Clear Sky Science · tr
Kütle spektrometrisi verilerinden belirsizlik nicelenmiş peptit özelliklerini tahmin etmek için uçtan uca derin dikkat tabanlı çok görevli boru hattı
Bu araştırmanın sağlık ve biyoloji için önemi
Modern biyomedikal araştırmalar, hücrelerimizde ve dokularımızda hangi proteinlerin bulunduğunu okumak için kütle spektrometrisine büyük ölçüde dayanır. Yine de, güçlü cihazlar ve geniş veritabanlarına rağmen, özellikle kanser veya nörolojik bozukluklar gibi hastalıklarda kilit rol oynayabilecek nadir veya alışılmadık proteinler için verilerin şaşırtıcı bir kısmı açıklanamamış halde kalır. Bu makale, ham verilerden doğrudan protein parçacıklarının (peptitlerin) temel özelliklerini tahmin ederken aynı zamanda bu tahminlerin ne kadar güvenilir olduğunu da araştırmacılara bildiren ProteoRift adlı bir makine öğrenimi sistemi sunuyor.

Protein parmak izlerini okumadaki darboğaz
Kütle spektrometrisi, proteinleri peptit adı verilen daha küçük parçalara ayırıp ortaya çıkan fragmentlerin kütlesini ölçerek çalışır. Standart yazılımlar daha sonra her gözlenen spektruma karşılık gelen hesaplanan kütle ile eşleşen peptit dizilerini büyük protein veritabanlarında arar. Bu aramayı hesaplama açısından makul kılmak için çoğu araç basit bir kural uygular: yalnızca toplam kütlesi ölçülen değere yakın olan adayları dikkate alırlar. Bu kütle tabanlı filtreleme süreci hızlandırsa da bir bedeli vardır. Eğer kütle hafifçe yanlış atanmışsa veya bir peptitte beklenmeyen bir kimyasal modifikasyon varsa, doğru yanıt daha baştan elenebilir; bu da atanamayan spektrumların büyük havuzuna ve bol bulunan, iyi davranan peptitlere yönelik bir yanlılığa katkıda bulunur.
Aramayı daraltmak için daha akıllı bir yol
ProteoRift farklı bir strateji sunuyor: adayları yalnızca kütleyle filtrelemek yerine, herhangi bir veritabanı araması yapılmadan önce her spektrumdan daha zengin bilgiler çıkarmayı öğreniyor. Sistem, bir spektrumdaki tepe desenini ve temel edinim (acquisition) ayrıntılarını girdi olarak alan dikkat tabanlı bir derin sinir ağı etrafında inşa edilmiştir. Bundan, aynı anda altta yatan peptitin üç özelliğini tahmin eder: uzunluğu, örnek hazırlama sırasında kaç kez kesildiği (kaçırılmış kesilmeler) ve herhangi bir modifikasyon taşıyıp taşımadığı. Bu görevler ilişkili olduğundan, bunları birlikte eğitmek modelin spektrumların sağlam bir iç temsiliyetini oluşturmasını teşvik eder ve yeni verilere genelleme yeteneğini artırır.
Tahminleri daha hızlı ve daha hafif aramalara dönüştürmek
Bu tahminleri işe koymak için yazarlar ProteoRift’i, spektrumları gömülü bir uzayda peptit dizileriyle eşleştiren daha önce geliştirilmiş SpeCollate adlı bir araçla birlikte uçtan uca bir boru hattına entegre ediyorlar. Önce ProteoRift, her spektrumu uzunluk aralığı, kaçırılmış kesim sayısı ve modifikasyon durumu ile tanımlanan bir sınıfa atar. Veritabanındaki peptitler de bilinen özelliklerine göre benzer şekilde gruplanır. Arama motoru daha sonra benzer kütleye sahip her peptiti taramak yerine spektrumları yalnızca aynı sınıftaki peptitlerle karşılaştırır. Birçok insan ve mikrobiyom veri setinde bu hedeflenmiş filtreleme teoride aday arama alanını %90’dan fazla küçültür ve pratikte yalnızca kütleye dayalı filtrelerle karşılaştırıldığında yaklaşık 8 ila 12 kat hızlanma sağlar; aynı sayıda güvenle tanımlanmış peptiti geri kazandırır. Çok büyük proteogenomik ve meta-proteomik veritabanlarında ise belirli testlerde hızlanmalar daha da yüksek olabilir, bazı durumlarda 40 kattan fazla gözlemlenmiştir.
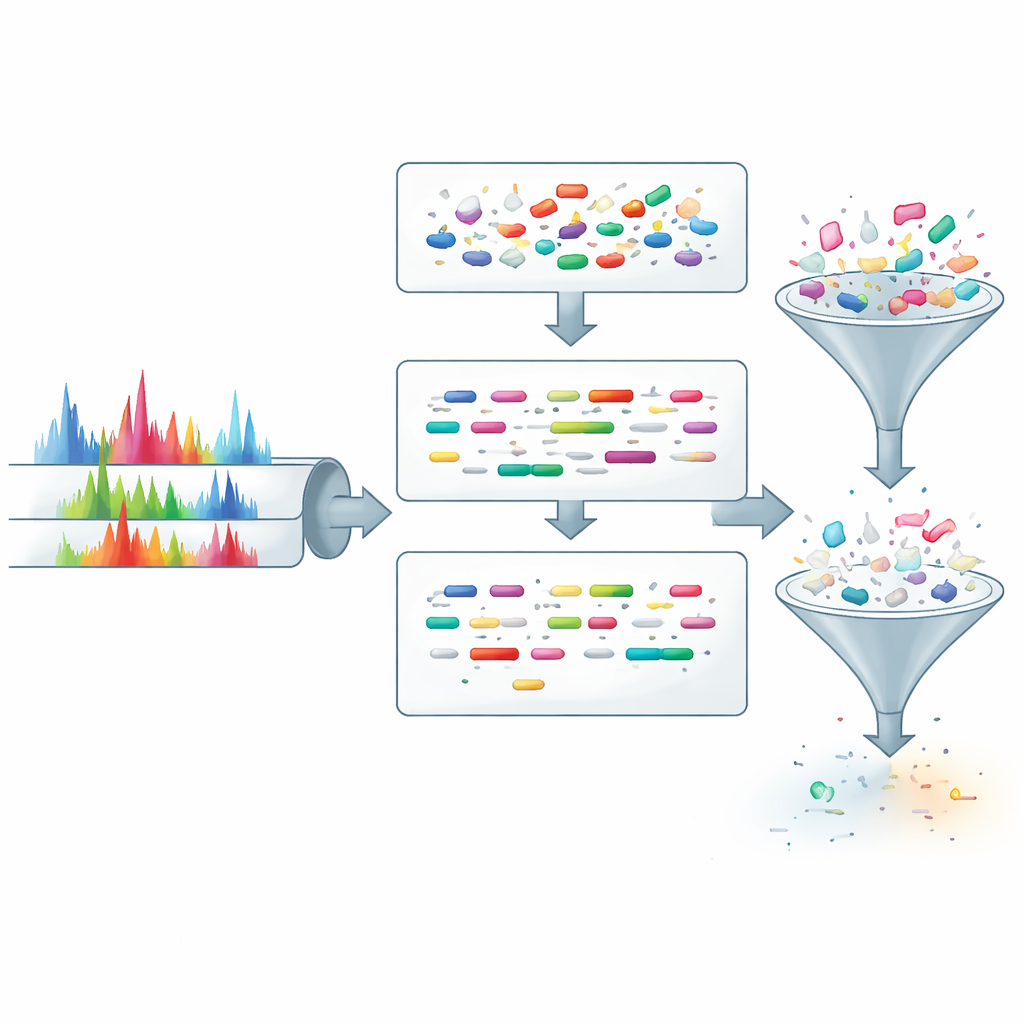
Modelin ne zaman yanlış olabileceğini bilmek
Makine öğrenimi sistemleri sıklıkla kara kutu olarak görüldüğünden, yazarlar kütle spektrometrisi verilerine özgü belirsizlik ölçümleri de geliştirirler. Bir spektrumun iç temsilinin kontrollü bozulmalar altında ne kadar değiştiğini, etrafının eğitim örnekleriyle ne kadar yoğun çevrelendiğini ve orijinal verinin yapısının öğrenilmiş uzayda ne kadar iyi korunduğunu incelerler. Bu üç metrik belirsizliğin farklı yönlerini yakalar: ölçümlerdeki gürültü ve modelin eğitim sırasında görmediği veri boşlukları. Birleştirildiklerinde, tanıdık verilerle tanımadık verileri çok yüksek doğrulukla ayırt edebilirler ve modelin en yüksek puanlı peptit eşleşmesinin muhtemelen doğru olduğu durumları işaretlemeye yardımcı olurlar.
Gelecekteki keşifler için anlamı
Günlük terimlerle ProteoRift, bir spektruma bakıp "bu muhtemelen kısa, modifikasyonsuz ve bir kesim içeren bir peptittir" ya da "bu daha uzun ve modifikasyonlu görünüyor" diyen akıllı bir kapıcı gibi çalışır ve ardından sadece uygun adayların ayrıntılı aramaya girmesine izin verir. Bunu yaparak, analizleri önemli ölçüde hızlandırır ve doğruluktan çok da ödün vermez; bu, karmaşık veya çok büyük protein veritabanları için de geçerlidir. Aynı zamanda belirsizlik metrikleri, araştırmacılara bir sonuca ne zaman güvenmeleri gerektiği veya daha fazla veri ya da model ince ayarı gerektiği konusunda daha net bir fikir verir. Bu gelişmeler bir araya geldiğinde, kütle spektrometrisini bol ve iyi karakterize edilmiş proteinlere odaklanmanın ötesine taşıyabilir ve sıklıkla en ilginç biyolojik ipuçlarını barındıran nadir ve modifikasyonlu peptitlere yeni pencereler açabilir.
Atıf: Tariq, U., Shabbir, B. & Saeed, F. End-to-end deep attention-based multitask pipeline for predicting uncertainty-quantified peptide properties from mass spectrometry data. Sci Rep 16, 13331 (2026). https://doi.org/10.1038/s41598-026-43215-2
Anahtar kelimeler: proteomik, kütle spektrometrisi, derin öğrenme, peptit tanımlama, belirsizlik tahmini