Clear Sky Science · es
Recuperación de imágenes basada en contenido mejorada mediante características híbridas de color, textura y aprendizaje profundo
Por qué encontrar la imagen correcta importa
Desde exploraciones médicas hasta fotos de vacaciones, nuestras vidas están saturadas de imágenes. Sin embargo, localizar la imagen exacta que necesitamos dentro de una colección enorme puede ser sorprendentemente difícil. Este estudio presenta CTD-Net, una nueva forma para que los ordenadores busquen en grandes bases de datos de imágenes mirando directamente el contenido de la imagen en lugar de depender solo de etiquetas o nombres de archivo. El trabajo muestra cómo la mezcla del análisis clásico de imágenes con el aprendizaje profundo moderno puede hacer que la búsqueda visual sea más precisa y más útil en escenarios del mundo real. 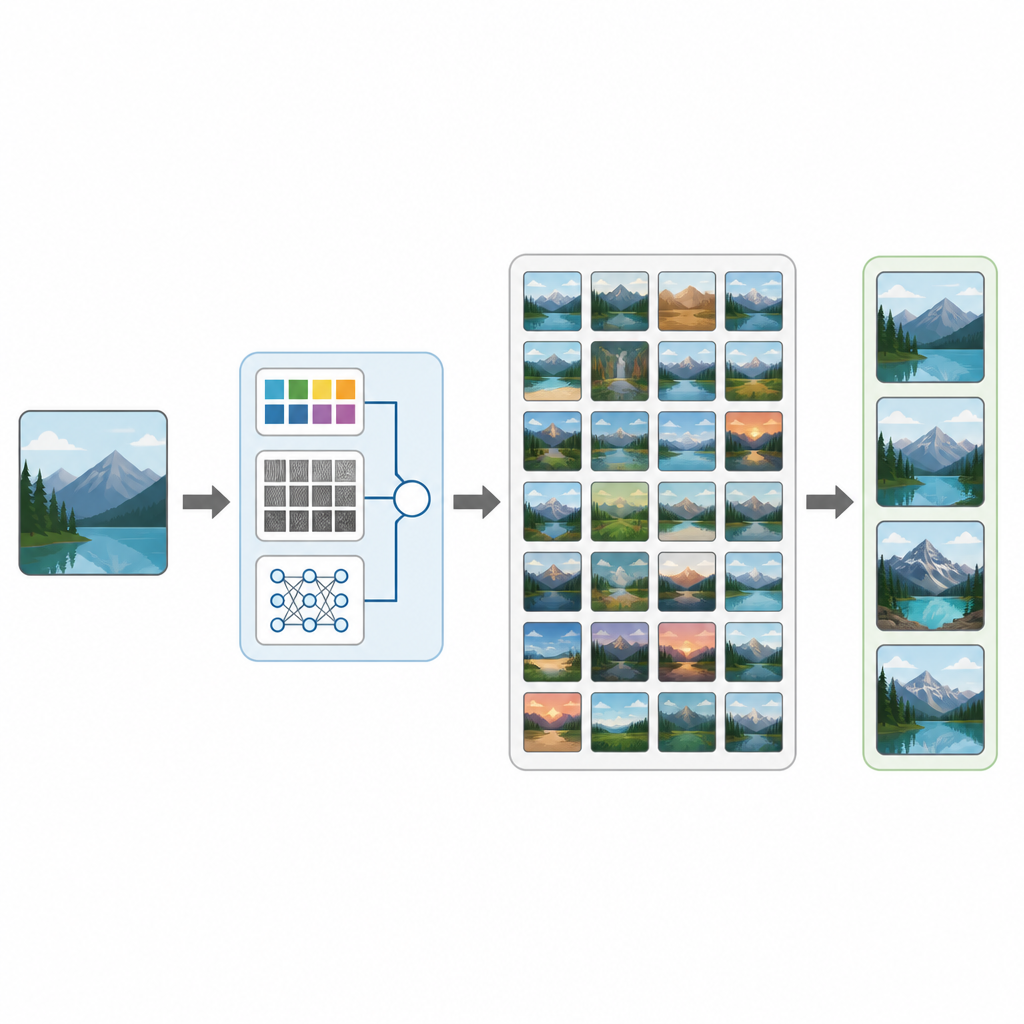
Cómo suelen buscar los ordenadores entre imágenes
Las primeras herramientas de búsqueda de imágenes dependían de texto añadido por personas, como subtítulos y palabras clave. Ese enfoque es lento, costoso y a menudo incompleto, ya que distintas personas describen la misma escena de maneras diferentes. La recuperación de imágenes basada en contenido cambia las reglas al permitir que el ordenador analice colores, formas y texturas dentro de cada imagen. Sin embargo, muchos sistemas existentes siguen siendo insuficientes para escenas complejas. Fórmulas simples de color o textura pueden pasar por alto detalles importantes, mientras que los modelos puramente de aprendizaje profundo pueden necesitar conjuntos de datos enormes y a veces son difíciles de interpretar. El resultado es una brecha entre lo que el ordenador ve como números y lo que las personas reconocen como contenido significativo.
Combinando pistas básicas de la imagen con aprendizaje profundo
CTD-Net aborda esta brecha combinando dos tipos de pistas de cada imagen. En primer lugar, extrae características diseñadas a mano que describen propiedades visuales básicas. Los histogramas de color y los momentos de color resumen cómo se distribuyen los tonos en la imagen, mientras que las transformadas wavelet y los patrones binarios locales capturan patrones finos de textura y bordes. En segundo lugar, el sistema introduce la misma imagen en una potente red neuronal profunda llamada EfficientNet-B7, que aprende patrones más abstractos como partes de objetos y disposiciones complejas. Todas estas señales se escalan y fusionan cuidadosamente en un único vector de características largo que captura tanto la apariencia simple como un significado de escena más rico. 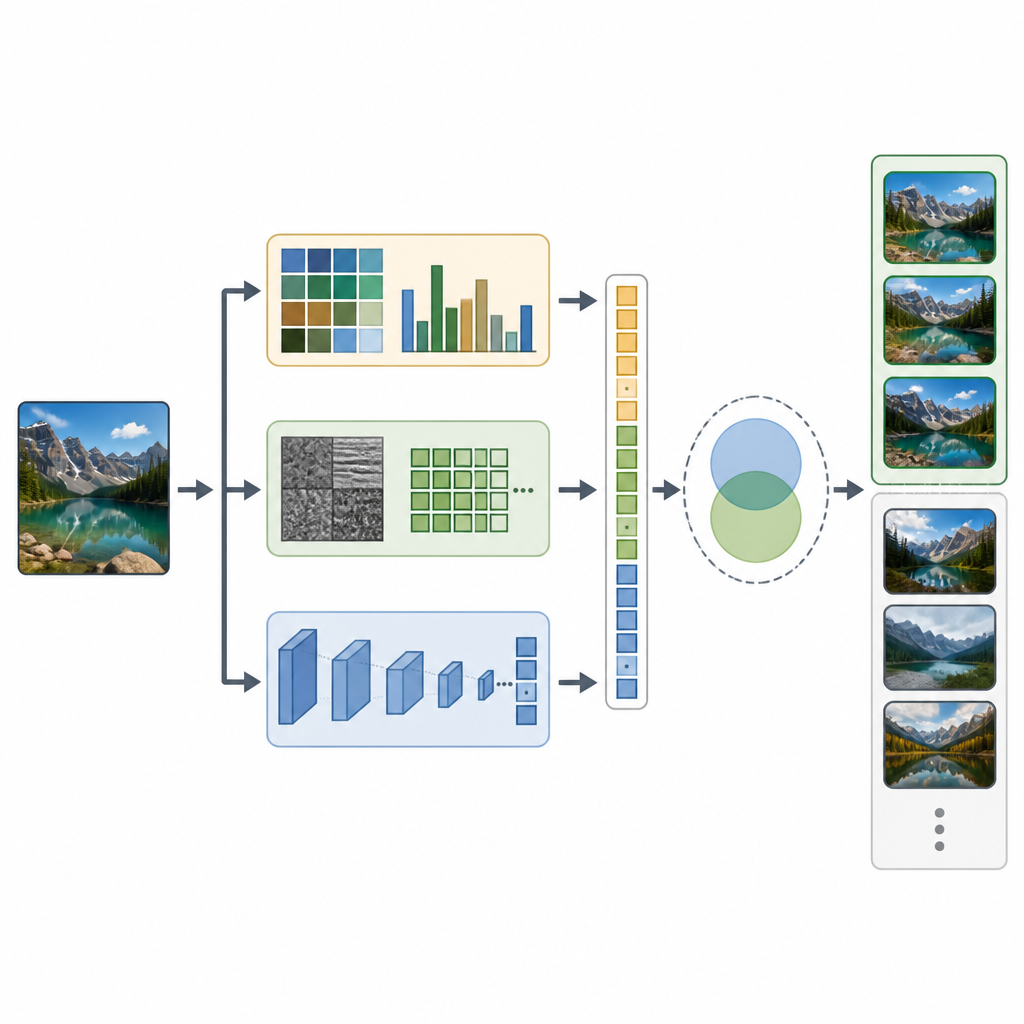
Convertir características en mejores resultados de búsqueda
Una vez que cada imagen tiene su huella combinada, CTD-Net mide cuán similares son dos huellas cualquiera. Los autores probaron varias formas matemáticas de compararlas y hallaron que la similitud coseno proporcionaba las coincidencias más fiables. En la práctica, un usuario envía una imagen de consulta, CTD-Net la convierte en características y luego ordena todas las imágenes de la base de datos en función de la cercanía de sus vectores de características. El equipo evaluó el rendimiento en tres colecciones bien conocidas: Corel-1K, Corel-10K y Caltech-101, que en conjunto cubren escenas naturales, objetos fabricados por el hombre y muchas categorías y condiciones de imagen diferentes.
Qué tan bien funciona el nuevo sistema
En los tres conjuntos de datos, CTD-Net superó de forma consistente a los sistemas basados solo en características diseñadas a mano, solo en aprendizaje profundo o en híbridos más sencillos. Alcanzó valores de precisión cercanos al 99 por ciento en Corel-1K, por encima del 92 por ciento en Corel-10K y casi el 89 por ciento en el conjunto más desafiante Caltech-101. Estas mejoras se mantuvieron incluso cuando se devolvían más resultados por consulta y al compararlo con muchos métodos de investigación recientes. Aunque las características híbridas son más grandes y requieren más cálculo, los autores muestran que los tiempos de búsqueda siguen siendo prácticos, especialmente para uso por lotes o en servidores donde la precisión es crucial.
Qué significa esto para la búsqueda de imágenes cotidiana
Para un público no especialista, el mensaje es que la búsqueda de imágenes más inteligente se está acercando a la forma en que los humanos reconocen las imágenes. Al combinar medidas sencillas de color y textura con una comprensión más profunda aprendida, CTD-Net puede encontrar imágenes que realmente se parecen y se sienten similares a una foto de consulta, no solo aquellas que comparten una palabra clave. Esto podría acelerar tareas como encontrar exploraciones médicas similares, emparejar obras de arte o fotos históricas, o refinar la búsqueda de productos en tiendas en línea. Los autores sugieren que trabajos futuros podrían adaptar la misma idea a colecciones aún mayores y a nuevos tipos de imágenes, haciendo la búsqueda visual más rápida, más precisa y más fácil de confiar.
Cita: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
Palabras clave: recuperación de imágenes basada en contenido, búsqueda de imágenes, aprendizaje profundo, características de imagen, similitud visual