Clear Sky Science · ru
Улучшенный поиск изображений по содержанию с помощью гибридных цветовых, текстурных и глубоких признаков
Почему важно найти нужную картинку
От медицинских снимков до отпускных фотографий — наша жизнь заполнена изображениями. Тем не менее найти именно ту фотографию, которая нужна, в огромной коллекции бывает удивительно сложно. В этом исследовании представлена CTD-Net, новый способ для компьютеров выполнять поиск по большим базам изображений, анализируя непосредственно содержимое снимка, а не полагаясь только на теги или имена файлов. Работа показывает, как сочетание классического анализа изображений и современного глубокого обучения может сделать визуальный поиск более точным и практичным в реальных условиях. 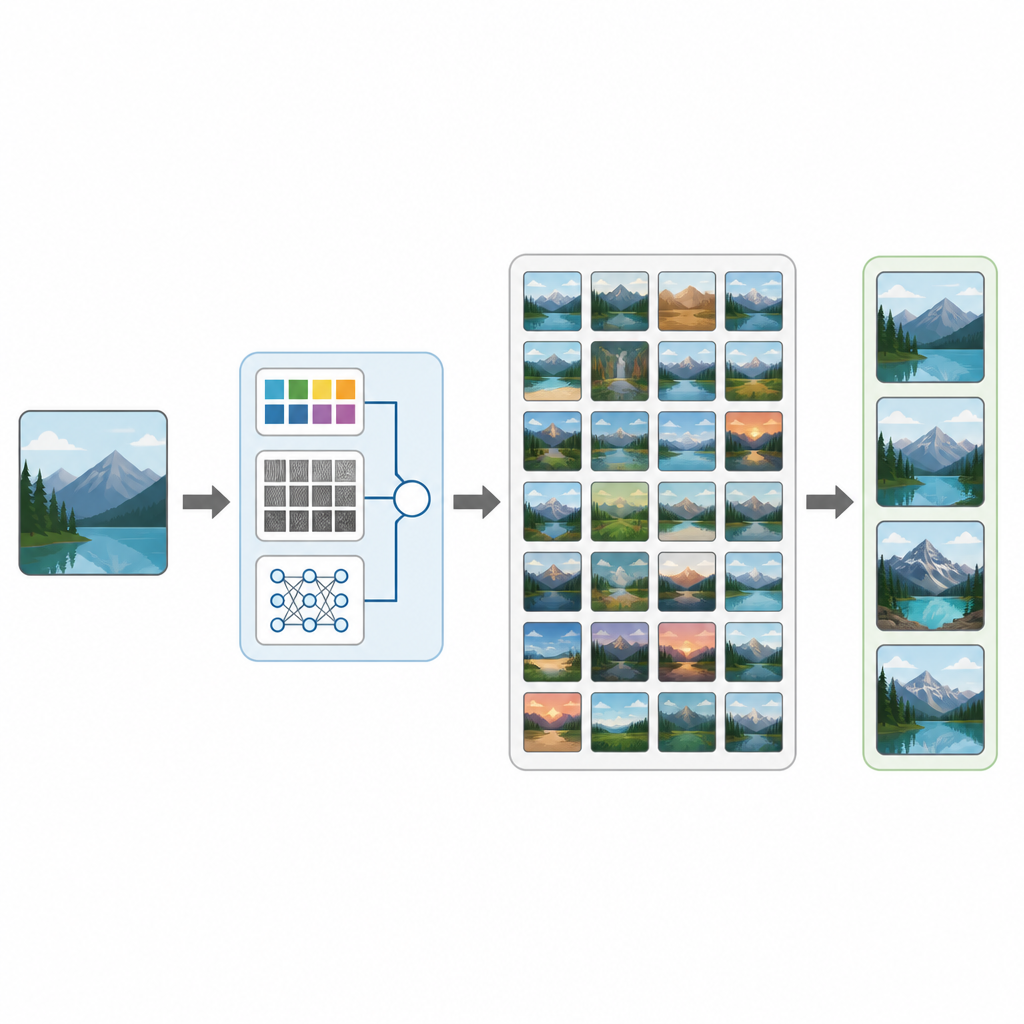
Как компьютеры обычно ищут изображения
Ранние инструменты поиска изображений опирались на текст, добавляемый людьми, такой как подписи и ключевые слова. Этот подход медленный, затратный и часто неполный, поскольку разные люди по‑разному описывают одну и ту же сцену. Поиск изображений по содержанию меняет правила игры, позволяя компьютеру анализировать цвета, формы и текстуры внутри каждого кадра. Однако многие существующие системы всё ещё не справляются со сложными сценами. Простые цветовые или текстурные формулы могут упускать важные детали, тогда как чистые модели глубокого обучения требуют огромных наборов данных и порой трудны для интерпретации. В итоге возникает разрыв между тем, что компьютер видит в виде чисел, и тем, что люди воспринимают как значимое содержание.
Сочетание простых подсказок изображения с глубоким обучением
CTD-Net устраняет этот разрыв, объединяя два типа признаков из каждого изображения. Во‑первых, извлекаются вручную сконструированные признаки, описывающие базовые визуальные свойства. Цветовые гистограммы и моменты цвета суммируют распределение оттенков по картинке, тогда как вейвлет‑преобразования и локальные бинарные шаблоны фиксируют тонкие текстурные паттерны и края. Во‑вторых, та же картинка подается в мощную глубокую нейросеть EfficientNet‑B7, которая обучается выделять более абстрактные паттерны, такие как части объектов и сложные композиции. Все эти сигналы аккуратно масштабируются и объединяются в единый длинный вектор признаков, фиксирующий как простую внешность, так и более богатое смысловое представление сцены. 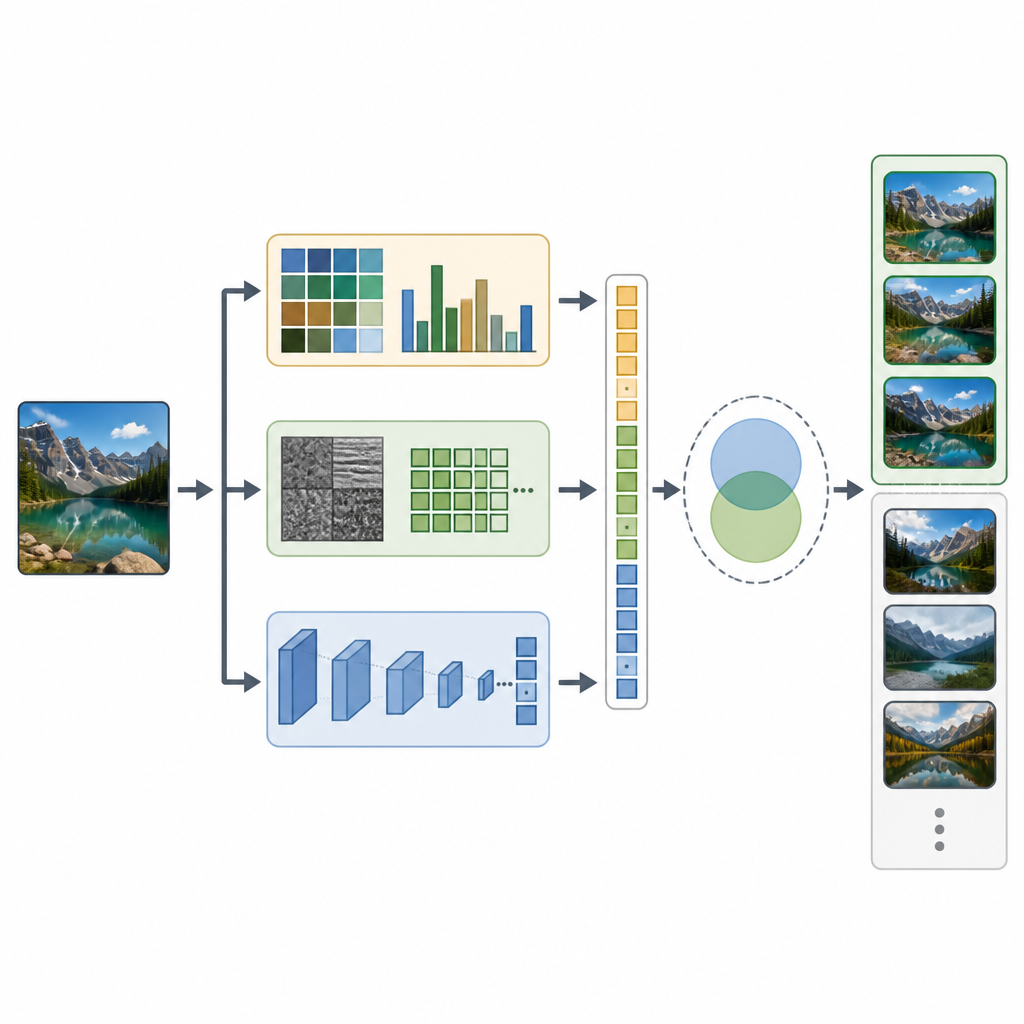
Преобразование признаков в более качественные результаты поиска
После того как для каждого изображения сформирован комбинированный «отпечаток», CTD‑Net измеряет сходство между любыми двумя отпечатками. Авторы протестировали несколько математических мер сравнения и выявили, что косинусное сходство даёт наиболее надежные совпадения. На практике пользователь отправляет изображение‑запрос, CTD‑Net конвертирует его в признаки и затем ранжирует все изображения базы по близости их векторов признаков. Команда оценивала производительность на трёх известных коллекциях: Corel‑1K, Corel‑10K и Caltech‑101, которые в совокупности покрывают природные сцены, искусственные объекты и множество категорий при различных условиях съёмки.
Насколько хорошо работает новая система
На всех трёх наборах данных CTD‑Net последовательно превосходил системы, основанные только на вручную сконструированных признаках, только на глубоких сетях или на более простых гибридах. Он достиг точности, близкой к 99 процентов на Corel‑1K, свыше 92 процентов на Corel‑10K и почти 89 процентов на более сложном наборе Caltech‑101. Эти улучшения сохранялись даже при увеличении числа возвращаемых результатов на запрос и при сравнении со многими современными исследовательскими методами. Хотя гибридные признаки больше по размеру и требуют больших вычислений, авторы показывают, что время поиска остаётся практичным, особенно при пакетной обработке или серверном использовании, где точность критична.
Что это означает для повседневного поиска изображений
Для неспециалиста вывод в том, что более умный поиск изображений становится ближе к тому, как люди распознают картинки. Смешивая прямолинейные измерения цвета и текстуры с более глубоким обученным пониманием, CTD‑Net может находить изображения, которые действительно выглядят и воспринимаются похожими на запрос, а не только те, что разделяют ключевое слово. Это может ускорить такие задачи, как поиск похожих медицинских снимков, сопоставление произведений искусства или исторических фотографий, а также уточнение поиска товаров в интернет‑магазинах. Авторы полагают, что в будущем эту же идею можно адаптировать к ещё большим коллекциям и новым типам изображений, делая визуальный поиск быстрее, точнее и более доверительным.
Цитирование: Tyagi, S., Shukla, P., Singh, P. et al. Enhanced content-based image retrieval via hybrid color, texture, and deep learning features. Sci Rep 16, 14888 (2026). https://doi.org/10.1038/s41598-026-38422-w
Ключевые слова: поиск изображений по содержанию, поиск изображений, глубокое обучение, признаки изображения, визуальное сходство