Clear Sky Science · de
SynRXN: Ein offener Benchmark und kuratierter Datensatz für die computerbasierte Modellierung von Reaktionen
Warum bessere Chemiedaten wichtig sind
Die moderne Chemie verlässt sich zunehmend auf Computer, um neue Medikamente, Materialien und Alltagschemikalien zu entwerfen. Doch selbst die klügsten Algorithmen sind nur so gut wie die Daten, aus denen sie lernen. Heutige Reaktionsdaten liegen verstreut in Patenten, Fachartikeln und Laborbüchern in unübersichtlichen, inkonsistenten Formaten vor, was es schwierig macht zu beurteilen, ob konkurrierende Computerwerkzeuge tatsächlich Fortschritte bringen. Dieser Artikel stellt SynRXN vor, eine offene, sorgfältig kuratierte Sammlung von Reaktionsdatensätzen und Tests, die Forschenden ein gemeinsames Spielfeld bietet, um zu bewerten, wie gut ihre Methoden bei der Planung und dem Verständnis chemischer Synthesen funktionieren.
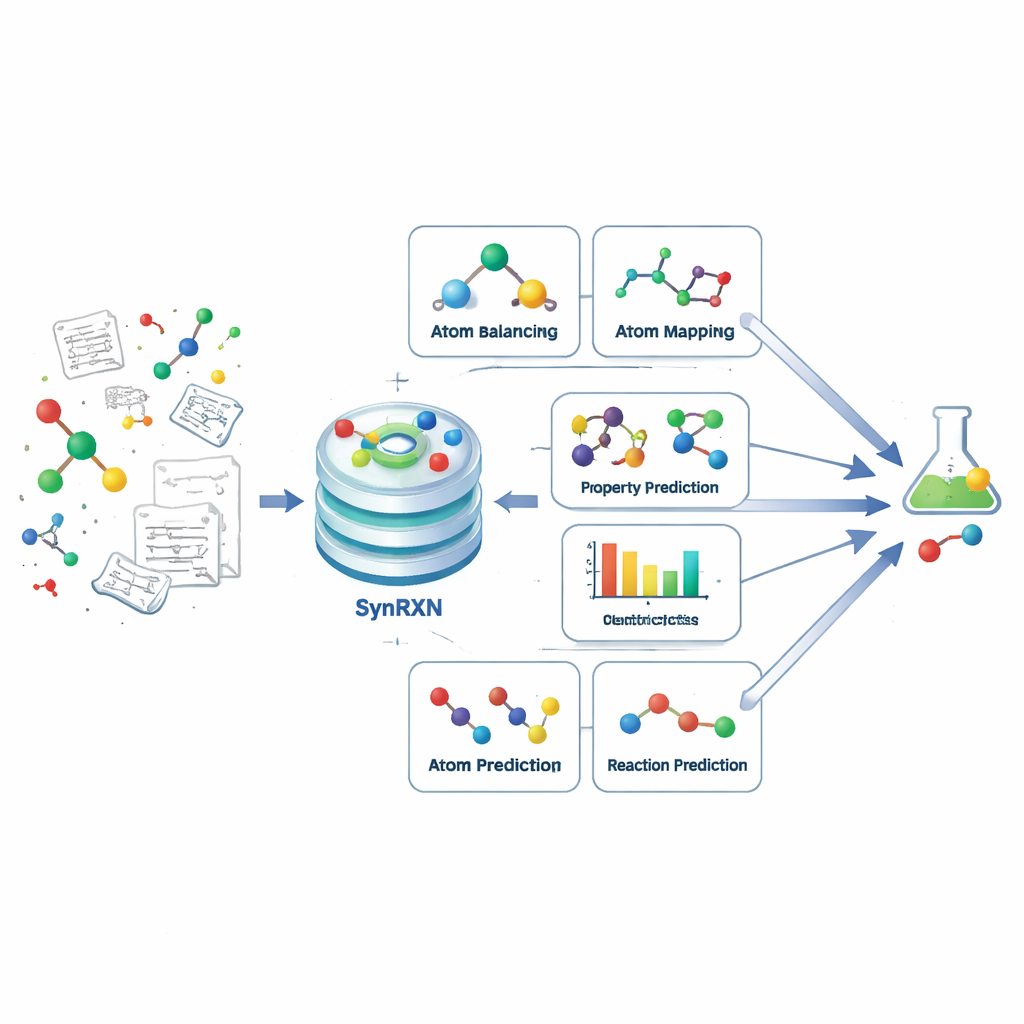
Ein komplexes Problem in klare Schritte zerlegen
Die computerunterstützte Syntheseplanung soll Chemikerinnen und Chemikern helfen, herauszufinden, wie ein Zielmolekül aus einfacheren Bausteinen hergestellt werden kann. Anstatt dies als eine einzige monolithische Aufgabe zu behandeln, zerlegt SynRXN sie in fünf konkrete Aufgabenfamilien, die dem praktischen Vorgehen von Chemikerinnen und Chemikern entsprechen. Zuerst folgt das Korrigieren und Vervollständigen von Reaktionsaufzeichnungen (Rebalancing), dann das Nachverfolgen, wie einzelne Atome sich von Ausgangsstoffen zu Produkten bewegen (Atom-zu-Atom-Mapping), anschließend die Zuordnung jeder Reaktion zu einer Kategorie (Reaktionsklassifikation), danach die Vorhersage nützlicher numerischer Eigenschaften wie Reaktionsausbeuten oder Energiebarrieren (Vorhersage von Reaktionseigenschaften) und schließlich die Prognose, welche Produkte oder Ausgangsmaterialien für eine gegebene Transformation wahrscheinlich sind (Synthesevorhersage). Durch die Definition präziser Eingaben, Ausgaben und Bewertungsmaße für jeden dieser Schritte verwandelt SynRXN einen verunklarten Workflow in eine Reihe wohlformulierter Probleme.
Rauschende chemische Aufzeichnungen bereinigen
Echte Reaktionsdaten sind oft unvollständig: Patente und elektronische Laborbücher lassen möglicherweise Lösungsmittel, Gegenionen oder Nebenprodukte weg oder listen unmögliche Atomzahlen auf. SynRXN geht dieses Problem in der Aufgabe des Rebalancing an, indem es auf weit verbreiteten, patentbasierten Datensätzen aufbaut und gezielt Beispiele mit bestimmten Fehlerarten konstruiert, etwa fehlende Nicht-Kohlenstoff-Atome oder Komponenten, die auf einer oder beiden Seiten der Gleichung fehlen. Anschließend verwendet es eine hybride Regel- und Graph-basierte Methode, um das Gleichgewicht wiederherzustellen, wobei nur Korrekturen mit sehr hoher Zuversicht übernommen und der finale Testsatz manuell verifiziert werden. Für das Atom-zu-Atom-Mapping sammelt SynRXN sowohl organische als auch biochemische Reaktionen aus mehreren vertrauenswürdigen Quellen und unterzieht sie strengen, automatisierten Prüfungen, um sicherzustellen, dass Moleküle gültig und konsistent repräsentiert sind, bevor verglichen wird, wie gut verschiedene Mapping-Tools das Schicksal jedes Atoms nachverfolgen.
Reaktionen in Klassen und Zahlen organisieren
Über die reine Frage hinaus, ob eine Reaktion ausgeglichen ist, interessiert Chemikerinnen und Chemiker, um welche Art von Transformation es sich handelt und wie gut sie performt. SynRXN stellt daher mehrere Ebenen von Reaktionsklassifikationsaufgaben zusammen, die von groben Kategorien bis hin zu feingranularen Unterschieden im Mechanismus reichen, und umfasst sowohl organische Reaktionen aus Patenten als auch enzymkatalysierte Reaktionen aus der Biologie. Diese Labels werden mit standardisierten Methoden kombiniert, um Daten in Trainings-, Validierungs- und Testsätze aufzuteilen, sowie mit vereinbarten Leistungskennzahlen. Für numerische Zielgrößen sammelt SynRXN Datensätze zu Reaktionsausbeuten, Energiebarrieren, Raten und anderen Eigenschaften aus der Literatur und öffentlichen Repositorien. Alle Datensätze durchlaufen eine konsistente Bereinigungspipeline, und einfache Referenzmodelle werden bereitgestellt, damit Nutzer schnell beurteilen können, ob eine neue Methode wirklich besser ist als eine sinnvolle Basislinie.
Reaktionsvorhersagen fair und reproduzierbar machen
Für die Aufgabe der Synthesevorhersage konzentriert sich SynRXN auf einstufige Reaktionen, bei denen eine gegebene Menge an Reaktanten zu einem oder mehreren Produkten führt, oder auf Fälle, in denen das Ziel darin besteht, von einem Produkt aus auf plausible Ausgangsmaterialien zurückzuschließen. Es bündelt drei einflussreiche, patentbasierte Korpora, die viele Gruppen bereits verwenden, exportiert sie jedoch mit deterministischen, transparenten Aufteilungen und gemeinsamen Evaluationsskripten neu. Unter der Haube folgen alle SynRXN-Datensätze derselben tabellarischen Struktur mit stabilen Reaktionskennungen, standardisierten Molekülkodierungen und expliziten Lizenzkennzeichen. Ein maschinenlesbares Manifest dokumentiert Dateistandorte, Prüfsummen, Spaltennamen und Counts, sodass jede*r die gleichen kuratierten Tabellen auf einem anderen Rechner oder zu einem späteren Zeitpunkt mithilfe skriptgesteuerter Build-Rezepte reproduzieren kann.
Was das für die zukünftige chemische Entdeckung bedeutet
Praktisch betrachtet führt SynRXN kein neues Vorhersagemodell ein; stattdessen liefert es das Gerüst, das nötig ist, um bestehende und zukünftige Modelle fair zu vergleichen. Durch die Harmonisierung von Reaktionsdaten aus vielen Quellen, das Erzwingen strenger Qualitätsprüfungen und die Veröffentlichung offener, versionierter Benchmarks mit Referenzergebnissen ermöglicht SynRXN Forschenden, genau zu identifizieren, welche Teile der Syntheseplanungspipeline gut funktionieren und wo sie versagen. Für Chemikerinnen und Chemiker ebenso wie für Data Scientists bedeutet das, dass Leistungsbehauptungen auf gemeinsamen Tests statt auf maßgeschneiderten, undurchsichtigen Datensätzen beruhen können, was vertrauenswürdigen Fortschritt hin zu Computerwerkzeugen beschleunigt, die tatsächlich bei der realen chemischen Gestaltung unterstützen.
Zitation: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
Schlüsselwörter: computerunterstützte Syntheseplanung, Reaktionsbenchmarking, Datensätze chemischer Reaktionen, Maschinelles Lernen für Chemie, Reaktionsvorhersage