Clear Sky Science · sv
SynRXN: En öppen referens och kurerad datamängd för beräkningsbaserad reaktionsmodellering
Varför smartare kemidata spelar roll
Modern kemi förlitar sig i allt större utsträckning på datorer för att hjälpa till att utforma nya läkemedel, material och vardagskemikalier. Men även de mest sofistikerade algoritmerna är bara så bra som de data de lärs av. Idag är reaktionsdata utspridda i patent, artiklar och labbanteckningar i röriga, inkonsekventa format, vilket försvårar bedömningen av om konkurrerande datorverktyg faktiskt blir bättre. Denna artikel introducerar SynRXN, en öppen, noggrant kurerad samling av reaktionsdatamängder och tester utformade för att ge forskare en gemensam spelplan för att utvärdera hur väl deras metoder fungerar vid planering och förståelse av kemiska synteser.
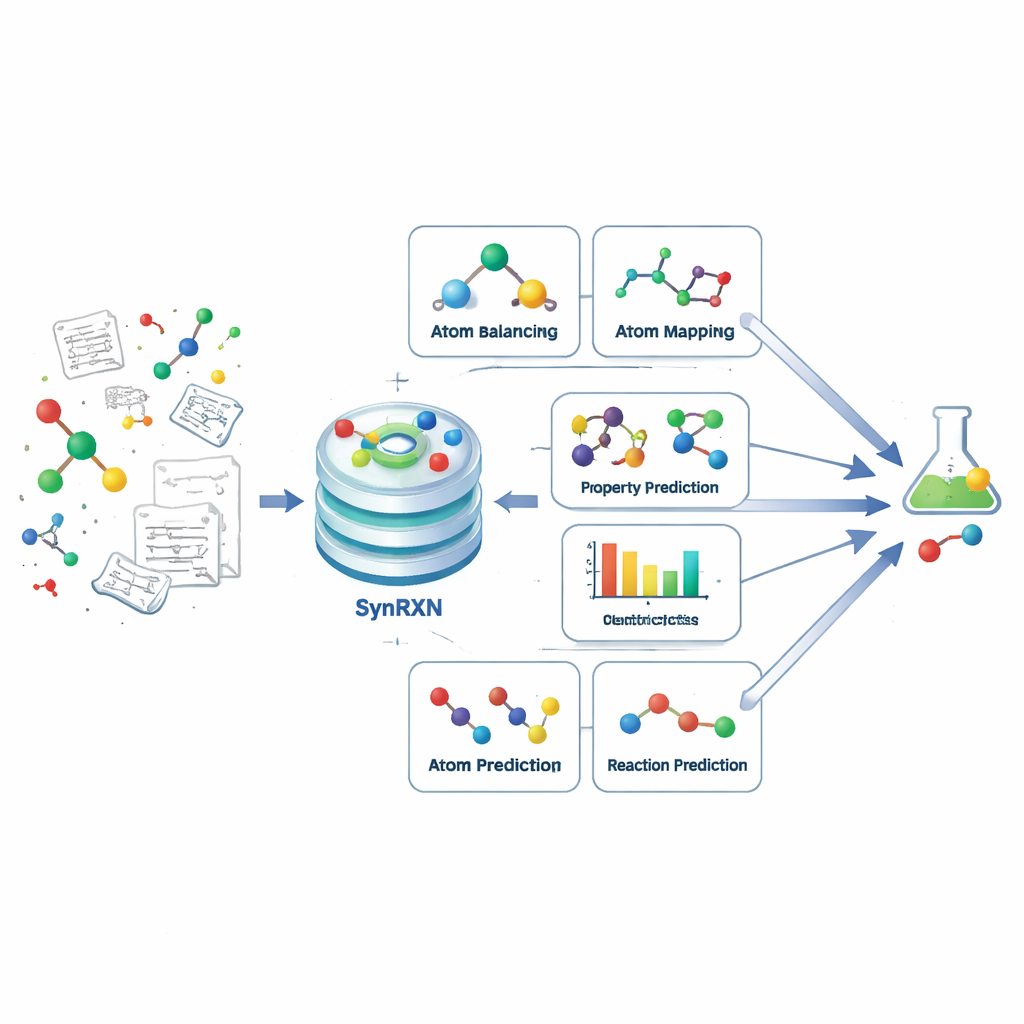
Att dela upp ett komplext problem i tydliga steg
Datorstödd syntesplanering syftar till att hjälpa kemister att lista ut hur man framställer en målstruktur från enklare byggstenar. Istället för att betrakta detta som en enda monolitisk utmaning delar SynRXN upp det i fem konkreta uppgiftsfamiljer som speglar vad kemister gör i praktiken. Först kommer korrigering och komplettering av reaktionsposter (rebalansering), därefter spårning av hur enskilda atomer förflyttar sig från startmaterial till produkter (atom-till-atom-mappning), sedan klassificering av varje reaktion (reaktionsklassificering), därefter prediktion av användbara numeriska egenskaper såsom reaktionsutbyte eller energibarriärer (reaktionsegenskaps-prediktion), och slutligen prognoser för vilka produkter eller startmaterial som är sannolika vid en given transformation (syntesprediktion). Genom att definiera precisa indata, utdata och utvärderingsmått för varje av dessa steg förvandlar SynRXN ett trassligt arbetsflöde till en uppsättning väldefinierade problem.
Rensa upp brusiga kemiska poster
Data från verkliga reaktioner är ofta ofullständiga: patent och elektroniska labbanteckningar kan utelämna lösningsmedel, motjoner eller sidoprodukter, eller lista omöjliga atomantal. SynRXN tar itu med detta i sin uppgift för reaktionsrebalansering genom att börja från vida använda patentbaserade datamängder och medvetet konstruera exempel med specifika typer av fel, såsom saknade icke-kol-atomer eller komponenter som saknas på ena eller båda sidor av ekvationen. Därefter använder man en hybridmetod baserad på regler och grafmetoder för att återställa balansen, där endast korrigeringar med mycket hög förtroendenivå behålls och den slutliga testsatsen manuellt verifieras. För atom‑till‑atom‑mappning samlar SynRXN både organiska och biokemiska reaktioner från flera betrodda källor och utsätter dem för strikta, automatiserade kontroller för att säkerställa att molekyler är giltiga och konsekvent representerade innan man jämför hur väl olika mappningsverktyg spårar varje atoms öde.
Organisera reaktioner i klasser och siffror
Bortom att enbart veta om en reaktion är balanserad bryr sig kemister om vilken typ av transformation det rör sig om och hur väl den presterar. SynRXN sätter därför ihop flera nivåer av reaktionsklassificeringsuppgifter, från breda kategorier ned till finmaskiga skillnader i mekanism, och inkluderar både organiska reaktioner från patent och enzymkatalyserade reaktioner från biologin. Dessa etiketter paras med standardiserade sätt att dela upp data i tränings-, validerings- och testsatser samt med överenskomna prestationsmått. För numeriska mål samlar SynRXN datamängder av reaktionsutbyten, energibarriärer, hastigheter och andra egenskaper från litteratur och offentliga arkiv. Alla körs genom en konsekvent rensningspipeline, och enkla referensmodeller tillhandahålls så att användare snabbt kan avgöra om en ny metod verkligen är bättre än en rimlig baseline.
Göra reaktionsprediktioner rättvisa och reproducerbara
För uppgiften syntesprediktion fokuserar SynRXN på enkelstegsreaktioner där en given uppsättning reaktanter leder till en eller flera produkter, eller där målet är att arbeta bakåt från en produkt till plausibla startmaterial. Den paketerar tre inflytelserika patentbaserade korporor som många grupper redan använder, men återexporterar dem med deterministiska, transparenta uppdelningar och gemensamma utvärderingsskript. Under huven följer alla SynRXN-datamängder samma tabellstruktur med stabila reaktionsidentifierare, standardiserade molekylkodningar och explicita licensetiketter. Ett maskinläsbart manifest registrerar filplatser, checksummor, kolumnnamn och räkningar, vilket möjliggör för vem som helst att återgenerera samma kurerade tabeller på en annan maskin eller vid ett senare tillfälle med skriptade bygge‑recept.
Vad detta innebär för framtida kemisk upptäckt
I praktiska termer introducerar SynRXN inte en ny prediktiv modell; istället tillhandahåller det den struktur som behövs för att jämföra befintliga och framtida modeller på ett rättvist sätt. Genom att harmonisera reaktionsdata från många källor, ställa hårda kvalitetskontroller och publicera öppna, versionerade benchmark med referensresultat, gör SynRXN det möjligt för forskare att peka ut vilka delar av syntesplaneringskedjan som fungerar väl och var de brister. För både kemister och dataforskare betyder detta att påståenden om förbättrad prestanda kan grundas i delade tester snarare än skräddarsydda, ogenomskinliga datamängder, vilket påskyndar pålitlig utveckling av datorverktyg som verkligen hjälper verklig kemisk design.
Citering: Phan, TL., Nguyen Song, NN. & Stadler, P.F. SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling. Sci Data 13, 625 (2026). https://doi.org/10.1038/s41597-026-07260-w
Nyckelord: datorstödd syntesplanering, reaktionsbenchmarking, datamängder för kemiska reaktioner, maskininlärning för kemi, reaktionsprediktion