Clear Sky Science · it
Recupero di immagini basato sul contenuto migliorato tramite caratteristiche combinate di colore, texture e deep learning
Perché trovare l'immagine giusta è importante
Da esami medici a foto di vacanza, le nostre vite sono invase dalle immagini. Eppure individuare l'immagine di cui abbiamo bisogno in una grande raccolta può essere sorprendentemente difficile. Questo studio introduce CTD-Net, un nuovo approccio che permette ai computer di cercare in grandi banche dati di immagini guardando direttamente cosa c'è nella foto invece di basarsi soltanto su tag o nomi di file. Il lavoro mostra come la fusione dell'analisi d'immagine classica con il deep learning moderno possa rendere la ricerca visiva più accurata e più utile in contesti reali. 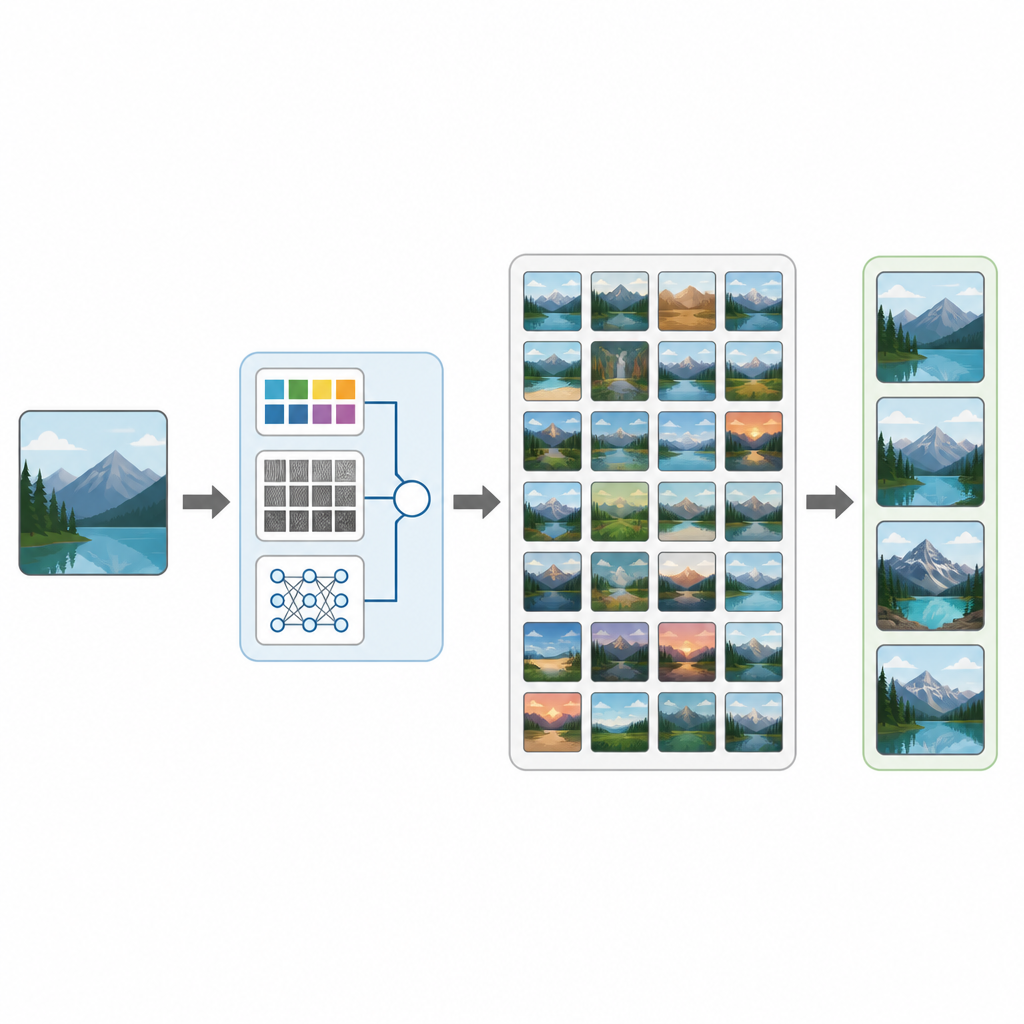
Come i computer solitamente cercano nelle immagini
I primi strumenti di ricerca d'immagini dipendevano dal testo aggiunto dall'uomo, come didascalie e parole chiave. Quel metodo è lento, costoso e spesso incompleto, perché persone diverse descrivono la stessa scena in modi differenti. Il recupero di immagini basato sul contenuto cambia le regole permettendo al computer di analizzare colori, forme e texture all'interno di ogni immagine. Tuttavia, molti sistemi esistenti restano insufficienti per scene complesse. Semplici formule di colore o texture possono trascurare dettagli importanti, mentre i modelli basati solo sul deep learning possono richiedere dataset molto grandi e risultare a volte difficili da interpretare. Il risultato è un divario tra ciò che il computer vede come valori numerici e ciò che le persone riconoscono come contenuto significativo.
Fondere indizi semplici con il deep learning
CTD-Net affronta questo divario combinando due tipi di indizi estratti da ogni immagine. Innanzitutto ricava caratteristiche costruite a mano che descrivono proprietà visive di base. Istogrammi di colore e momenti di colore riassumono come le tonalità sono distribuite nell'immagine, mentre trasformate wavelet e local binary patterns catturano strutture di texture fini e contorni. In secondo luogo, il sistema alimenta la stessa immagine in una potente rete neurale profonda chiamata EfficientNet-B7, che apprende pattern più astratti come parti di oggetti e disposizioni complesse della scena. Tutti questi segnali vengono scalati con cura e aggregati in un unico lungo vettore di caratteristiche che cattura sia l'aspetto semplice sia il significato più ricco della scena. 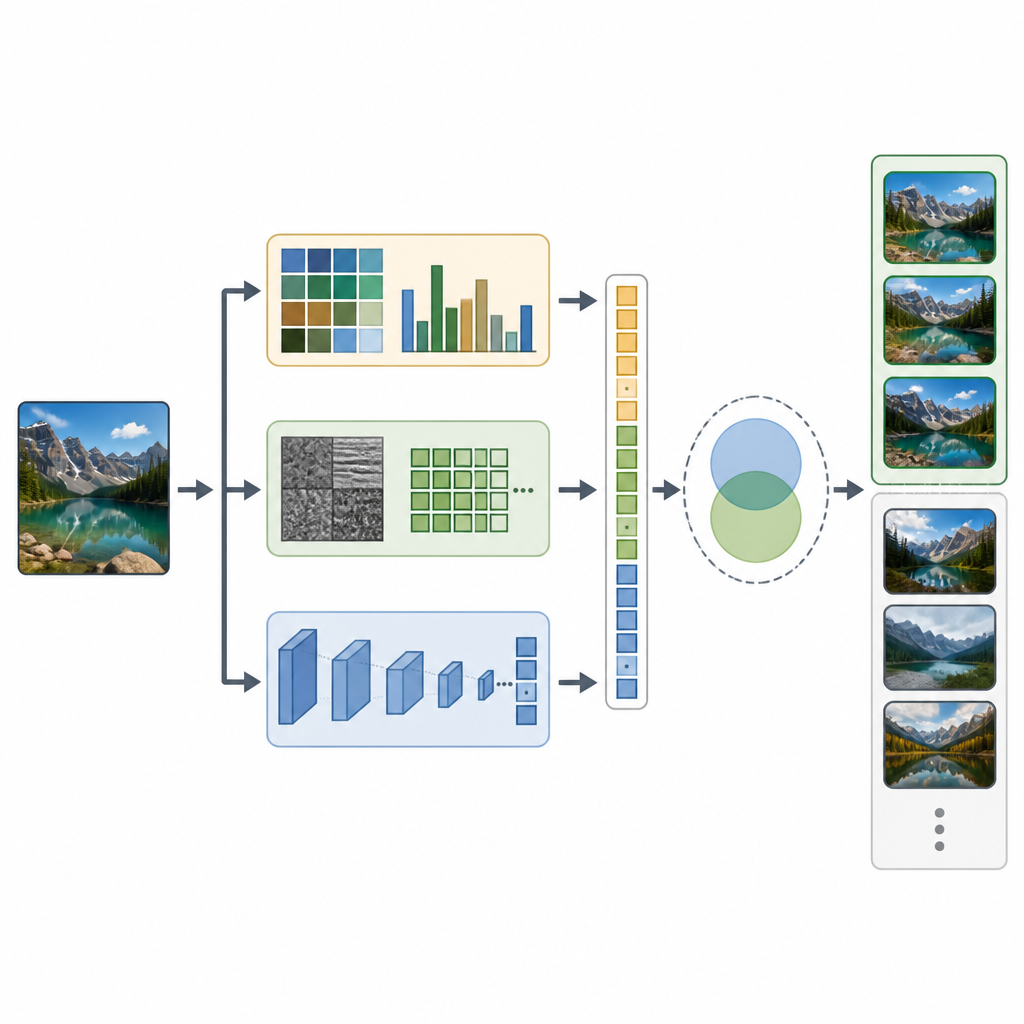
Trasformare le caratteristiche in risultati di ricerca migliori
Una volta che ogni immagine ha la propria impronta combinata, CTD-Net misura quanto siano simili due impronte tra loro. Gli autori hanno testato diversi metodi matematici per confrontarle e hanno scoperto che la similarità coseno forniva le corrispondenze più affidabili. In pratica, un utente invia un'immagine di query, CTD-Net la converte in caratteristiche e poi ordina tutte le immagini del database in base alla vicinanza dei loro vettori di caratteristiche. Il team ha valutato le prestazioni su tre collezioni note: Corel-1K, Corel-10K e Caltech-101, che insieme coprono scene naturali, oggetti artificiali e molte categorie e condizioni d'immagine diverse.
Quanto bene si comporta il nuovo sistema
Su tutti e tre i dataset, CTD-Net ha costantemente superato sistemi basati solo su caratteristiche costruite a mano, solo su deep learning o su ibridi più semplici. Ha raggiunto valori di precisione vicini al 99 percento su Corel-1K, oltre il 92 percento su Corel-10K e quasi l'89 percento sul più impegnativo Caltech-101. Questi miglioramenti si sono mantenuti anche restituendo un maggior numero di risultati per query e confrontando il sistema con molti metodi di ricerca recenti. Sebbene le caratteristiche ibride siano più ampie e richiedano maggior calcolo, gli autori dimostrano che i tempi di ricerca restano pratici, specialmente per utilizzi batch o su server dove l'accuratezza è fondamentale.
Cosa significa per la ricerca di immagini di tutti i giorni
Per un non specialista, il messaggio è che la ricerca di immagini più intelligente sta diventando più simile al modo in cui gli esseri umani riconoscono le immagini. Integrando misure semplici di colore e texture con una comprensione più profonda appresa, CTD-Net può trovare immagini che realmente appaiono e risultano simili a una foto di query, non solo quelle che condividono una parola chiave. Questo potrebbe velocizzare compiti come trovare esami medici simili, accoppiare opere d'arte o fotografie storiche, o perfezionare la ricerca di prodotti nei negozi online. Gli autori suggeriscono che lavori futuri potrebbero adattare la stessa idea a collezioni ancora più grandi e a nuovi tipi di immagini, rendendo la ricerca visiva più veloce, più accurata e più affidabile.
Citazione: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
Parole chiave: recupero di immagini basato sul contenuto, ricerca di immagini, deep learning, caratteristiche dell'immagine, somiglianza visiva