Clear Sky Science · ja
SynRXN:計算反応モデリングのためのオープンベンチマークとキュレーション済みデータセット
なぜより賢い化学データが重要なのか
現代の化学は、新しい医薬品や材料、日用品の設計にコンピュータをますます頼るようになっています。しかし、どれだけ高度なアルゴリズムであっても、それが学習するデータの質に依存します。現在、反応データは特許、論文、実験ノートなどに散在し、形式も不揃いであるため、競合するコンピュータツールが本当に改良されているかを判断するのが難しくなっています。本稿では SynRXN を紹介します。これは、合成計画や化学合成の理解を評価するための共通の土俵を研究者に提供することを目的とした、オープンで慎重にキュレーションされた反応データセットとテスト群です。
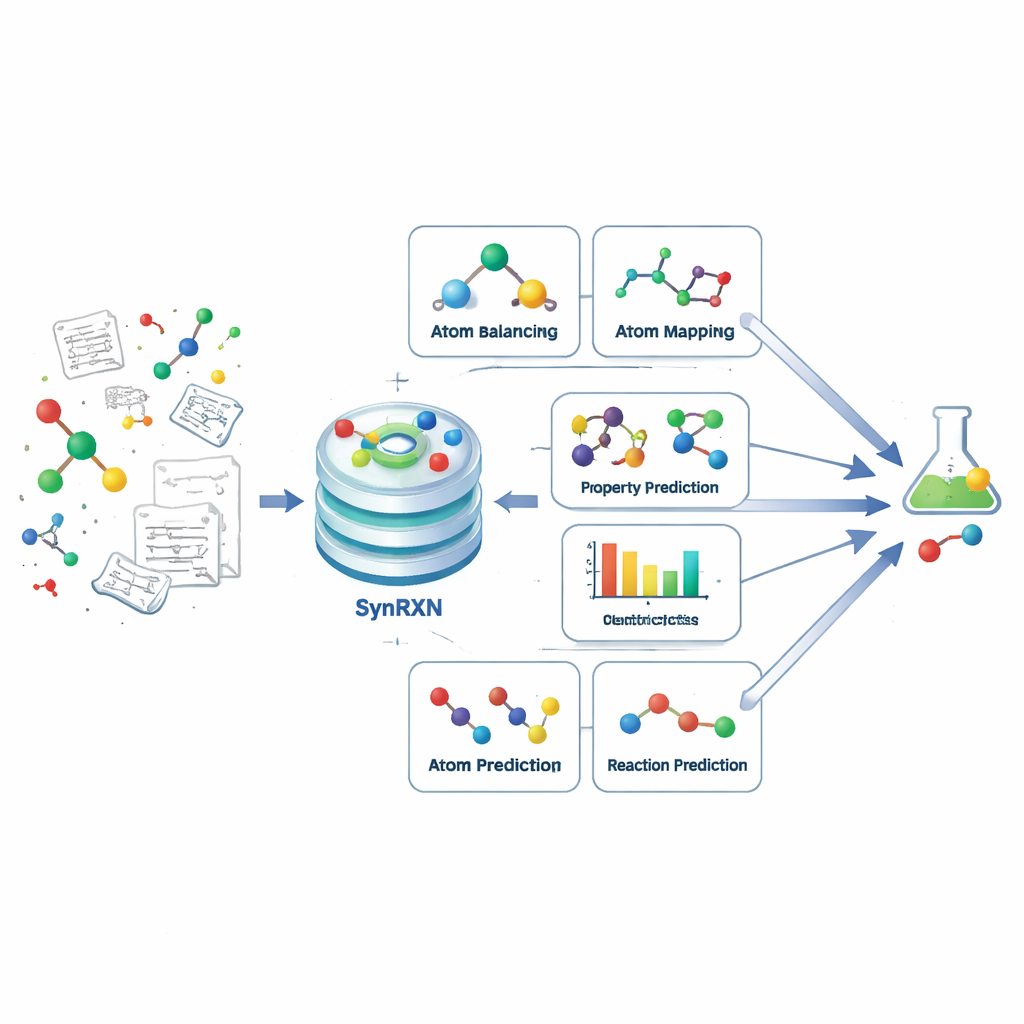
複雑な問題を明確なステップに分解する
コンピュータ支援合成設計は、標的分子をより単純な原料からどのように合成するかを化学者が見つける手助けをします。一括で対処するのではなく、SynRXN は実務で化学者が行う作業を反映した五つの具体的なタスク群に分解します。まず反応記録を修正・完備する(リバランス)、次に出発物質から生成物へ個々の原子がどう移動するかを追跡する(原子-原子マッピング)、続いて各反応をカテゴリに割り当てる(反応分類)、その後に反応収率やエネルギー障壁などの数値的性質を予測する(反応物性予測)、最後にある変換で生じうる生成物や出発物質を予測する(合成予測)です。各ステップについて入力、出力、評価指標を明確に定義することで、SynRXN は絡み合ったワークフローを良く定式化された問題群に変えます。
ノイズの多い化学記録のクリーンアップ
実際の反応データは不完全であることが多く、特許や電子実験ノートでは溶媒、対イオン、副生成物が欠落したり、原子数の矛盾が記載されることがあります。SynRXN は反応リバランスのタスクでこれに対処し、広く使われている特許由来データセットを出発点に、例えば非炭素原子が欠落しているケースや式の片側または両側で構成要素が欠けている事例など、特定タイプの誤りを意図的に構築した例を作成します。そこからルールベースとグラフベースを組み合わせた手法でバランスを回復し、非常に高い信頼度の補正のみを残し、最終テストセットは手作業で検証します。原子-原子マッピングについては、有機反応と生化学反応の双方を信頼できる複数のソースから収集し、分子が妥当で一貫して表現されていることを確認する厳格な自動チェックにかけた後で、各ツールが個々の原子の運命をどれだけ追跡できるかを比較します。
反応をクラスと数値に整理する
反応が単にバランスしているかどうかを知るだけでなく、化学者はその変換の種類や性能にも関心を持ちます。したがって SynRXN は、大まかなカテゴリからメカニズムの細かな違いに至るまでのいくつかの階層の反応分類タスクを構築し、特許由来の有機反応と酵素触媒反応の両方を含めます。これらのラベルには、データを訓練・検証・テストに分割する標準化された方法と合意された性能指標が付随します。数値目標については、文献や公的リポジトリから反応収率、エネルギー障壁、速度、その他の性質のデータセットを収集し、すべて一貫したクリーニングパイプラインに通します。簡単な参照モデルも提供されるため、ユーザーは新しい手法が妥当なベースラインより本当に優れているかをすぐに判断できます。
反応予測を公平で再現可能にする
合成予測タスクでは、SynRXN は与えられた試薬から1つ以上の生成物が得られる単一ステップ反応、あるいは生成物から妥当な出発物質を逆算する場合に焦点を当てます。多くのグループが既に使用している三つの影響力のある特許由来コーパスをバンドルしつつ、決定論的で透明な分割と共通の評価スクリプトで再提供します。内部的には、すべての SynRXN データセットは安定した反応識別子、標準化された分子エンコーディング、および明示的なライセンスタグを備えた同一の表形式構造に従います。機械判読可能なマニフェストにはファイル位置、チェックサム、列名、カウントが記録され、誰でもスクリプト化されたビルドレシピを使って別のマシンや将来の時点で同じキュレーション済み表を再生成できます。
今後の化学的発見にとっての意義
実務的には、SynRXN は新たな予測モデルを導入するものではなく、既存および将来のモデルを公平に比較するための足場を提供します。多くのソースから反応データを調和させ、厳格な品質チェックを課し、参照結果を含むオープンでバージョン管理されたベンチマークを公開することで、SynRXN は合成計画パイプラインのどの部分がうまく機能しているか、どこで失敗しているかを特定できるようにします。化学者とデータサイエンティストの双方にとって、改善の主張は個別の不透明なデータセットではなく共有のテストに基づけられるようになり、実世界の化学設計を実際に支援するコンピュータツールへの信頼できる進展が加速します。
引用: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
キーワード: コンピュータ支援合成設計, 反応ベンチマーキング, 化学反応データセット, 化学のための機械学習, 反応予測