Clear Sky Science · nl
SynRXN: Een open benchmark en gecureerde dataset voor computationele reactiemodellering
Waarom slimmer chemisch data belangrijk zijn
Moderne chemie leunt steeds meer op computers om nieuwe geneesmiddelen, materialen en alledaagse chemicaliën te ontwerpen. Maar zelfs de slimste algoritmen presteren alleen zo goed als de data waarvan ze leren. Vandaag de dag liggen reactiedata verspreid over octrooien, artikelen en labnotities in rommelige, inconsistente formaten, wat het moeilijk maakt om te beoordelen of concurrerende computergereedschappen echt vooruitgang boeken. Dit artikel introduceert SynRXN, een open en zorgvuldig gecureerde verzameling reactiedatasets en tests die onderzoekers een gemeenschappelijke basis biedt om te evalueren hoe goed hun methoden werken bij het plannen en begrijpen van chemische synthesen.
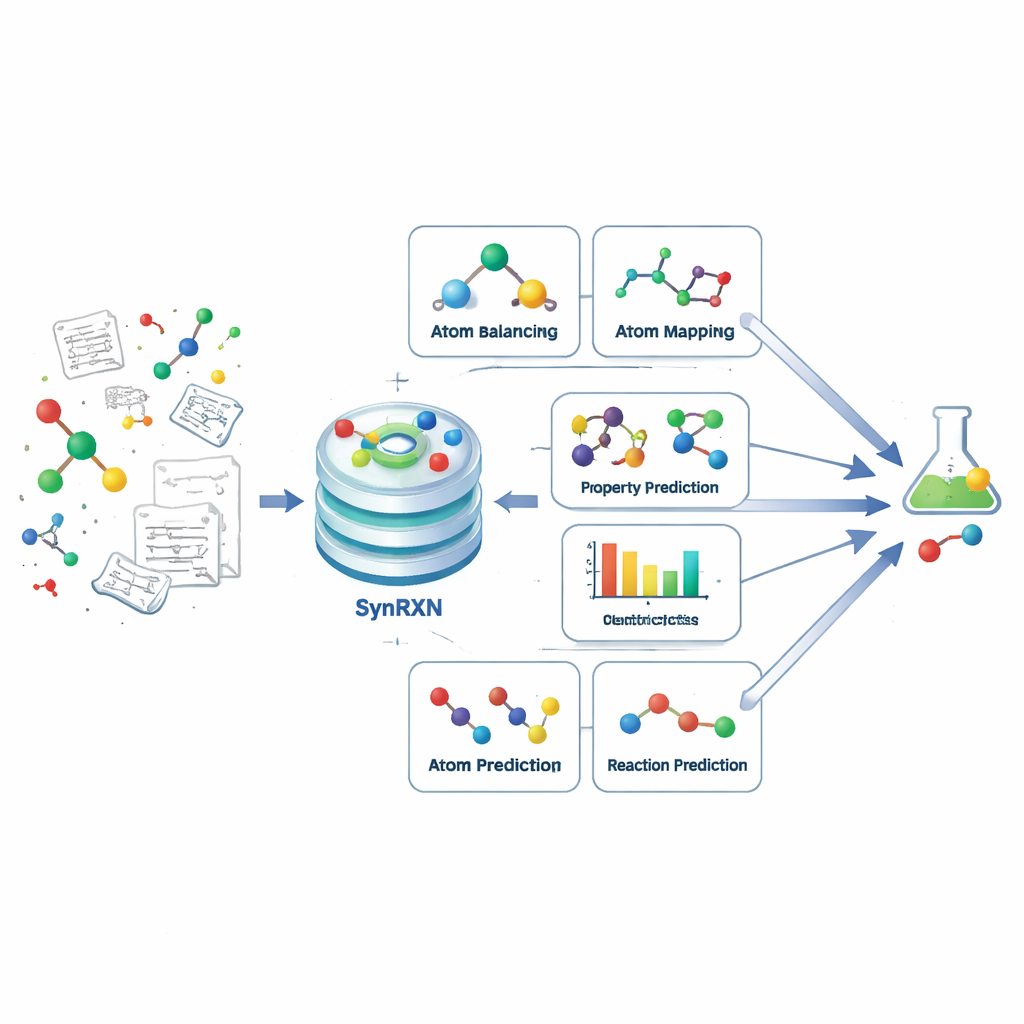
Een complex probleem opdelen in heldere stappen
Computerondersteunde syntheseplanning heeft als doel chemici te helpen bepalen hoe een doelmolecuul te maken is uit eenvoudigere bouwstenen. In plaats van dit als één monolithische uitdaging te behandelen, deelt SynRXN het op in vijf concrete taakfamilies die weerspiegelen wat chemici in de praktijk doen. Eerst komt het herstellen en completeren van reactierecords (rebalancing), daarna het volgen van hoe individuele atomen bewegen van beginstoffen naar producten (atoom-tot-atoom toewijzing), vervolgens het indelen van elke reactie in een categorie (reactieclassificatie), daarna het voorspellen van nuttige numerieke eigenschappen zoals opbrengsten of energiedrempels (voorspelling van reactie-eigenschappen), en tenslotte het voorspellen welke producten of beginstoffen waarschijnlijk zijn voor een gegeven transformatie (synthesevoorspelling). Door precieze inputs, outputs en evaluatiemaatstaven voor elk van deze stappen te definiëren, verandert SynRXN een verwarde workflow in een reeks goed gedefinieerde problemen.
Ruimtelijke chemische gegevens opschonen
Reactiedata uit de echte wereld zijn vaak onvolledig: octrooien en elektronische labnotities vermelden soms geen oplosmiddelen, tegenionen of bijproducten, of geven onmogelijke aantallen atomen. SynRXN pakt dit aan in de taak voor het herbalanceren van reacties door te beginnen met veelgebruikte, uit octrooien afkomstige datasets en doelbewust voorbeelden samen te stellen met specifieke soorten fouten, zoals missende niet-koolstofatomen of componenten die aan één of beide zijden van de vergelijking ontbreken. Vervolgens gebruikt het een hybride regel- en graafgebaseerde methode om de balans te herstellen, waarbij alleen correcties met zeer hoge betrouwbaarheid worden behouden en de uiteindelijke testset handmatig wordt geverifieerd. Voor atoom-tot-atoom toewijzing verzamelt SynRXN zowel organische als biochemische reacties uit meerdere betrouwbare bronnen en onderwerpt ze strikte, geautomatiseerde controles om te waarborgen dat moleculen geldig en consistent weergegeven zijn voordat wordt vergeleken hoe goed verschillende toewijzingshulpmiddelen het lot van elk atoom volgen.
Reacties organiseren in klassen en cijfers
Buiten het simpele weten of een reactie in balans is, zijn chemici geïnteresseerd in wat voor soort transformatie het is en hoe goed deze presteert. SynRXN stelt daarom meerdere niveaus van reactieclassificatietaken samen, variërend van brede categorieën tot fijnmazige verschillen in mechanisme, en omvat zowel organische reacties uit octrooien als enzymgeëngineerde reacties uit de biologie. Deze labels worden gekoppeld aan gestandaardiseerde manieren om data in trainings-, validatie- en testsets te splitsen, en aan afgesproken prestatiemaatstaven. Voor numerieke doelen verzamelt SynRXN datasets van reactieopbrengsten, energiedrempels, snelheden en andere eigenschappen uit de literatuur en openbare repositories. Alle data doorlopen een consistente opschoningspijplijn en er worden eenvoudige referentiemodellen geleverd zodat gebruikers snel kunnen zien of een nieuwe methode wezenlijk beter is dan een redelijke basislijn.
Reactievoorspellingen eerlijk en reproduceerbaar maken
Voor de synthesevoorspelling richt SynRXN zich op enkelstapsreacties waarbij een gegeven set reagentia leidt tot een of meer producten, of waarbij het doel is terug te redeneren van een product naar plausibele beginstoffen. Het bundelt drie invloedrijke, uit octrooien afkomstige corpora die veel groepen al gebruiken, maar exporteert ze opnieuw met deterministische, transparante splits en gemeenschappelijke evaluatiescripts. Onder de motorkap volgen alle SynRXN-datasets dezelfde tabulaire structuur met stabiele reactiedentifiers, gestandaardiseerde molecuulencoderingen en expliciete licentietags. Een machineleesbare manifest registreert bestandslocaties, checksums, kolomnamen en aantallen, waardoor iedereen dezelfde gecureerde tabellen op een andere machine of op een later tijdstip kan reproduceren met gescripte build-recepten.
Wat dit betekent voor toekomstige chemische ontdekkingen
In praktische zin introduceert SynRXN geen nieuw voorspellend model; in plaats daarvan biedt het de raamwerk dat nodig is om bestaande en toekomstige modellen eerlijk te vergelijken. Door reactiedata uit vele bronnen te harmoniseren, strikte kwaliteitscontroles af te dwingen en open, versiebeheerde benchmarks met referentie-resultaten te publiceren, stelt SynRXN onderzoekers in staat precies aan te geven welke onderdelen van de syntheseplanningspijplijn goed werken en waar ze falen. Voor chemici en dataspecialisten betekent dit dat claims over verbeterde prestaties gefundeerd kunnen worden op gedeelde tests in plaats van op op maat gemaakte, ondoorzichtige datasets, wat het geloofwaardige tempo van vooruitgang naar computergereedschappen die daadwerkelijk bijstaan in reëel chemisch ontwerp versnelt.
Bronvermelding: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
Trefwoorden: computerondersteunde syntheseplanning, reactiebenchmarking, datasets voor chemische reacties, machine learning voor chemie, reactievoorspelling