Clear Sky Science · it
Valutazione multicentrica e multifunzionale dei grandi modelli linguistici nell’interpretazione dell’audiogramma tonale puro per i pazienti
Perché i referti audiometrici sono così difficili da capire
Molte persone lasciano il test dell’udito con in mano un grafico pieno di punti e linee, accompagnato solo da una breve nota del medico. Per i non specialisti, questi referti basati sull’audiogramma tonale puro sono quasi impossibili da decifrare, eppure orientano scelte che possono cambiare la vita riguardo agli apparecchi acustici, ai trattamenti e alla comunicazione quotidiana. Questo studio valuta se gli attuali chatbot di intelligenza artificiale, alimentati da grandi modelli linguistici, possano trasformare quei grafici tecnici in spiegazioni chiare e rassicuranti per i pazienti comuni.
Trasformare grafici auricolari complessi in linguaggio semplice
Gli audiogrammi tonali puri sono il test di riferimento per misurare quanto bene percepiamo toni diversi, dai rimbombi bassi agli acuti. Il referto risultante assomiglia più a un esperimento di fisica che a un sommario medico. Allo stesso tempo, gli specialisti dell’udito formati scarseggiano a livello mondiale, soprattutto nelle aree con risorse sanitarie limitate. I ricercatori hanno individuato un’opportunità: se i chatbot riuscissero a “leggere” questi grafici e a spiegare i risultati in un linguaggio quotidiano, potrebbero aiutare i pazienti a comprendere il loro stato uditivo prima e più a fondo, sostenendo l’obiettivo dell’Organizzazione Mondiale della Sanità di «salute uditiva per tutti».
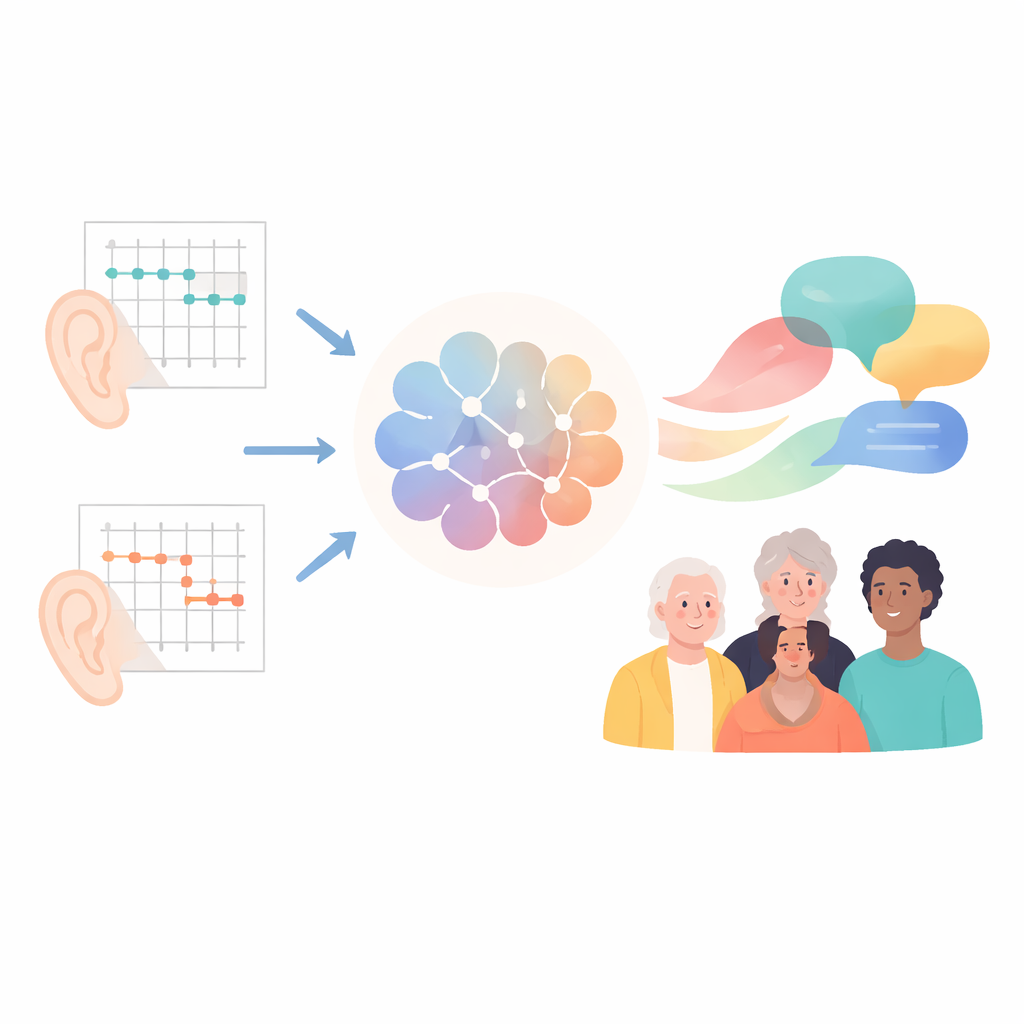
Mettere alla prova più chatbot
Il team ha raccolto 140 referti audiometrici reali provenienti da due centri in Cina, ha rimosso i dati personali e ha rigenerato versioni standardizzate dei grafici audiometrici. Hanno quindi chiesto a otto diversi grandi modelli linguistici, di aziende sia cinesi sia statunitensi, di svolgere tre compiti per ciascun referto: indicare la gravità della perdita uditiva e il tipo (ad esempio legata all’orecchio interno o esterno), spiegare i risultati in termini comprensibili al paziente e offrire raccomandazioni pratiche come quando cercare assistenza o considerare apparecchi acustici. Tutte le risposte dei modelli sono state raccolte in condizioni controllate e poi valutate da clinici esperti e da volontari non esperti separati, che non sapevano quale modello aveva prodotto quale risposta.
Quanto bene le macchine diagnosticano la perdita uditiva
Nel ruolo di specialisti virtuali dell’udito, le prestazioni dei modelli sono risultate variabili. Il sistema con le migliori prestazioni, DeepSeek‑V3, ha giudicato correttamente la gravità della perdita uditiva in circa due terzi dei casi e ha identificato il tipo generale di perdita poco più della metà delle volte. Altri modelli spesso hanno fatto peggio e l’accuratezza generale è rimasta molto al di sotto di quella attesa da clinici formati. I ricercatori hanno anche testato modalità alternative di fornire le informazioni ai modelli, ad esempio aggiungendo numeri più strutturati insieme alle immagini dei grafici. Questi cambiamenti hanno migliorato l’accuratezza per la maggior parte dei sistemi, suggerendo che il modo in cui le informazioni sono presentate può essere importante quanto la potenza del modello.
Spiegazioni utili, ma dettagli inventati preoccupanti
Oltre all’accuratezza pura, lo studio ha esaminato quanto fossero leggibili e affidabili le spiegazioni fornite dai chatbot. Alcuni modelli hanno prodotto risposte lunghe e verbose, altri sono stati più concisi. Solo i modelli DeepSeek hanno sempre scritto a un livello di lettura approssimativamente adatto a chi ha un’istruzione di scuola media, in linea con le linee guida sulla alfabetizzazione sanitaria delle principali organizzazioni mediche. Tuttavia, diversi sistemi hanno mostrato una preoccupante tendenza a «allucinare», inventando dettagli non presenti nei referti originali. In circa una risposta su quattro di alcuni modelli, il chatbot ha fabbricato numeri, indicato in modo errato le soglie uditive o raccomandato dispositivi inesistenti e percorsi terapeutici irrealistici. Invece, un modello Gemini ha mostrato molte meno allucinazioni, anche se la sua accuratezza medica non era la più alta.
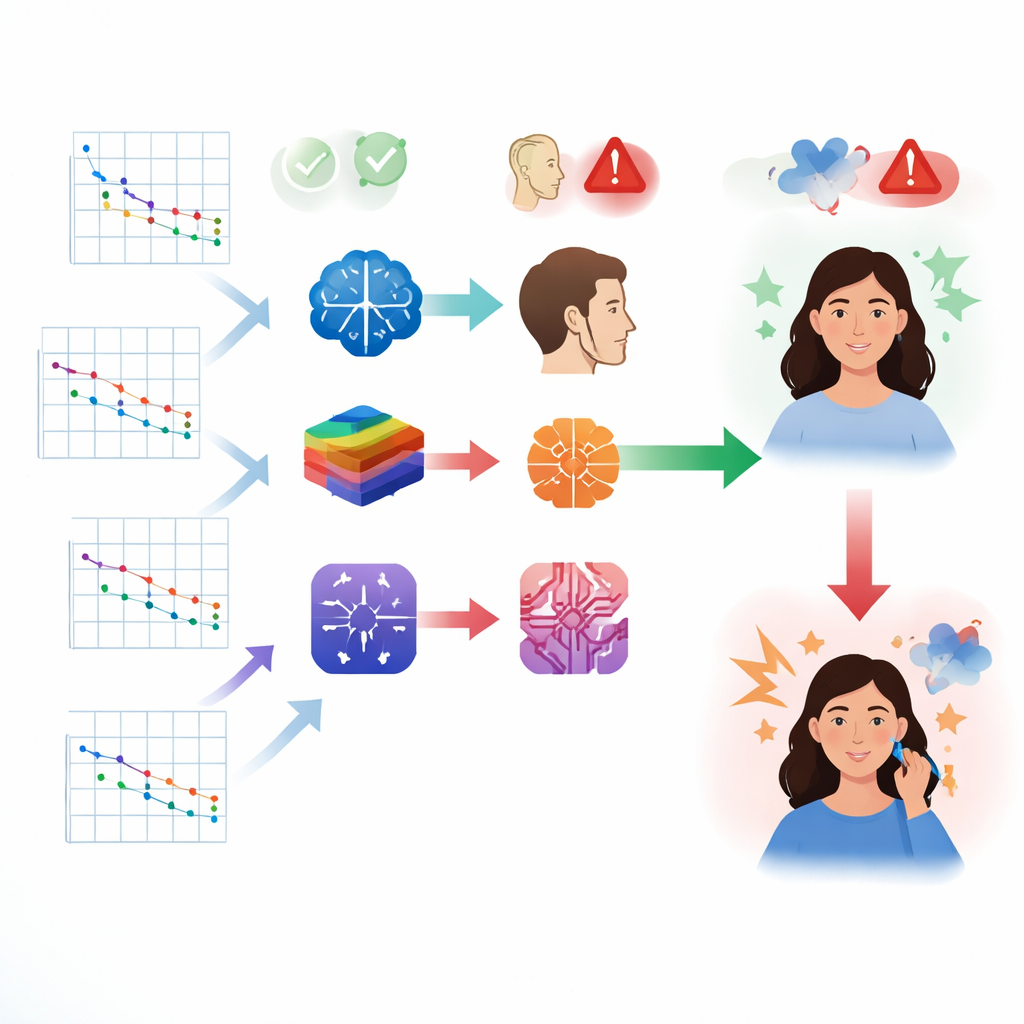
Cosa ne pensavano gli esperti e gli utenti comuni
I clinici hanno valutato i modelli in base a quanto le loro risposte fossero accurate, complete e praticamente utili. Anche qui DeepSeek‑V3 e il suo modello gemello si sono generalmente classificati al top per qualità professionale, offrendo interpretazioni strutturate e raccomandazioni mirate allineate alla pratica clinica. Tuttavia, quando il pubblico ha valutato le stesse risposte, le priorità sono cambiate. I non esperti hanno preferito modelli più facili da seguire, più conversazionali e più di supporto emotivo, anche se non erano i più precisi dal punto di vista medico. I modelli Gemini hanno ottenuto punteggi particolarmente alti per chiarezza, empatia e soddisfazione complessiva, evidenziando una tensione tra standard professionali rigorosi e le esigenze di comunicazione incentrata sul paziente.
Perché questo è importante per le persone con problemi d’udito
La perdita uditiva è diffusa e molte persone non ricevono mai una spiegazione chiara dei risultati dei test. Questo studio dimostra che i chatbot attuali non sono pronti a sostituire gli audiologi o a formulare diagnosi autonome a partire dai grafici audiometrici. I loro tassi di errore e i dettagli occasionalmente inventati potrebbero fuorviare i pazienti se usati senza supervisione. Al contempo, i modelli presentano già punti di forza reali: trasformare grafici densi in linguaggio semplice, offrire indicazioni iniziali e ridurre l’ansia per chi altrimenti non avrebbe a chi chiedere. Usati con cautela, con avvertenze chiare e sotto la supervisione di professionisti dell’udito, tali strumenti potrebbero diventare assistenti utili per colmare le lacune nell’accesso alle cure, migliorare la comprensione e favorire interventi più precoci per la salute uditiva.
Citazione: Liang, J., Xing, M., Xiang, P. et al. A multicenter multifunctional assessment of large language models in pure-tone audiogram interpretation for patients. npj Digit. Med. 9, 348 (2026). https://doi.org/10.1038/s41746-026-02537-1
Parole chiave: perdita uditiva, audiogramma tonale puro, grandi modelli linguistici, comunicazione con i pazienti, salute digitale