Clear Sky Science · fr
SynRXN : une référence ouverte et un jeu de données soigné pour la modélisation computationnelle des réactions
Pourquoi des données chimiques plus intelligentes comptent
La chimie moderne s’appuie de plus en plus sur l’informatique pour aider à concevoir de nouveaux médicaments, matériaux et produits chimiques du quotidien. Mais même les algorithmes les plus sophistiqués ne valent que par la qualité des données dont ils apprennent. Aujourd’hui, les données de réactions sont éparpillées dans des brevets, des articles et des carnets de laboratoire sous des formats désordonnés et incohérents, ce qui complique l’évaluation des améliorations réelles apportées par les outils informatiques concurrents. Cet article présente SynRXN, une collection ouverte et soigneusement organisée de jeux de données et de tests conçue pour offrir aux chercheurs un terrain d’évaluation commun afin de mesurer l’efficacité de leurs méthodes pour planifier et comprendre des synthèses chimiques.
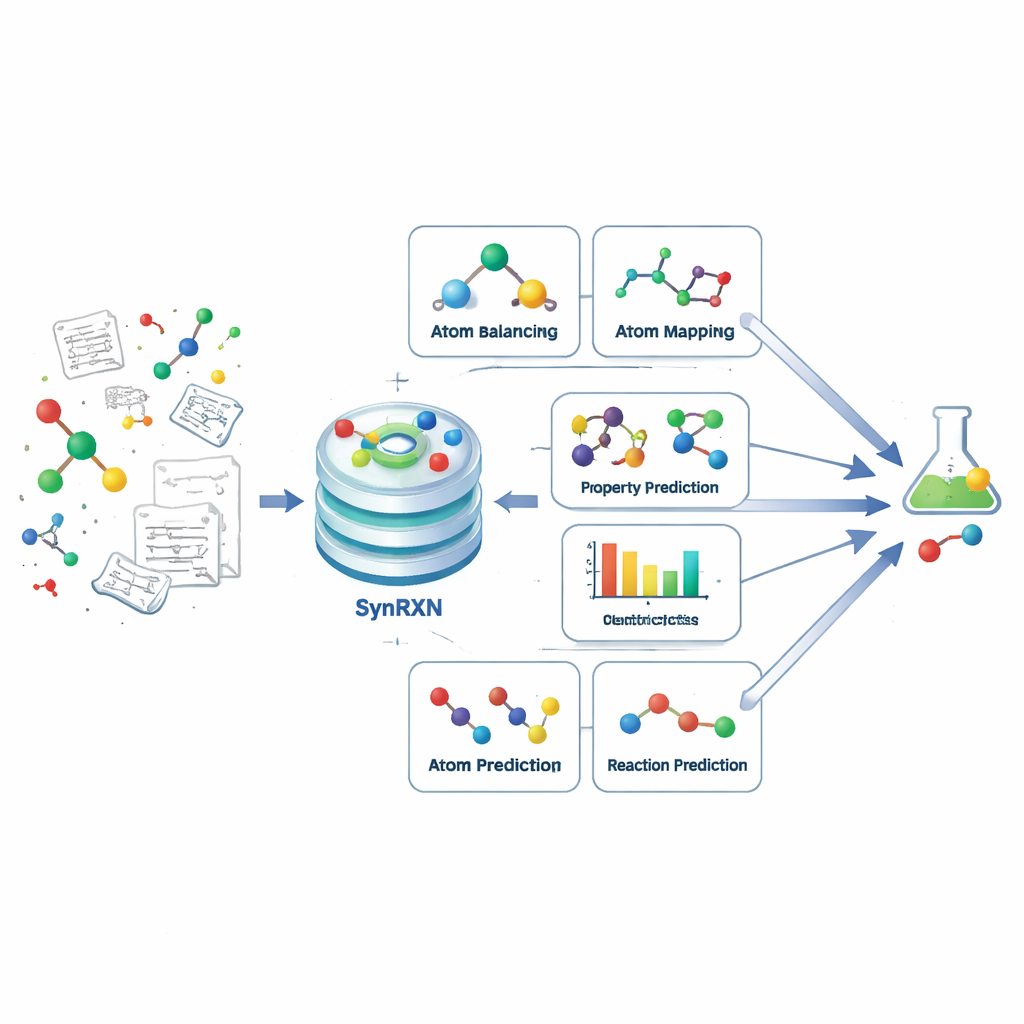
Fragmenter un problème complexe en étapes claires
La planification de synthèse assistée par ordinateur vise à aider les chimistes à déterminer comment fabriquer une molécule cible à partir de blocs de construction plus simples. Plutôt que de traiter cela comme un défi monolithique, SynRXN le divise en cinq familles de tâches concrètes qui reflètent les pratiques des chimistes. On commence par la correction et la complétion des enregistrements de réactions (rééquilibrage), puis le suivi du déplacement des atomes individuels des réactifs vers les produits (appareillage atome-à-atome), ensuite l’affectation de chaque réaction à une catégorie (classification des réactions), puis la prédiction de propriétés numériques utiles comme les rendements ou les barrières énergétiques (prédiction de propriétés de réaction), et enfin la prévision des produits ou des réactifs probables pour une transformation donnée (prédiction de synthèse). En définissant des entrées, sorties et mesures d’évaluation précises pour chacune de ces étapes, SynRXN transforme un flux de travail embrouillé en un ensemble de problèmes bien posés.
Nettoyer des enregistrements chimiques bruités
Les données de réactions réelles sont souvent incomplètes : les brevets et carnets électroniques peuvent omettre des solvants, des contre-ions ou des sous-produits, ou indiquer des nombres d’atomes impossibles. SynRXN aborde ce problème dans sa tâche de rééquilibrage en partant de jeux de données couramment utilisés issus de brevets et en construisant délibérément des exemples contenant des types d’erreurs spécifiques, comme l’absence d’atomes non carbonés ou de composants manquants d’un côté ou des deux côtés de l’équation. Il utilise ensuite une méthode hybride basée sur des règles et des graphes pour rétablir l’équilibre, ne conservant que les corrections à très haute confiance et vérifiant manuellement l’ensemble de test final. Pour l’appareillage atome-à-atome, SynRXN rassemble des réactions organiques et biochimiques provenant de plusieurs sources de confiance et les soumet à des vérifications automatiques strictes pour s’assurer que les molécules sont valides et représentées de manière cohérente avant de comparer la capacité des différents outils d’appareillage à suivre le devenir de chaque atome.
Organiser les réactions en classes et en nombres
Au-delà de savoir si une réaction est équilibrée, les chimistes s’intéressent au type de transformation et à ses performances. SynRXN assemble donc plusieurs niveaux de tâches de classification des réactions, allant de catégories larges jusqu’à des différences fines de mécanisme, et inclut à la fois des réactions organiques issues de brevets et des réactions catalysées par des enzymes issues de la biologie. Ces étiquettes sont associées à des méthodes standardisées pour diviser les données en ensembles d’entraînement, de validation et de test, et à des métriques de performance convenues. Pour les cibles numériques, SynRXN collecte des jeux de données de rendements, de barrières énergétiques, de vitesses et d’autres propriétés à partir de la littérature et de dépôts publics. Tous sont traités via un pipeline de nettoyage cohérent, et des modèles de référence simples sont fournis pour permettre aux utilisateurs de savoir rapidement si une nouvelle méthode surpasse réellement une base raisonnable.
Rendre les prédictions de réactions justes et reproductibles
Pour la tâche de prédiction de synthèse, SynRXN se concentre sur des réactions en une étape où un ensemble donné de réactifs conduit à un ou plusieurs produits, ou où l’objectif est de remonter depuis un produit vers des réactifs plausibles. Il regroupe trois corpus influents issus de brevets que de nombreux groupes utilisent déjà, mais les réexporte avec des divisions déterministes et transparentes et des scripts d’évaluation communs. En interne, tous les jeux de données SynRXN suivent la même structure tabulaire avec des identifiants de réaction stables, des codages de molécules standardisés et des balises de licence explicites. Un manifeste lisible par machine enregistre les emplacements des fichiers, les sommes de contrôle, les noms de colonnes et les comptages, permettant à quiconque de régénérer les mêmes tables curées sur une autre machine ou à une date ultérieure en utilisant des recettes de construction scriptées.
Ce que cela signifie pour la découverte chimique future
Concrètement, SynRXN n’introduit pas un nouveau modèle prédictif ; il fournit plutôt l’infrastructure nécessaire pour comparer équitablement les modèles existants et futurs. En harmonisant les données de réactions issues de nombreuses sources, en appliquant des contrôles de qualité stricts et en publiant des benchmarks ouverts et versionnés avec des résultats de référence, SynRXN permet aux chercheurs d’identifier quelles parties du pipeline de planification de synthèse fonctionnent bien et où elles échouent. Pour les chimistes et les data scientists, cela signifie que les affirmations d’amélioration des performances peuvent s’appuyer sur des tests partagés plutôt que sur des jeux de données sur-mesure et opaques, accélérant ainsi des progrès dignes de confiance vers des outils informatiques qui assistent réellement la conception chimique en conditions réelles.
Citation: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
Mots-clés: planification de synthèse assistée par ordinateur, évaluation des réactions, jeux de données de réactions chimiques, apprentissage automatique pour la chimie, prédiction de réactions