Clear Sky Science · tr
Hastalar için saf‑ton odyogram yorumlamasında büyük dil modellerinin çok merkezli çok amaçlı değerlendirmesi
İşitme testi raporları neden bu kadar anlaşılması zor
Birçok kişi işitme testinden, doktorun kısa bir notu dışında sadece noktalar ve çizgilerle dolu bir grafikle çıkar. Uzman olmayanlar için bu saf‑ton odyogram raporlarını çözmek neredeyse imkânsızdır; oysa bu raporlar işitme cihazları, tedavi ve günlük iletişim hakkındaki hayat değiştiren kararlara temel oluşturur. Bu çalışma, büyük dil modelleriyle güçlendirilmiş modern yapay zeka sohbet botlarının bu teknik grafikleri sıradan hastalar için net, güven verici açıklamalara dönüştürüp dönüştüremeyeceğini sorguluyor.
Karmaşık kulak grafiklerini sade dile çevirme
Saf‑ton odyogramları, düşük gürültülerden yüksek perdeli seslere kadar farklı tonları ne kadar iyi duyduğumuzu ölçmede altın standart testtir. Ortaya çıkan rapor, daha çok bir fizik deneyi raporunu andırır, sağlık özeti gibi değildir. Aynı zamanda, eğitimli işitme uzmanları dünya çapında yetersizdir; özellikle tıbbi kaynakların sınırlı olduğu bölgelerde bu eksiklik daha belirgindir. Araştırmacılar burada bir fırsat gördü: sohbet botları bu grafikleri “okuyup” sonuçları günlük dilde açıklayabilirse, hastaların işitmelerini daha erken ve daha iyi anlamalarına yardımcı olabilir ve Dünya Sağlık Örgütü’nün “herkes için işitme sağlığı” hedefini destekleyebilir.
Birden fazla sohbet botunu teste sokmak
Araştırma ekibi Çin’deki iki merkezden 140 gerçek işitme testi raporu topladı, kişisel bilgileri kaldırdı ve odyogram grafiklerinin standartlaştırılmış sürümlerini yeniden oluşturdu. Ardından, Çin ve ABD’den şirketlere ait sekiz farklı büyük dil modelinden her rapor için üç görev yapmaları istendi: işitme kaybının ne kadar şiddetli olduğunu ve hangi tür olduğunu belirtmek (örneğin iç kulakla mı yoksa dış kulakla mı ilişkili), bulguları hasta dostu bir dille açıklamak ve ne zaman bakım aramaları veya işitme cihazlarını düşünmeleri gerektiği gibi pratik öneriler sunmak. Tüm model çıktıları kontrollü ortamda toplandı ve daha sonra hangi modelin hangi cevabı ürettiğini bilmeyen deneyimli klinisyenler ve bağımsız gönüllü halk değerlendiriciler tarafından puanlandı.
Makineler işitme kaybını ne kadar iyi teşhis etti
Sanal bir işitme uzmanı gibi davranma söz konusu olduğunda, modellerin performansı karışıktı. En iyi performans gösteren sistem DeepSeek‑V3, işitme kaybının şiddetini yaklaşık üçte iki oranında doğru değerlendirdi ve işitme kaybının geniş türünü ise yüzde ellinin biraz üzerinde doğru belirledi. Diğer modeller genellikle daha kötü performans gösterdi ve genel doğruluk eğitimli klinisyenlerden beklenen seviyenin çok altındaydı. Araştırmacılar ayrıca modelleri besleme biçimlerinde alternatif yollar da denedi; örneğin grafik görsellerine daha yapılandırılmış sayısal veriler eklemek gibi. Bu değişiklikler çoğu sistemin doğruluğunu artırdı; bu da bilgilerin nasıl sunulduğunun modelin gücü kadar önemli olabileceğini düşündürüyor.
Yararlı açıklamalar, ama rahatsız edici uydurma ayrıntılar
Ham doğruluk dışında, çalışma sohbet botlarının açıklamalarının ne kadar okunabilir ve güvenilir olduğunu da inceledi. Bazı modeller uzun, sözcük yığan yanıtlar üretirken, diğerleri daha özlüydü. Sadece DeepSeek modelleri tutarlı şekilde ortaokul düzeyine uygun okuma seviyesi yazdı; bu da büyük sağlık kuruluşlarının sağlık okuryazarlığı yönergeleriyle uyumluydu. Ancak birkaç sistem rahatsız edici bir şekilde hayal ürünü ayrıntılar uydurma eğilimi gösterdi. Bazı modellerin yanıtlarının yaklaşık dörtte birinde sohbet botu numaralar uydurdu, işitme eşiklerini yanlış bildirdi ya da var olmayan cihazlar ve gerçekçi olmayan tedavi yolları önerdi. Buna karşılık, bir Gemini modelinde çok daha az uydurma bulundu; ancak tıbbi doğruluğu en yüksek olan o değildi.
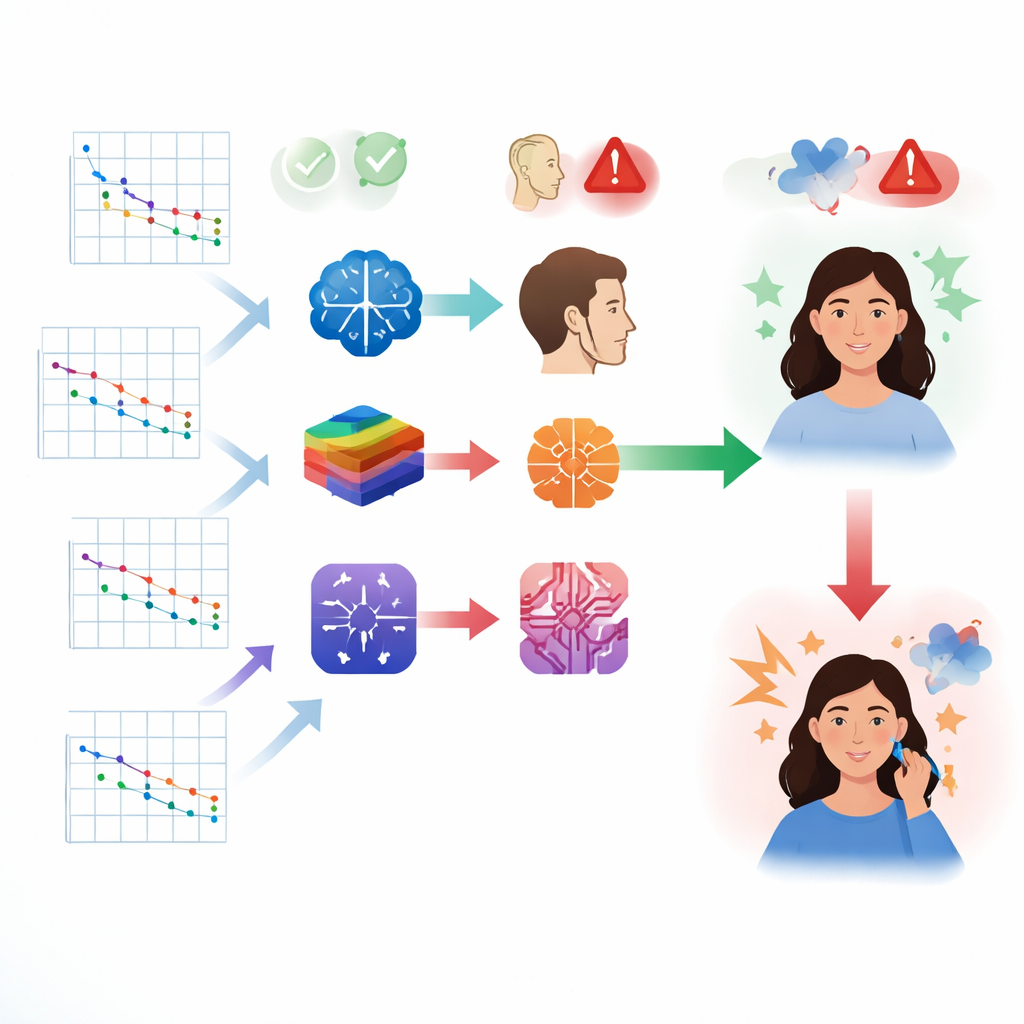
Uzmanlar ve günlük kullanıcılar ne düşündü
Klinisyenler modelleri cevaplarının ne kadar doğru, kapsamlı ve pratik olarak kullanışlı olduğu açısından değerlendirdi. Burada yine DeepSeek‑V3 ve onun kardeş modeli profesyonel kalite açısından genellikle en yüksek sırada yer aldı; yapılandırılmış yorumlar ve klinik uygulamayla uyumlu hedefe yönelik öneriler sundular. Ancak aynı yanıtları halka sunulduğunda öncelikler değişti. Uzman olmayanlar daha kolay takip edilebilen, daha konuşma dili tarzında ve duygusal olarak daha destekleyici modelleri tercih etti; bunlar her zaman en tıbbi doğrulukta olanlar değildi. Gemini modelleri özellikle açıklık, empati ve genel memnuniyet açısından yüksek puan aldı; bu da katı profesyonel standartlar ile hasta merkezli iletişim ihtiyaçları arasında bir gerilim olduğunu gösteriyor.
İşitme sorunu olan insanlar için bunun önemi nedir
İşitme kaybı yaygındır ve birçok insan test sonuçlarının net bir açıklamasını asla alamaz. Bu çalışma, bugünün sohbet botlarının odyologların yerini alacak veya işitme grafikleriyle tek başına teşhis koyacak kadar hazır olmadığını gösteriyor. Hata oranları ve ara sıra ortaya çıkan uydurulmuş ayrıntılar, denetim olmadan kullanıldığında hastaları yanlış yönlendirebilir. Aynı zamanda, modellerin hali hazırda gerçek güçlü yönleri de var: yoğun grafikleri sade dile çevirmek, ilk rehberliği sunmak ve aksi halde soracak kimsesi olmayan insanların kaygısını hafifletmek. Uyarılarla birlikte ve işitme uzmanlarının denetiminde dikkatle kullanıldığında, bu tür araçlar bakım erişimindeki boşlukları kapatmaya, anlayışı artırmaya ve işitme sağlığı konusunda daha erken adım atılmasını desteklemeye yardımcı olabilecek değerli asistanlara dönüşebilir.
Atıf: Liang, J., Xing, M., Xiang, P. et al. A multicenter multifunctional assessment of large language models in pure-tone audiogram interpretation for patients. npj Digit. Med. 9, 348 (2026). https://doi.org/10.1038/s41746-026-02537-1
Anahtar kelimeler: işitme kaybı, saf‑ton odyogramı, büyük dil modelleri, hasta iletişimi, dijital sağlık