Clear Sky Science · fr
Recherche d'images par contenu améliorée grâce à des caractéristiques hybrides de couleur, texture et apprentissage profond
Pourquoi trouver la bonne image compte
Des scanners médicaux aux photos de vacances, notre vie est inondée d’images. Pourtant, il peut être étonnamment difficile de retrouver la photo dont on a besoin dans une énorme collection. Cette étude présente CTD-Net, une nouvelle méthode pour permettre aux ordinateurs de rechercher dans de larges bases d’images en examinant directement le contenu des images plutôt qu’en se fiant uniquement aux étiquettes ou aux noms de fichiers. Le travail montre comment le mélange d’analyses d’images classiques et de l’apprentissage profond moderne peut rendre la recherche visuelle à la fois plus précise et plus utile en situation réelle. 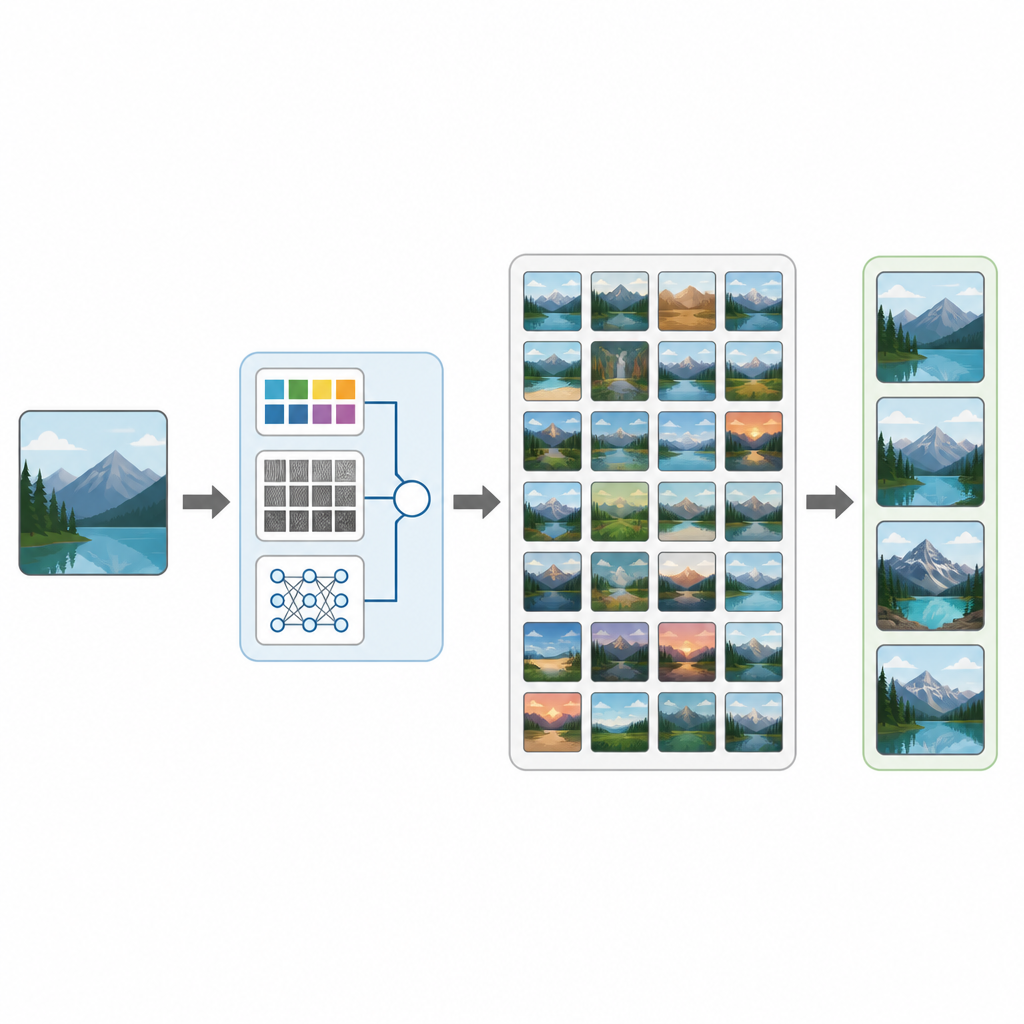
Comment les ordinateurs parcourent habituellement les images
Les premiers outils de recherche d’images dépendaient de textes ajoutés par des humains, tels que des légendes et des mots-clés. Cette approche est lente, coûteuse et souvent incomplète, car différentes personnes décrivent la même scène de manières différentes. La recherche d’images par contenu change la donne en permettant à l’ordinateur d’examiner les couleurs, formes et textures à l’intérieur de chaque image. Cependant, de nombreux systèmes existants restent insuffisants pour les scènes complexes. Des formules simples de couleur ou de texture peuvent manquer des détails importants, tandis que les modèles purement basés sur l’apprentissage profond peuvent nécessiter d’énormes jeux de données et être parfois difficiles à interpréter. Il en résulte un fossé entre ce que l’ordinateur perçoit sous forme de nombres et ce que les humains reconnaissent comme un contenu significatif.
Allier indices visuels simples et apprentissage profond
CTD-Net comble ce fossé en combinant deux types d’indices extraits de chaque image. D’abord, il extrait des caractéristiques « handcrafted » qui décrivent des propriétés visuelles de base. Les histogrammes de couleur et les moments de couleur résument la répartition des teintes dans l’image, tandis que les transformées en ondelettes et les motifs binaires locaux capturent les textures fines et les contours. Ensuite, le système envoie la même image dans un puissant réseau neuronal profond appelé EfficientNet-B7, qui apprend des motifs plus abstraits tels que des parties d’objets et des agencements complexes. Tous ces signaux sont soigneusement mis à l’échelle et fusionnés en un vecteur de caractéristiques long qui capture à la fois l’apparence simple et la signification plus riche de la scène. 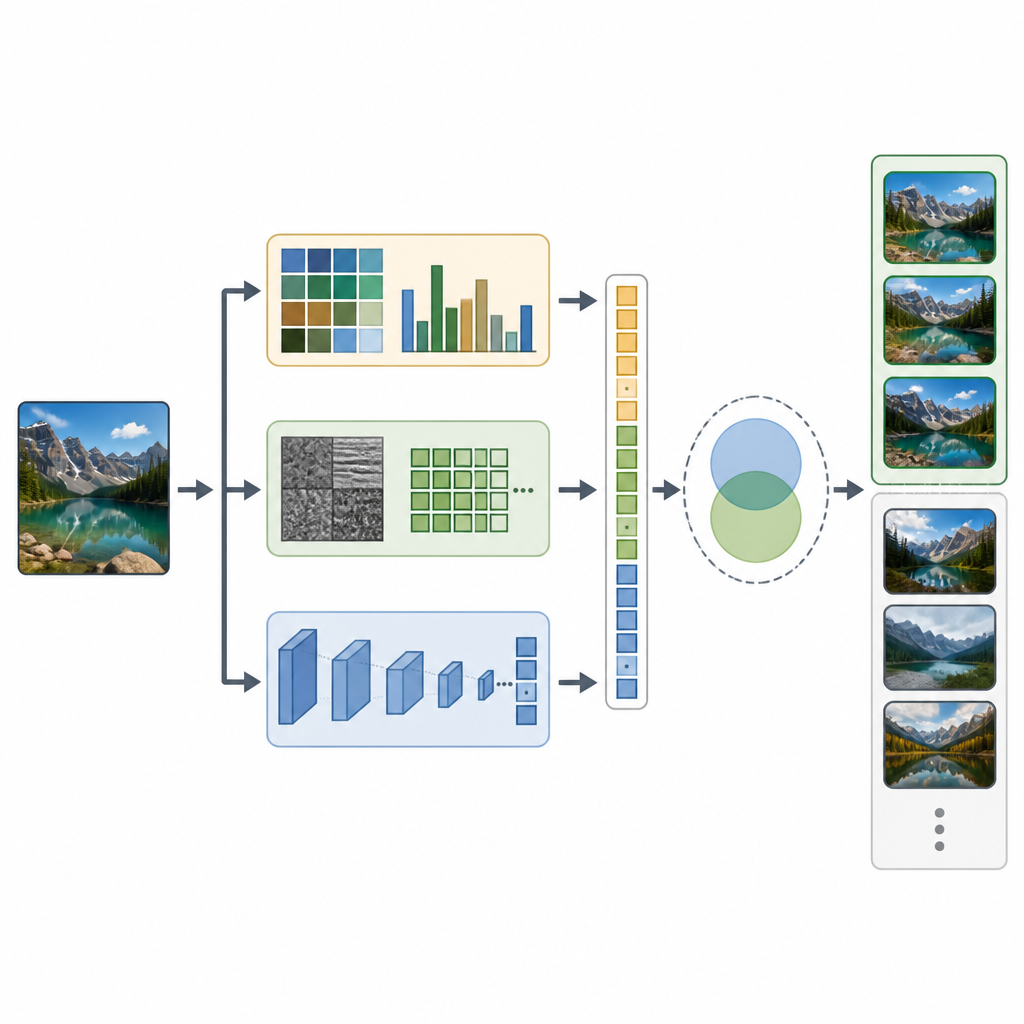
Transformer les caractéristiques en meilleurs résultats de recherche
Une fois que chaque image possède son empreinte combinée, CTD-Net mesure la similarité entre deux empreintes. Les auteurs ont testé plusieurs méthodes mathématiques pour les comparer et ont constaté que la similarité cosinus offrait les correspondances les plus fiables. En pratique, un utilisateur soumet une image requête, CTD-Net la convertit en caractéristiques, puis classe toutes les images de la base en fonction de la proximité de leurs vecteurs de caractéristiques. L’équipe a évalué les performances sur trois collections bien connues : Corel-1K, Corel-10K et Caltech-101, qui couvrent ensemble des scènes naturelles, des objets fabriqués par l’homme et de nombreuses catégories et conditions d’image différentes.
Quelle est la performance du nouveau système
Sur les trois ensembles de données, CTD-Net a systématiquement surperformé les systèmes basés uniquement sur des caractéristiques manuelles, uniquement sur l’apprentissage profond, ou sur des hybrides plus simples. Il a atteint des valeurs de précision proches de 99 % sur Corel-1K, supérieures à 92 % sur Corel-10K, et près de 89 % sur l’ensemble plus exigeant Caltech-101. Ces gains se sont maintenus même lorsque davantage de résultats étaient renvoyés par requête et en comparaison avec de nombreuses méthodes récentes de la recherche. Bien que les caractéristiques hybrides soient plus volumineuses et nécessitent plus de calcul, les auteurs montrent que les temps de recherche restent pratiques, en particulier pour des usages par lots ou serveur où la précision est cruciale.
Ce que cela signifie pour la recherche d’images quotidienne
Pour un non-spécialiste, le message est que la recherche d’images plus intelligente se rapproche de la manière dont les humains reconnaissent les images. En mélangeant des mesures simples de couleur et de texture avec une compréhension plus profonde apprise, CTD-Net peut retrouver des images qui ressemblent vraiment et correspondent au ressenti d’une photo requête, et pas seulement celles qui partagent un mot-clé. Cela pourrait accélérer des tâches telles que la recherche d’examens médicaux similaires, la mise en correspondance d’œuvres d’art ou de photos historiques, ou le raffinement de la recherche de produits dans les boutiques en ligne. Les auteurs suggèrent que des travaux futurs pourraient adapter cette idée à des collections encore plus vastes et à de nouveaux types d’images, rendant la recherche visuelle plus rapide, plus précise et plus facile à appréhender.
Citation: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
Mots-clés: recherche d'images par contenu, recherche d'images, apprentissage profond, caractéristiques d'image, similarité visuelle