Clear Sky Science · ar
استرجاع الصور المعتمد على المحتوى محسن عبر مزج ميزات اللون والملمس والتعلم العميق
لماذا العثور على الصورة المناسبة مهم
من الفحوصات الطبية إلى صور العطلات، حياتنا تغمرها الصور. ومع ذلك، يمكن أن يكون العثور على الصورة التي نحتاجها داخل مجموعة ضخمة أمراً أكثر صعوبة مما يبدو. تقدم هذه الدراسة CTD-Net، طريقة جديدة للحواسيب للبحث في قواعد بيانات الصور الكبيرة عبر النظر مباشرة إلى محتوى الصورة بدلاً من الاعتماد فقط على الوسوم أو أسماء الملفات. يوضح العمل كيف أن مزج تحليل الصور التقليدي مع التعلم العميق الحديث يمكن أن يجعل البحث البصري أكثر دقة وأكثر فائدة في حالات العالم الحقيقي. 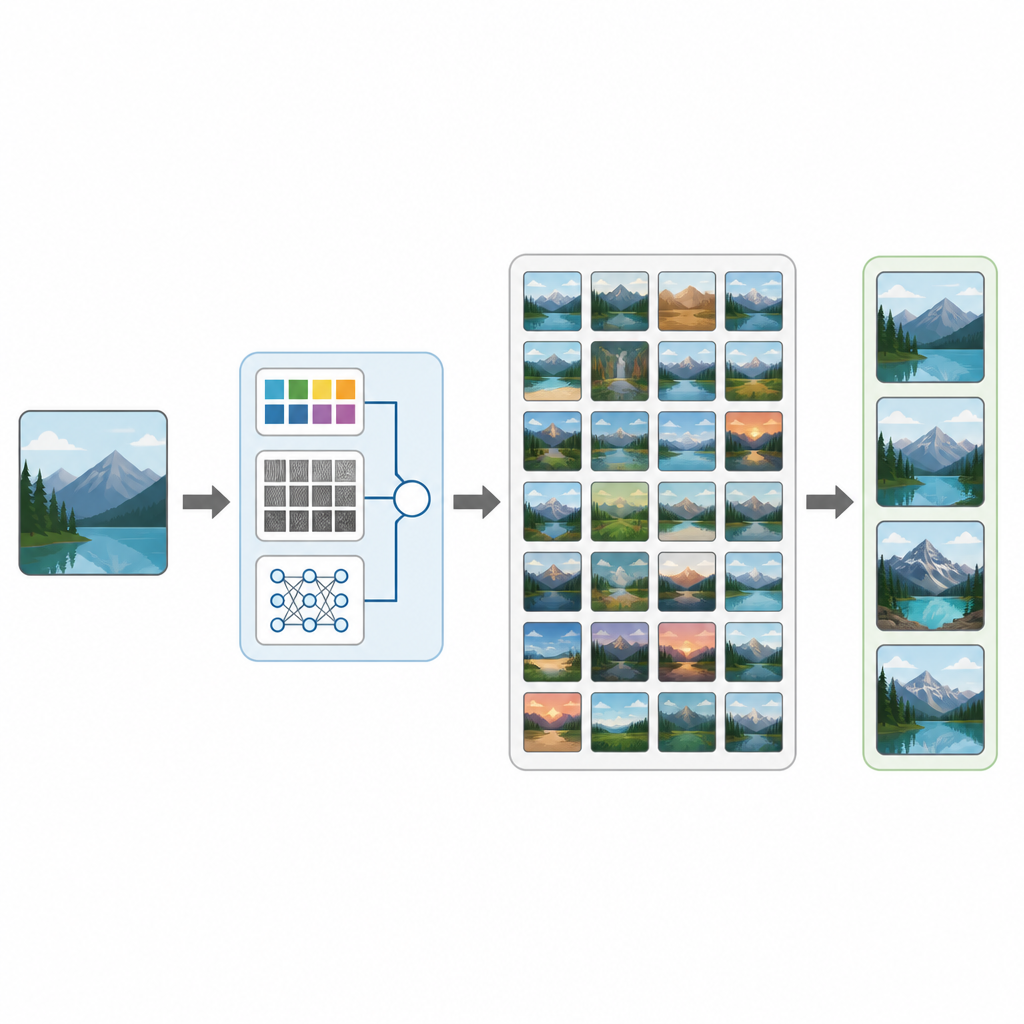
كيف تبحث الحواسيب عن الصور عادةً
كانت أدوات البحث عن الصور المبكرة تعتمد على النص الذي يضيفه البشر مثل العناوين والكلمات المفتاحية. هذا النهج بطيء ومكلف وغالباً ما يكون غير كامل، لأن أشخاصاً مختلفين يصفون المشهد نفسه بطرق مختلفة. يغير استرجاع الصور المعتمد على المحتوى قواعد اللعبة بتمكين الحاسوب من النظر إلى الألوان والأشكال والأنسجة داخل كل صورة. ومع ذلك، لا تزال العديد من الأنظمة الحالية قاصرة في المشاهد المعقدة. يمكن أن تغفل صيغ اللون أو الملمس البسيطة عن تفاصيل مهمة، بينما قد تحتاج نماذج التعلم العميق الخالصة إلى مجموعات بيانات هائلة وتكون أحياناً صعبة التفسير. النتيجة هي فجوة بين ما تراه الحواسيب كأرقام وما يتعرف عليه البشر كمحتوى ذي معنى.
مزج دلائل الصورة البسيطة مع التعلم العميق
يتصدى CTD-Net لهذه الفجوة من خلال دمج نوعين من الأدلة المستخرجة من كل صورة. أولاً، يستخرج ميزات مصممة يدوياً تصف الخصائص البصرية الأساسية. تلخص تكرارات الألوان ولحظات اللون كيف توزع الظلال عبر الصورة، بينما تلتقط تحويلات المويجات ونماذج الثنائيات المحلية أنماط النسيج الدقيقة والحواف. ثانياً، يُدخل النظام نفس الصورة في شبكة عصبية عميقة قوية تدعى EfficientNet-B7، التي تتعلم أنماطاً أكثر تجريداً مثل أجزاء الكائنات والتركيبات المعقدة للمشهد. تُوزن كل هذه الإشارات وتُدمَج بعناية في متجه ميزة واحد طويل يلتقط المظهر البسيط والمعنى المشهدي الأعمق. 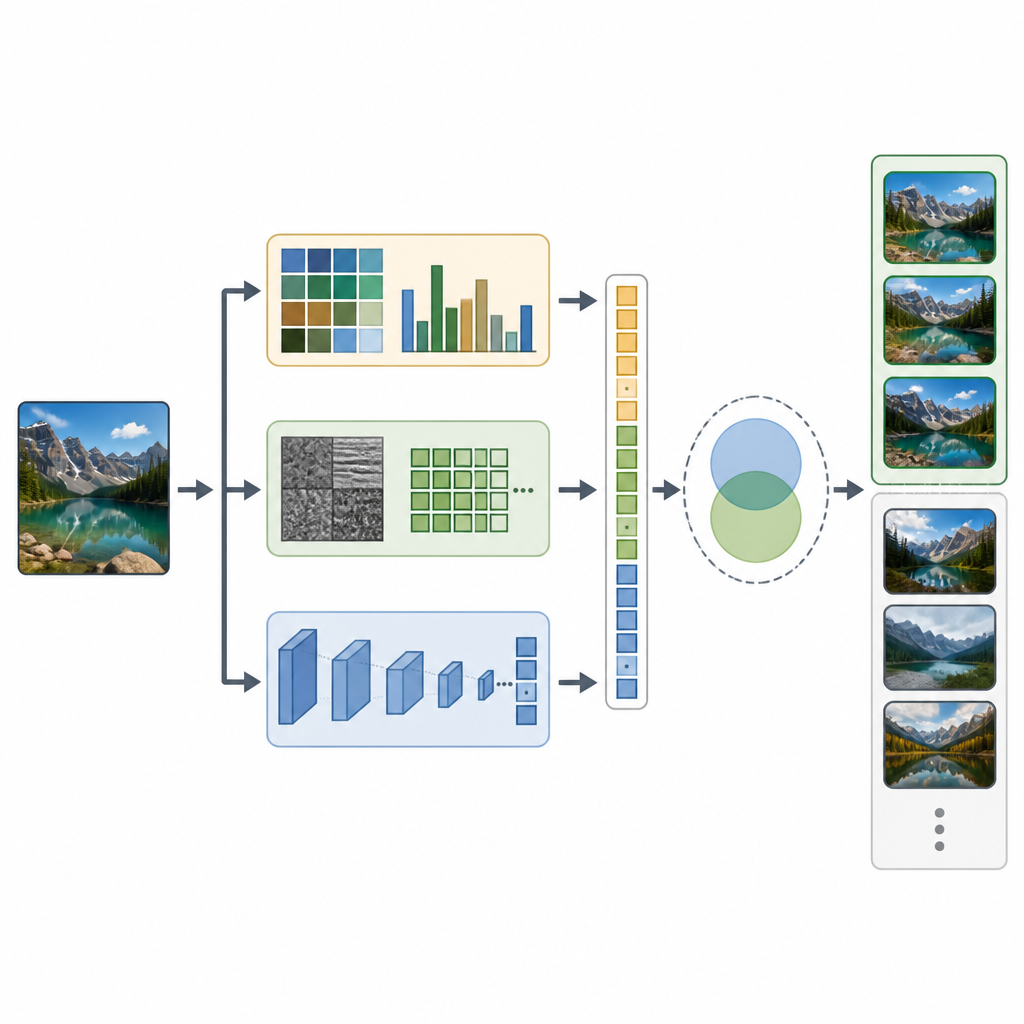
تحويل الميزات إلى نتائج بحث أفضل
بمجرد أن يحصل كل صورة على بصمتها المدمجة، يقيس CTD-Net مدى تشابه أي بصمتين. اختبر المؤلفون عدة طرق رياضية للمقارنة ووجدوا أن متجه التشابه الكوني (cosine similarity) أعطى التطابقات الأكثر موثوقية. عملياً، يقدّم المستخدم صورة استعلام، يقوم CTD-Net بتحويلها إلى ميزات، ثم يرتب جميع صور قاعدة البيانات بناءً على مدى قرب متجهات الميزات. قيّم الفريق الأداء على ثلاث مجموعات معروفة: Corel-1K و Corel-10K و Caltech-101، التي تغطي مجتمعة المشاهد الطبيعية والكائنات من صنع الإنسان والعديد من الفئات وظروف الصور المختلفة.
مدى أداء النظام الجديد
عبر المجموعات الثلاث كلها، تفوق CTD-Net باستمرار على الأنظمة المبنية فقط على ميزات مصممة يدوياً أو فقط على التعلم العميق أو على الهايبردات الأبسط. وصل إلى قيم دقة تقارب 99 بالمئة على Corel-1K، وفوق 92 بالمئة على Corel-10K، وقرب 89 بالمئة على مجموعة Caltech-101 الأكثر تحدياً. استمرت هذه الزيادة حتى عند إرجاع نتائج أكثر لكل استعلام وعند المقارنة بالعديد من أساليب البحث الحديثة. وعلى الرغم من أن الميزات الهجينة أكبر وتتطلب مزيداً من الحوسبة، يُظهر المؤلفون أن أزمنة البحث تظل عملية، لا سيما في الاستخدامات الدفعية أو الخادمات حيث تكون الدقة حاسمة.
ما الذي يعنيه هذا لبحث الصور اليومي
بالنسبة لغير المختصين، الرسالة هي أن البحث الذكي عن الصور يصبح أكثر تشابهاً مع طريقة تعرف البشر على الصور. من خلال مزج قياسات اللون والملمس المباشرة مع فهم أعمق متعلم، يمكن لـ CTD-Net العثور على صور تشبه شكلاً ومضموناً صورة الاستعلام، وليس فقط تلك التي تشترك في كلمة مفتاحية. قد يسرّع هذا مهام مثل العثور على فحوصات طبية مشابهة، أو مطابقة الأعمال الفنية أو الصور التاريخية، أو تحسين بحث المنتجات في المتاجر الإلكترونية. يقترح المؤلفون أن العمل المستقبلي قد يكيّف نفس الفكرة لمجموعات أكبر ونوعيات جديدة من الصور، مما يجعل البحث البصري أسرع وأكثر دقة وأسهل في الوثوق به.
الاستشهاد: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
الكلمات المفتاحية: استرجاع الصور المعتمد على المحتوى, بحث الصور, التعلم العميق, ميزات الصورة, التشابه البصري