלי למהיר יותר, מדויק יותר וקל יותר לאמון.
ציטוט: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
מילות מפתח: משיכת תמונות מבוססת-תוכן, חיפוש תמונות, למידה עמוקה, תכונות תמונה, דמיון חזותי