Clear Sky Science · tr
Beyin kanseri tanısı için meta-sezgisel bir algoritmaya dayalı yüksek boyutlu verilerle hibrit özellik seçimi ve sınıflandırma modeli
Beyin tümörleri için daha akıllı testler neden önemli
Beyin tümörleri en ölümcül kanserler arasında yer alır, ancak doktorlar farklı tümör türlerini hızlı ve doğru şekilde ayırt etmekte hâlâ zorluk çekiyor. Geleneksel laboratuvar testleri yavaş olabilir ve modern gen tabanlı testler, her hasta için on binlerce gen ölçümü dahil olmak üzere boğucu bir veri akışı üretebilir. Bu çalışma, bu genetik gürültü arasından tehlikeli tümörleri daha az agresif vakalardan ayırmaya yardımcı olacak küçük bir ana gen kümesini bulmak için bilgisayar tabanlı bir yöntem sunuyor; amaç daha kesin tanıyı desteklemek ve nihayetinde daha iyi tedavi kararlarına katkıda bulunmak.
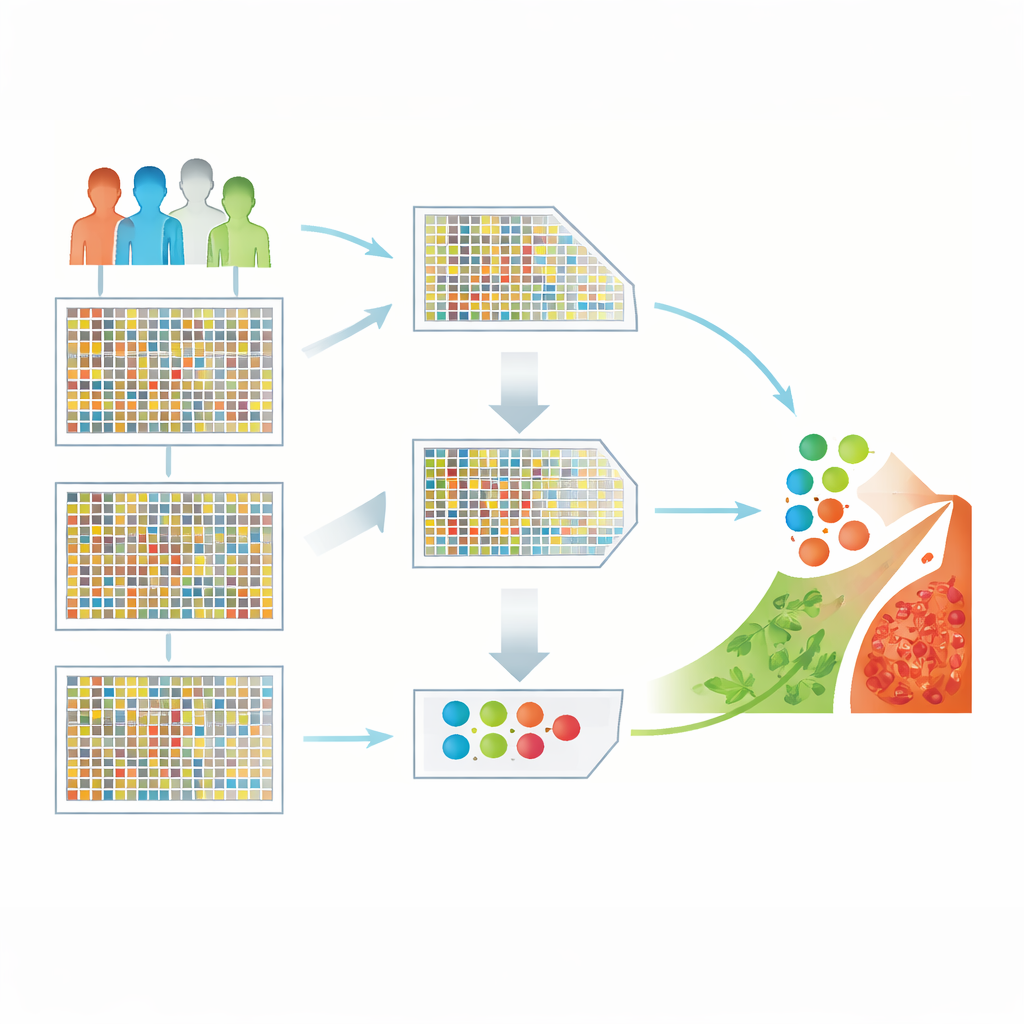
Bir gen denizini kullanılabilir ipuçlarına dönüştürmek
Araştırmacılar her biri 54.000’den fazla gen için ölçüm içeren 130 hasta örneği barındıran halka açık bir beyin kanseri veri kümesiyle çalıştı. Bu tür yüksek boyutlu veriler güçlü ama yanıltıcı olabilir: gen ölçümleri hasta sayısından çok daha fazladır ve birçok gen alakasız veya birbirinin yinelemesi niteliğindedir. Bu veriler doğrudan bir öğrenme algoritmasına beslenirse, yanıltıcı desenlere ve yeni hastalarda zayıf performansa yol açabilir. Temel zorluk, önemli biyolojik sinyalleri kaybetmeden yalnızca en bilgilendirici genleri tutmak ve geri kalanını elden çıkarmaktır.
En anlatıcı genleri bulmak için iki aşamalı yaklaşım
Bunu ele almak için ekip hibrit bir özellik seçimi hattı tasarladı. İlk adımda, “minimum tekrar, maksimum alaka” (mRMR) adlı hızlı bir istatistiksel filtre tüm genleri tarar ve beyin kanseri ile güçlü bir bağlantısı olan, aynı zamanda birbirinden olabildiğince farklı genleri tutar. Bu, gen listesini on binlerceden daha yönetilebilir bir kümeye hızla indirger. İkinci adımda ise, yırtıcı kuşların avlanma davranışından esinlenen Harris Hawks Optimization adlı arama yöntemi, her olası gen alt kümesini aday bir çözüm olarak ele alır ve en iyi sınıflandırma sonuçlarını veren kombinasyonları yineleyerek “avlar”. Bu aşamalar birlikte özgün 54.676 geni yalnızca hastalığın özünü yakalayan 50’ye düşürdü.
Makinelere daha keskin bir tanısal ayrım öğretmek
Kompakt bir gen kümesi belirlendikten sonra yazarlar beş beyin kanseri kategori arasında ve daha geniş anlamda malign ile daha az tehlikeli doku arasında ayrım yapmak için birkaç makine öğrenimi modeli eğitti. Temel modellerden biri olan destek vektör makinesi, davranışını güçlü biçimde etkileyen birkaç duyarlılık ayarına ihtiyaç duyar. Bu ayarları deneme-yanılma ile yapmak yerine ekip, en iyi ayarları sistematik olarak aramak için Parçacık Sürü Optimizasyonu, Diferansiyel Evrim ve Harris Hawks Optimization olmak üzere üç optimizasyon stratejisi kullandı. Performansı değerlendirmek için titiz, tekrarlamalı çapraz doğrulama ve modellerin küçük veri kümesini ezberlemediğini garanti etmek amacıyla bootstrap yeniden örnekleme ve öğrenme eğrisi analizi gibi ek kontroller uyguladılar.
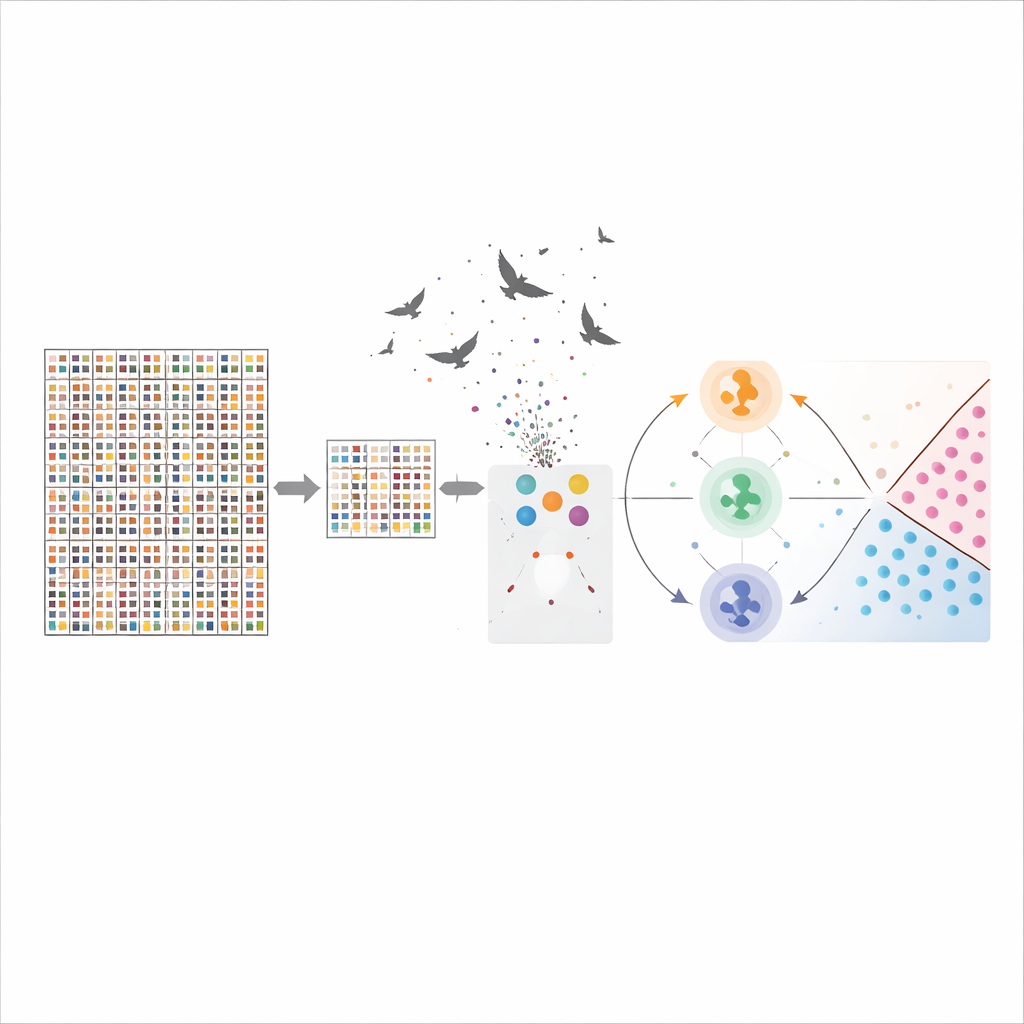
Sistemin ne kadar iyi çalıştığı ve genlerin ne anlama geldiği
Hibrit gen seçimi ve optimizasyon uygulandığında, destek vektör makinesi beyin kanseri verisinde yaklaşık %96 doğruluk sağladı ve karar ağaçları gibi daha geleneksel yöntemleri açıkça geride bıraktı. Yöntem ayrıca gen sayısını 54.000’in üzerinden 50’ye kadar düşürürken, öngörü gücünü korudu ve hatta geliştirdi. Seçilen genlerin birçoğu zaten hücre büyümesi, DNA onarımı, damarlanma veya beyin tümörlerinde bağışıklık yanıtıyla ilişkili olarak bilinmekte olup, bilgisayarın tercihlerine biyolojik güvenilirlik kazandırıyor. Bu, modelin yalnızca sınıflandırmada iyi olmadığını, aynı zamanda araştırmacılara laboratuvarda incelenmeye değer potansiyel biyobelirteçlere işaret ettiğini gösteriyor.
Bu hastalar için ne anlama gelebilir
Basitçe söylemek gerekirse, çalışma, devasa genetik veriyi küçük, anlamlı bir gen “imzasına” sıkıştırmanın mümkün olduğunu ve bunun farklı beyin tümörü türlerini yüksek güvenilirlikle ayırmaya yardımcı olduğunu gösteriyor. Çalışma hâlâ nispeten küçük bir hasta grubuna dayanıyor ve daha büyük, daha çeşitli popülasyonlarda test edilmesi gerekiyor olsa da, doğru ve yorumlanabilir, gen tabanlı daha hızlı tanı araçlarına doğru bir yol öneriyor. Doğrulanıp klinik iş akışlarına entegre edildiğinde, bu tür araçlar doktorlara tedavi seçimi yaparken daha güçlü kanıt sağlayabilir ve bilim insanlarının beyin kanserlerinin nasıl başladığı, büyüdüğü ve tedaviye nasıl yanıt verdiğini etkileme olasılığı en yüksek genlerin kısa bir listesine odaklanmalarına yardımcı olabilir.
Atıf: Manhrawy, I.I.M., Fathi, H., Alsekait, D.M. et al. Hybrid feature selection and classification model using high-dimensional data based on a metaheuristic algorithm for brain cancer diagnosis. Sci Rep 16, 11909 (2026). https://doi.org/10.1038/s41598-026-41573-5
Anahtar kelimeler: beyin kanseri tanısı, gen ekspresyonu, özellik seçimi, makine öğrenimi, biyobelirteçler