Clear Sky Science · pt
Pipeline multitarefa fim a fim baseada em atenção profunda para prever propriedades de peptídeos com quantificação de incerteza a partir de dados de espectrometria de massa
Por que esta pesquisa importa para a saúde e a biologia
A pesquisa biomédica moderna depende fortemente da espectrometria de massa para identificar quais proteínas estão presentes em nossas células e tecidos. No entanto, apesar de instrumentos poderosos e grandes bancos de dados, uma parcela surpreendente dos dados permanece sem explicação, especialmente no caso de proteínas raras ou incomuns que podem ser cruciais em doenças como câncer ou distúrbios neurológicos. Este artigo apresenta o ProteoRift, um sistema de aprendizado de máquina que ajuda a revelar mais dessa informação oculta ao prever propriedades-chave de fragmentos proteicos diretamente a partir dos dados brutos, ao mesmo tempo em que informa aos cientistas quão confiáveis são essas previsões.

O gargalo na leitura das impressões digitais das proteínas
A espectrometria de massa funciona ao fragmentar proteínas em pedaços menores chamados peptídeos e medir a massa dos fragmentos resultantes. Softwares padrão então buscam em grandes bancos de dados proteínas cujas sequências de peptídeos tenham massa calculada compatível com cada espectro observado. Para manter essa busca computacionalmente viável, a maioria das ferramentas aplica uma regra simples: considera apenas candidatos cuja massa total corresponda de perto ao valor medido. Esse filtro baseado em massa acelera o processo, mas tem um custo. Se a massa for levemente atribuída incorretamente, ou se um peptídeo apresentar uma modificação química inesperada, a resposta correta pode ser excluída antes mesmo de ser considerada, contribuindo para o grande conjunto de espectros não atribuídos e para um viés em favor de peptídeos abundantes e bem comportados.
Uma maneira mais inteligente de reduzir a busca
O ProteoRift oferece uma estratégia diferente: em vez de filtrar candidatos usando apenas a massa, ele aprende a extrair informações mais ricas de cada espectro antes de qualquer busca em banco de dados. O sistema é construído em torno de uma rede neural profunda baseada em atenção que recebe como entrada o padrão de picos em um espectro junto com detalhes básicos da aquisição. A partir disso, ele prevê simultaneamente três propriedades do peptídeo subjacente: seu comprimento, quantas vezes foi cortado durante o preparo da amostra (clivagens perdidas) e se carrega alguma modificação. Como essas tarefas são relacionadas, treiná-las em conjunto incentiva o modelo a formar uma representação interna robusta dos espectros, melhorando sua capacidade de generalizar para novos dados.
Transformando previsões em buscas mais rápidas e enxutas
Para colocar essas previsões em prática, os autores integram o ProteoRift em um pipeline fim a fim ao lado de uma ferramenta previamente desenvolvida chamada SpeCollate, que associa espectros a sequências de peptídeos em um espaço de embedding. Primeiro, o ProteoRift atribui cada espectro a uma classe definida por faixa de comprimento, número de cortes perdidos e status de modificação. Peptídeos no banco de dados são agrupados de modo similar com base em suas propriedades conhecidas. O mecanismo de busca então compara espectros apenas com peptídeos da mesma classe, em vez de vasculhar todos os peptídeos com massa semelhante. Em vários conjuntos de dados humanos e de microbioma, esse filtro direcionado reduz o espaço de candidatos em mais de 90% em teoria e proporciona acelerações práticas de aproximadamente 8 a 12 vezes em comparação com filtros baseados apenas em massa, mantendo números semelhantes de peptídeos identificados com confiança. Em alguns bancos de dados proteogenômicos e metaproteômicos muito grandes, as acelerações podem ser ainda maiores, alcançando mais de 40 vezes em testes específicos.
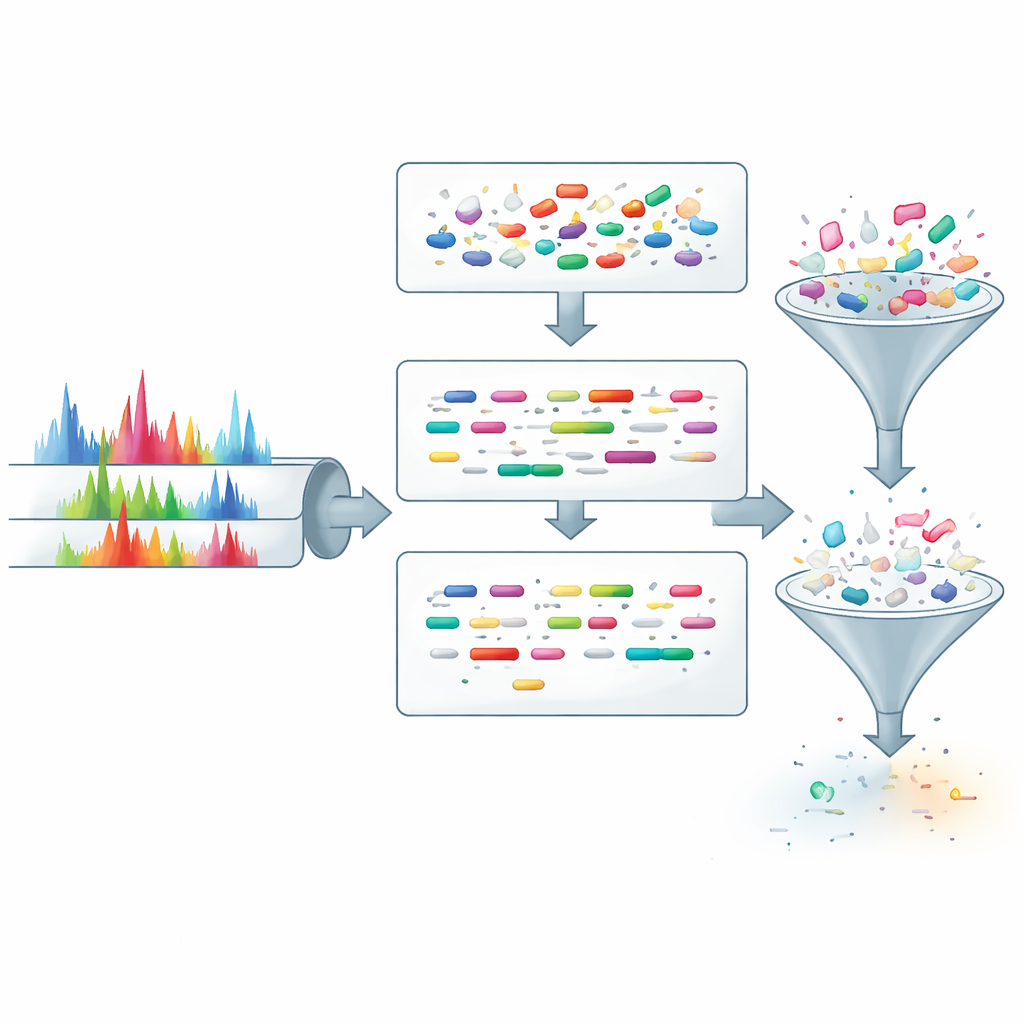
Saber quando o modelo pode estar errado
Como sistemas de aprendizado de máquina são frequentemente vistos como caixas-pretas, os autores também desenvolvem medidas de incerteza adaptadas a dados de espectrometria de massa. Eles investigam o quanto a representação interna de um espectro muda sob distorções controladas, quão densamente ele é cercado por exemplos semelhantes do conjunto de treinamento e quão bem a estrutura dos dados originais é preservada no espaço aprendido. Essas três métricas capturam diferentes aspectos da incerteza: ruído nas próprias medições e lacunas no que o modelo viu durante o treinamento. Combinadas, elas conseguem distinguir dados familiares de dados desconhecidos com alta precisão e ajudam a sinalizar casos em que a melhor correspondência de peptídeo apontada pelo modelo provavelmente está correta.
O que isso significa para descobertas futuras
Em termos práticos, o ProteoRift funciona como um porteiro inteligente que olha para um espectro e diz: “provavelmente é um peptídeo curto, sem modificação e com uma clivagem”, ou “isto parece mais longo e modificado”, e então só permite que candidatos apropriados entrem na busca detalhada. Fazendo isso, acelera a análise de forma dramática sem sacrificar muita precisão, mesmo em bancos de dados de proteínas complexos ou muito grandes. Ao mesmo tempo, suas métricas de incerteza dão aos pesquisadores uma noção mais clara de quando confiar em um resultado ou quando mais dados ou ajuste fino do modelo podem ser necessários. Juntas, essas melhorias podem ajudar a mover a espectrometria de massa além do foco atual em proteínas abundantes e bem caracterizadas e abrir novas janelas para peptídeos raros e modificados que frequentemente contêm as pistas biológicas mais interessantes.
Citação: Tariq, U., Shabbir, B. & Saeed, F. End-to-end deep attention-based multitask pipeline for predicting uncertainty-quantified peptide properties from mass spectrometry data. Sci Rep 16, 13331 (2026). https://doi.org/10.1038/s41598-026-43215-2
Palavras-chave: proteômica, espectrometria de massa, aprendizado profundo, identificação de peptídeos, estimação de incerteza