Clear Sky Science · zh
SynRXN:用于计算反应建模的开放基准与精心策划的数据集
为何更智能的化学数据至关重要
现代化学越来越依赖计算机来帮助设计新药物、材料和日常化学品。但即便是最先进的算法,其表现也取决于训练数据的质量。目前,反应数据分散在专利、论文和实验记录中,格式混乱且不一致,这使得难以判断不同计算工具是否真正带来了改进。本文介绍了 SynRXN——一个开放且经过精心策划的反应数据集与测试集合,旨在为研究者提供一个共同的评估平台,以衡量其方法在合成规划和理解化学反应方面的效果。
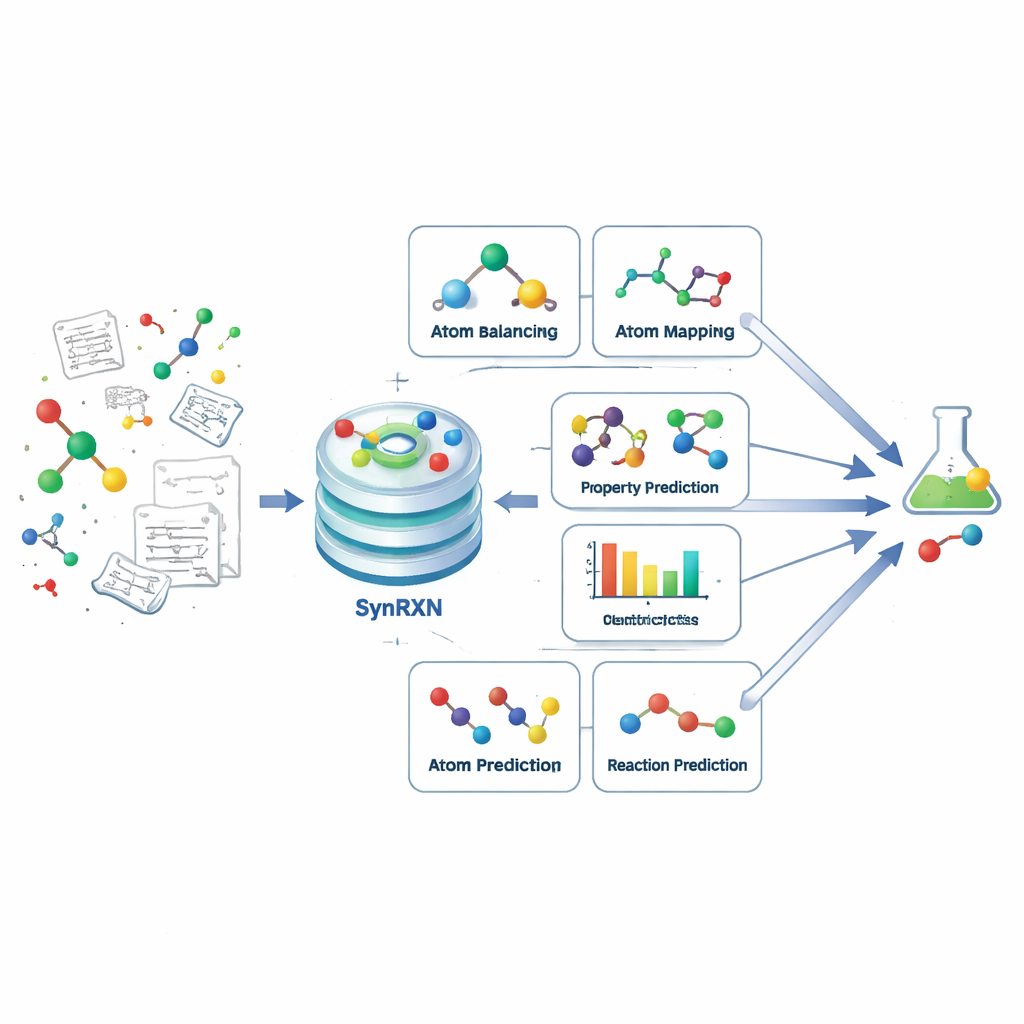
将复杂问题拆解为明确步骤
计算辅助合成规划旨在帮助化学家找出如何从更简单的构件出发合成目标分子。SynRXN 并不将其视为一个单一的整体挑战,而是将其分解为五类具体任务,反映了化学家在实际工作中的做法。首先是修复和补全反应记录(反应重平衡),接着是追踪单个原子如何从起始物迁移到产物(原子到原子映射),然后是将反应归类(反应分类),接着预测有用的数值性质,例如反应产率或能垒(反应性质预测),最后是预测在给定转化下可能的产物或起始物(合成预测)。通过为每一步定义精确的输入、输出和评估指标,SynRXN 将一条错综复杂的工作流程转化为一组良定的问题。
清理嘈杂的化学记录
现实世界的反应数据常常不完整:专利和电子实验记录可能省略溶剂、对离子或副产物,或列出不可能的原子计数。SynRXN 在其反应重平衡任务中通过采用广泛使用的专利来源数据集并有意构建带有特定类型错误的示例来应对这一点,例如缺失非碳原子或方程式一侧或双侧缺失成分。随后它使用规则和图形相结合的方法恢复平衡,仅保留置信度极高的修正,并手动验证最终测试集。在原子到原子映射方面,SynRXN 从多个可信来源收集有机和生化反应,并对其施加严格的自动化检查,以确保分子有效且表示一致,然后再比较不同映射工具如何追踪每个原子的命运。
将反应组织为类别与数字化指标
除了判断反应是否守衡,化学家还关心反应属于何种转化以及其性能如何。为此,SynRXN 组装了多层次的反应分类任务,范围从宽泛类别到机理上的细微差别,并包含来自专利的有机反应与生物学中的酶催化反应。它将这些标签与标准化的数据划分方案(训练、验证和测试集)以及一致的性能度量配对。对于数值目标,SynRXN 收集了文献和公共资料库中有关反应产率、能垒、速率及其他性质的数据集。所有数据都通过一致的清洗流程,且提供了简单的参考模型,用户可以快速判断新方法是否确实优于合理的基线。
让反应预测更公平且可复现
在合成预测任务中,SynRXN 关注单步反应,其中给定的反应物集合会生成一个或多个产物,或目标是从产物向后推断出合理的起始物。它打包了三个有影响力的、来自专利的语料库(许多团队已在使用),但以确定性、透明的划分和通用的评估脚本重新发布。在底层,所有 SynRXN 数据集遵循相同的表格结构,具有稳定的反应标识符、标准化的分子编码和明确的许可标签。机器可读的清单记录了文件位置、校验和、列名和计数,使任何人在另一台机器上或未来的某个时间点都能使用脚本化的构建配方重现相同的策划表格。
这对未来化学发现意味着什么
从实际角度看,SynRXN 并不引入新的预测模型;相反,它提供了比较现有与未来模型所需的框架。通过从多个来源统一反应数据、执行严格的质量检查并发布开放的、版本化的基准及参考结果,SynRXN 使研究者能够明确指出合成规划流水线中哪些部分运行良好、哪些存在问题。对于化学家和数据科学家而言,这意味着性能改进的主张可以基于共享测试而非定制且不透明的数据集,从而加速对真正有助于现实世界化学设计的计算工具的可靠进展。
引用: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
关键词: 计算辅助合成设计, 反应基准测试, 化学反应数据集, 化学领域的机器学习, 反应预测