Clear Sky Science · pl
Ulepszone wyszukiwanie obrazów oparte na treści dzięki hybrydowym cechom koloru, tekstury i uczenia głębokiego
Dlaczego znalezienie właściwego zdjęcia ma znaczenie
Od skanów medycznych po zdjęcia z wakacji — nasze życie jest zalane obrazami. Tymczasem odnalezienie tego jednego potrzebnego zdjęcia w ogromnej kolekcji bywa zaskakująco trudne. W tym badaniu wprowadzono CTD-Net, nowe podejście pozwalające komputerom przeszukiwać duże bazy obrazów, analizując bezpośrednio zawartość obrazu zamiast polegać wyłącznie na tagach czy nazwach plików. Praca pokazuje, jak połączenie klasycznej analizy obrazu z nowoczesnym uczeniem głębokim może sprawić, że wyszukiwanie wizualne będzie zarówno dokładniejsze, jak i bardziej użyteczne w zastosowaniach praktycznych. 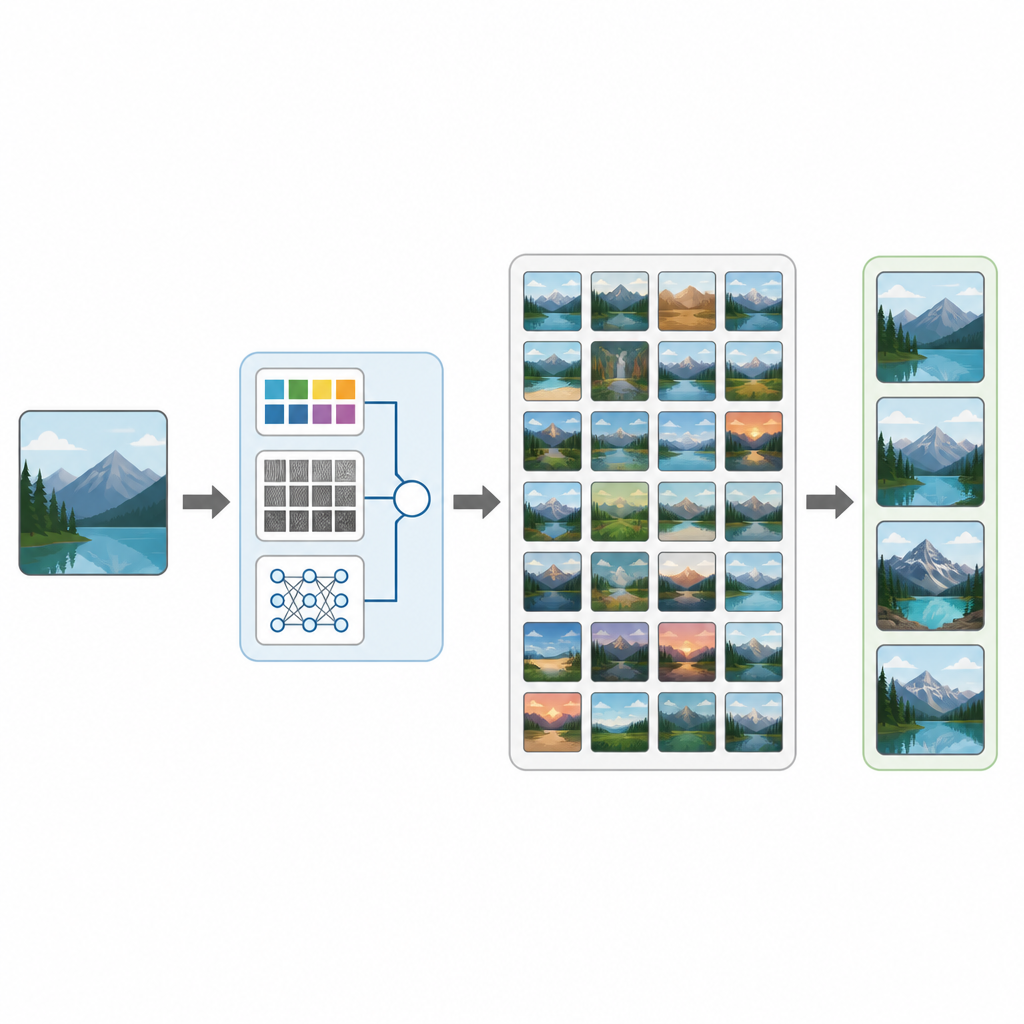
Jak komputery zwykle przeszukują obrazy
Wczesne narzędzia do wyszukiwania obrazów opierały się na tekstach dodawanych przez ludzi, takich jak podpisy i słowa kluczowe. To podejście jest wolne, kosztowne i często niepełne, ponieważ różni ludzie opisują tę samą scenę w odmienny sposób. Wyszukiwanie obrazów oparte na treści zmienia zasady gry, pozwalając komputerowi analizować kolory, kształty i tekstury wewnątrz każdego obrazu. Jednak wiele istniejących systemów nadal nie radzi sobie złożonymi scenami. Proste formuły koloru czy tekstury mogą pominąć istotne szczegóły, podczas gdy czyste modele głębokiego uczenia mogą wymagać ogromnych zbiorów danych i bywać trudne do interpretacji. Efektem jest luka między tym, co komputer widzi jako liczby, a tym, co ludzie rozpoznają jako treść o znaczeniu.
Łączenie prostych wskazówek obrazu z uczeniem głębokim
CTD-Net wypełnia tę lukę, łącząc dwa rodzaje wskazówek z każdego obrazu. Po pierwsze, wydobywa cechy stworzone ręcznie, opisujące podstawowe właściwości wizualne. Histogramy kolorów i momenty kolorów podsumowują rozkład odcieni w obrazie, podczas gdy transformaty faletowe i lokalne wzorce binarne (LBP) wychwytują drobne wzory tekstury i krawędzie. Po drugie, system wprowadza ten sam obraz do potężnej sieci neuronowej EfficientNet-B7, która uczy się bardziej abstrakcyjnych wzorców, takich jak części obiektów i złożone układy sceny. Wszystkie te sygnały są starannie skalowane i łączone w jeden długi wektor cech, który uchwyca zarówno prosty wygląd, jak i bogatsze znaczenie sceny. 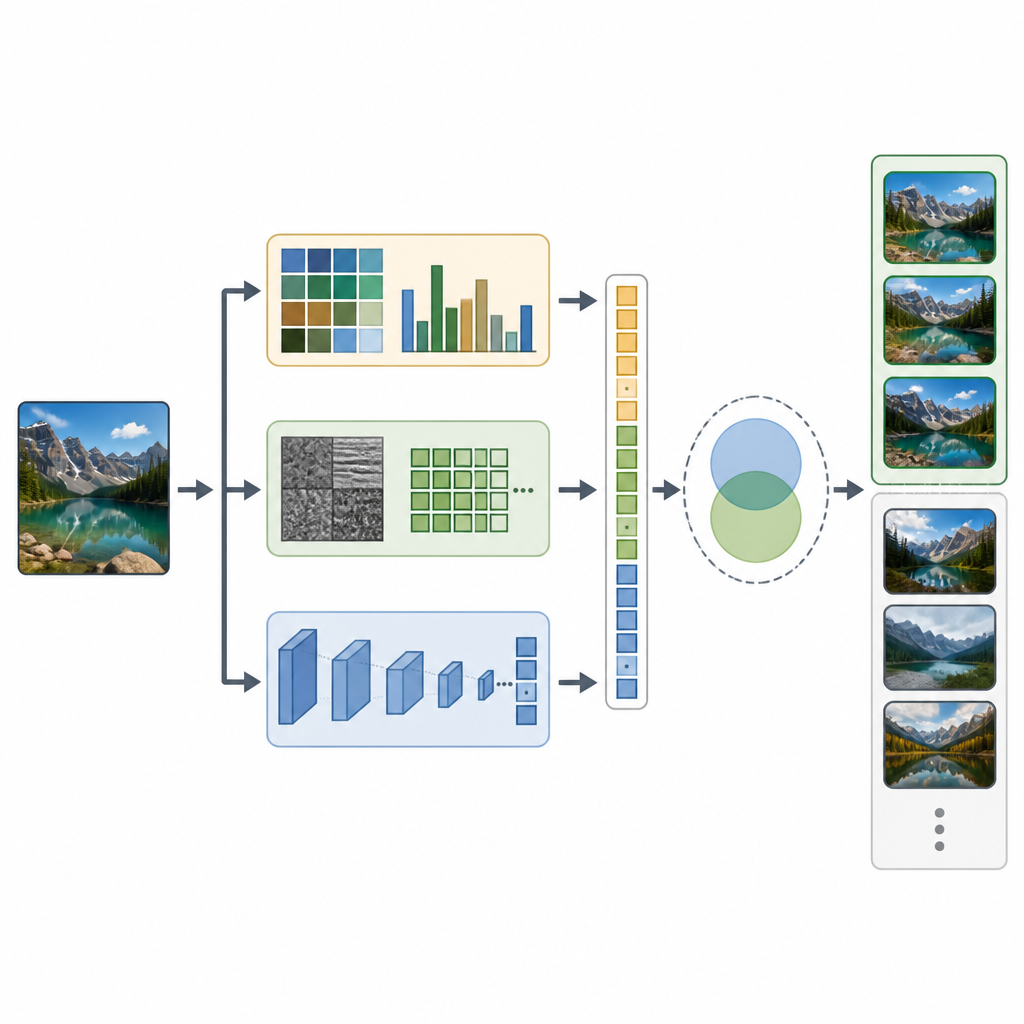
Przekształcanie cech w lepsze wyniki wyszukiwania
Gdy każdy obraz ma już połączony odcisk palca, CTD-Net mierzy, jak podobne są dowolne dwa odciski. Autorzy przetestowali kilka matematycznych metod porównywania i stwierdzili, że podobieństwo kosinusowe dawało najbardziej wiarygodne dopasowania. W praktyce użytkownik przesyła obraz zapytania, CTD-Net konwertuje go na cechy, a następnie porządkuje wszystkie obrazy w bazie według bliskości ich wektorów cech. Zespół ocenił wydajność na trzech dobrze znanych zbiorach: Corel-1K, Corel-10K i Caltech-101, które razem obejmują sceny naturalne, obiekty tworzone przez człowieka oraz wiele różnych kategorii i warunków obrazów.
Jak dobrze działa nowy system
We wszystkich trzech zbiorach CTD-Net konsekwentnie przewyższał systemy oparte wyłącznie na cechach ręcznie zdefiniowanych, wyłącznie na uczeniu głębokim lub na prostszych hybrydach. Osiągnął wartości precyzji bliskie 99 procent na Corel-1K, ponad 92 procent na Corel-10K i niemal 89 procent na trudniejszym zbiorze Caltech-101. Te zyski utrzymywały się nawet wtedy, gdy zwracano więcej wyników na zapytanie i w porównaniu z wieloma niedawnymi metodami badawczymi. Chociaż hybrydowe cechy są większe i wymagają więcej obliczeń, autorzy pokazują, że czasy wyszukiwania pozostają praktyczne, szczególnie w zastosowaniach wsadowych lub serwerowych, gdzie kluczowa jest dokładność.
Co to oznacza dla codziennego wyszukiwania obrazów
Dla osób niebędących specjalistami przesłanie jest takie, że inteligentniejsze wyszukiwanie obrazów staje się coraz bardziej podobne do tego, jak ludzie rozpoznają zdjęcia. Poprzez łączenie prostych pomiarów koloru i tekstury z głębszym, wyuczonym rozumieniem, CTD-Net może znaleźć obrazy, które naprawdę wyglądają i sprawiają wrażenie podobnych do zdjęcia zapytania, a nie tylko tych, które dzielą słowo kluczowe. Może to przyspieszyć zadania takie jak wyszukiwanie podobnych skanów medycznych, dopasowywanie dzieł sztuki lub zdjęć historycznych czy ulepszenie wyszukiwania produktów w sklepach internetowych. Autorzy sugerują, że przyszłe prace mogłyby zaadaptować ten sam pomysł do jeszcze większych kolekcji i nowych typów obrazów, czyniąc wyszukiwanie wizualne szybszym, dokładniejszym i łatwiejszym do zaufania.
Cytowanie: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
Słowa kluczowe: wyszukiwanie obrazów oparte na treści, wyszukiwanie obrazów, uczenie głębokie, cechy obrazu, podobieństwo wizualne