Clear Sky Science · pl
SynRXN: Otwarty zestaw referencyjny i skuratorowany zbiór danych do modelowania reakcji chemicznych
Dlaczego lepsze dane chemiczne są ważne
Współczesna chemia coraz częściej opiera się na komputerach przy projektowaniu nowych leków, materiałów i powszechnie stosowanych chemikaliów. Jednak nawet najbardziej zaawansowane algorytmy są tak dobre, jak dane, na których się uczą. Obecnie dane o reakcjach są rozproszone w patentach, artykułach i zeszytach laboratoryjnych w chaotycznych, niespójnych formatach, co utrudnia ocenę, czy konkurencyjne narzędzia komputerowe rzeczywiście się poprawiają. W artykule przedstawiono SynRXN — otwarty, starannie skuratorowany zbiór danych reakcji i testów zaprojektowanych tak, by dać badaczom wspólne pole do porównań skuteczności metod w planowaniu i rozumieniu syntez chemicznych.
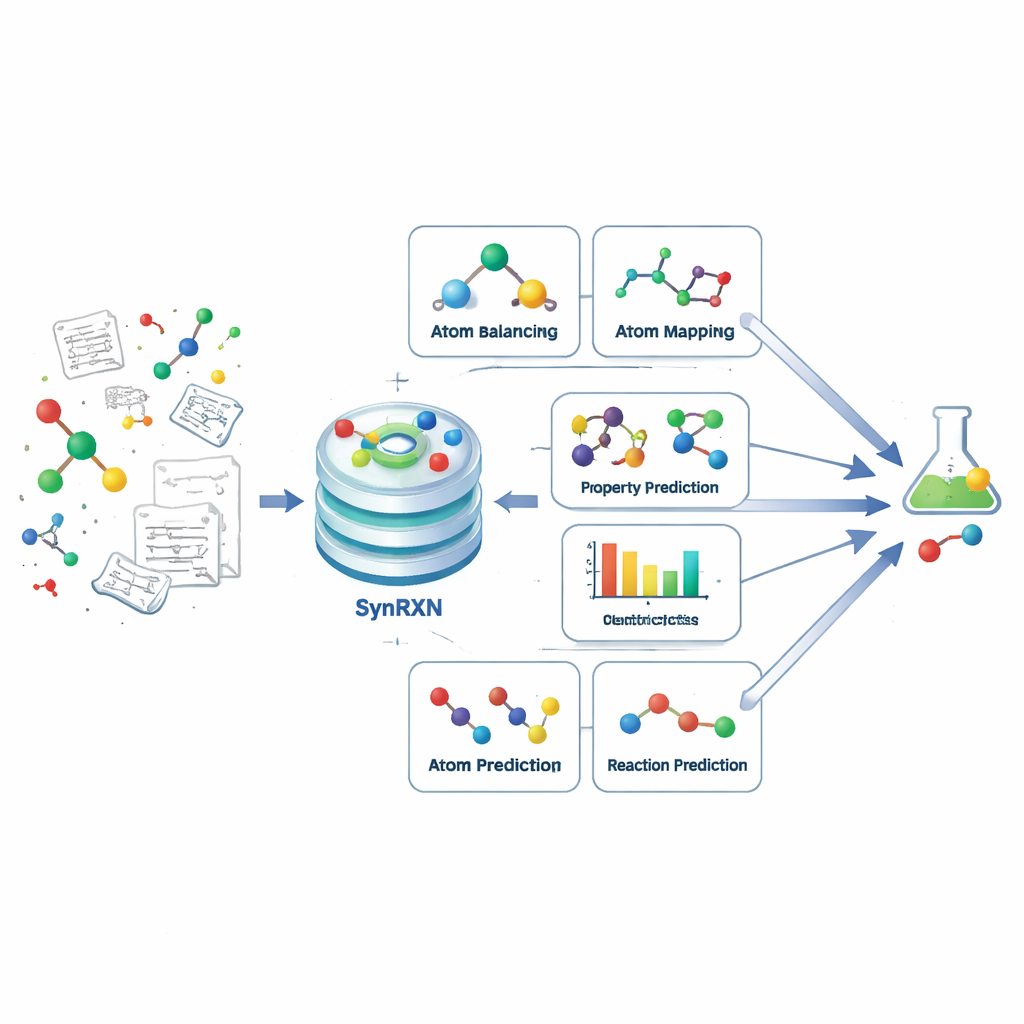
Rozbijanie złożonego problemu na przejrzyste kroki
Planowanie syntez z pomocą komputera ma pomóc chemikom w ustaleniu, jak otrzymać docelową cząsteczkę z prostszych cegiełek. Zamiast traktować to jako jeden monolityczny problem, SynRXN rozbija go na pięć konkretnych rodzin zadań, które odzwierciedlają praktyczne działania chemików. Najpierw następuje naprawa i uzupełnianie rekordów reakcji (rebalansowanie), potem śledzenie, jak poszczególne atomy przemieszczają się od substratów do produktów (mapowanie atom → atom), następnie przypisywanie reakcji do kategorii (klasyfikacja reakcji), przewidywanie użytecznych wartości numerycznych, takich jak wydajności reakcji czy bariery energetyczne (predykcja własności reakcji), i wreszcie prognozowanie, które produkty lub substraty są prawdopodobne dla danej przemiany (predykcja syntezy). Definiując precyzyjne wejścia, wyjścia i miary oceny dla każdego z tych etapów, SynRXN przekształca splątany przepływ pracy w zestaw dobrze postawionych problemów.
Czyszczenie zaszumionych rekordów chemicznych
Dane reakcyjne z rzeczywistych źródeł często są niekompletne: patenty i elektroniczne zeszyty laboratoryjne mogą pomijać rozpuszczalniki, przeciwjony lub produkty uboczne, albo podawać niemożliwe liczby atomów. SynRXN zajmuje się tym w zadaniu rebalansowania reakcji, zaczynając od powszechnie używanych zbiorów pochodzących z patentów i celowo konstruując przykłady z określonymi typami błędów, takimi jak brak atomów innych niż węgiel lub brakujące składniki po jednej bądź obu stronach równania. Następnie wykorzystuje hybrydową metodę opartą na regułach i grafach, aby przywrócić bilans, zachowując tylko korekty o bardzo wysokim poziomie pewności i ręcznie weryfikując finalny zestaw testowy. W zadaniu mapowania atom → atom SynRXN gromadzi reakcje organiczne i biochemiczne z kilku zaufanych źródeł i poddaje je rygorystycznym, zautomatyzowanym kontrolom, aby upewnić się, że cząsteczki są prawidłowe i reprezentowane w sposób spójny, zanim porówna, jak dobrze różne narzędzia śledzą los każdego atomu.
Organizowanie reakcji według klas i wartości liczbowych
Ponad samą wiedzę, czy reakcja jest zbilansowana, chemików interesuje też, jakiego typu jest to przemiana i jak dobrze przebiega. SynRXN dlatego składa kilka poziomów zadań klasyfikacji reakcji, od szerokich kategorii po drobne różnice w mechanizmie, i obejmuje zarówno reakcje organiczne z patentów, jak i reakcje katalizowane przez enzymy z biologii. Łączy te etykiety ze znormalizowanymi sposobami dzielenia danych na zbiory treningowe, walidacyjne i testowe oraz z uzgodnionymi metrykami wydajności. Dla celów numerycznych SynRXN zbiera zbiory danych dotyczące wydajności reakcji, barier energetycznych, szybkości i innych właściwości z literatury i repozytoriów publicznych. Wszystkie przechodzą przez spójny proces oczyszczania, a proste modele referencyjne są dostarczone, aby użytkownicy mogli szybko sprawdzić, czy nowa metoda jest naprawdę lepsza niż rozsądna baza odniesienia.
Czynienie predykcji reakcji uczciwymi i odtwarzalnymi
W zadaniu predykcji syntezy SynRXN koncentruje się na reakcjach jednoetapowych, gdzie dany zestaw reagentów prowadzi do jednego lub kilku produktów, albo gdy celem jest cofnięcie się od produktu do prawdopodobnych surowców wyjściowych. Łączy trzy wpływowe korpusy pochodzące z patentów, z których wiele grup już korzysta, ale ponownie eksportuje je z deterministycznymi, przejrzystymi podziałami i wspólnymi skryptami ewaluacyjnymi. Pod spodem wszystkie zbiory SynRXN stosują tę samą strukturę tabelaryczną ze stabilnymi identyfikatorami reakcji, znormalizowanymi kodowaniami cząsteczek i wyraźnymi tagami licencyjnymi. Maszynowo odczytywalny manifest rejestruje lokalizacje plików, sumy kontrolne, nazwy kolumn i liczby rekordów, umożliwiając komukolwiek odtworzenie tych samych skuratorowanych tabel na innym komputerze lub w późniejszym czasie przy użyciu skryptowanych przepisów budowy.
Co to oznacza dla przyszłych odkryć chemicznych
W praktyce SynRXN nie wprowadza nowego modelu predykcyjnego; zamiast tego dostarcza rusztowania niezbędnego do sprawiedliwego porównywania istniejących i przyszłych modeli. Poprzez harmonizację danych o reakcjach z wielu źródeł, egzekwowanie rygorystycznych kontroli jakości i publikowanie otwartych, wersjonowanych benchmarków z wynikami referencyjnymi, SynRXN pozwala badaczom zidentyfikować, które elementy procesu planowania syntez działają dobrze, a gdzie zawodzą. Dla chemików i specjalistów od danych oznacza to, że twierdzenia o poprawie wydajności mogą być oparte na wspólnych testach, a nie na niestandardowych, nieprzejrzystych zbiorach danych, przyspieszając wiarygodny postęp w kierunku narzędzi komputerowych, które rzeczywiście wspierają rzeczywisty projekt chemiczny.
Cytowanie: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
Słowa kluczowe: planowanie syntez z pomocą komputera, benchmarking reakcji, zbiory danych reakcji chemicznych, uczenie maszynowe w chemii, predykcja reakcji