Clear Sky Science · sv
Förutsäga funktionsutfall efter stroke med förklarbar maskininlärning och integrerade data
Varför återhämtning efter stroke är så svår att förutsäga
Efter en ischemisk stroke är vissa människor åter på fötter inom månader, medan andra drabbas av bestående funktionsnedsättning. Familjer och läkare vill tidigt veta vem som sannolikt kommer att återhämta sig och vem som kan behöva mer stöd. Denna studie undersöker om moderna datorbaserade metoder, kombinerade med detaljerade blodprover, kan förutse hur väl yrkesverksamma patienter i arbetsför ålder kommer att fungera tre månader efter sin stroke — och vilka uppgifter som betyder mest för dessa prognoser.
En närmare titt på yngre strokepatienter
Forskarna använde en långvarig svensk kohortstudie som följde 600 vuxna som fått sin första ischemiska stroke i åldern 18–69, innan dagens lytiska (trombolytiska) behandlingar var rutin. Av denna grupp hade 506 patienter fullständiga data och ingen tidig återinsjuknande stroke. Läkare registrerade standardiserad klinisk information — såsom ålder, strokens svårighetsgrad och medicinsk bakgrund — och tog blodprover några dagar efter stroken. I dessa prover mätte man inte bara rutinlaboratorier utan även ett brett panel av proteiner kopplade till koagulation, inflammation, immunaktivitet och hjärnskada. Tre månader senare bedömde neurologer varje persons funktion i vardagen med en standardiserad strokeskala och grupperade dem därefter som antingen med ett gynnsamt eller ogynnsamt utfall.
Träna datorer att upptäcka återhämtningsmönster
För att se hur väl olika datormodeller kunde förutsäga utfall jämförde teamet fyra angreppssätt: två varianter av regulariserad logistisk regression (en traditionell statistisk metod), ett ensemble av beslutsträd kallat XGBoost och ett multilagerperceptron, en enkel typ av neuralt nätverk. Innan modellerna tränades hanterade man noggrant saknade data, standardiserade alla mätvärden och använde en variabelselektionmetod (Boruta) för att fokusera på de mest informativa variablerna. Man utvärderade sedan prestanda med upprepad korsvalidering, där modellerna upprepade gånger tränades på större delen av data och testades på den återstående delen. Alla fyra metoder nådde mycket liknande och hög noggrannhet, med prestationsmått som indikerade att de kunde skilja på patienter som skulle klara sig bra och de som inte skulle göra det.
Vad modellerna säger väger tyngst
Utöver noggrannheten var den centrala frågan: vilka indata drev dessa prognoser? För att besvara detta använde forskarna en förklarbar AI-metod kallad SAGE, som uppskattar hur mycket varje feature bidrar till modellens totala prestanda. I samtliga modeller stack en faktor ut över resten: svårighetsgraden av neurologiska symtom under den första veckan, sammanfattad som en strokeskattning. Patienter med mer uttalade bortfall hade avsevärt större sannolikhet att få ett dåligt utfall. Men blodmarkörer tillförde viktig nyans. Nivåer av hjärn‑härledd tau, ett protein som frigörs när nervceller skadas, framträdde som den enskilt mest informativa blodmarkören. Flera inflammationsrelaterade proteiner — såsom oncostatin M och interleukin‑6 — bidrog också, om än i mindre grad, vilket tyder på att kroppens immun- och koagulationssvar bär ytterligare ledtrådar om återhämtningen.
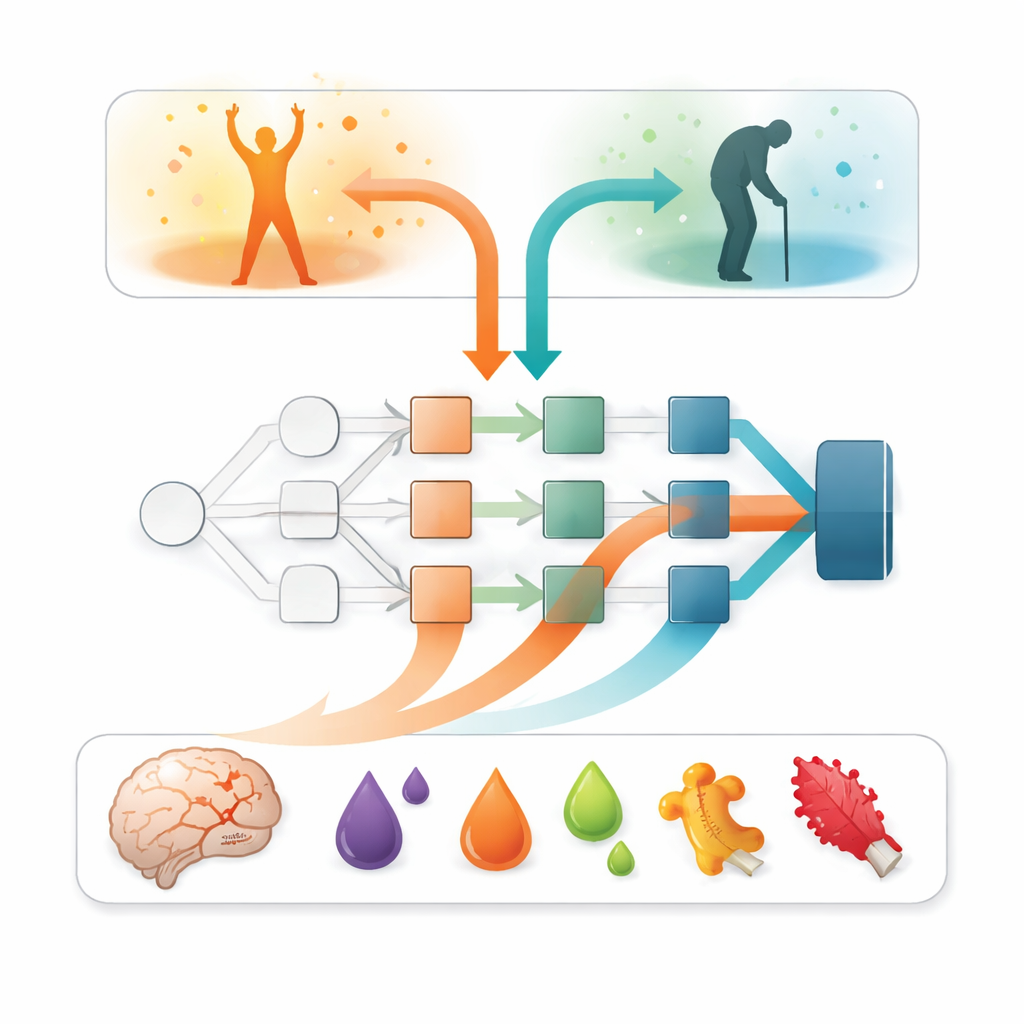
Balansen mellan komplexa modeller och verklig användning
De mer flexibla modellerna, särskilt det neurala nätverket och XGBoost, tenderade att vara bättre på att korrekt identifiera patienter som skulle få ett ogynnsamt utfall, även om det ibland skedde till priset av fler falska larm. Detta mönster antyder att subtila, icke‑linjära kombinationer av kliniska data och blodvärden bär extra prediktiv kraft som enklare linjära modeller kan missa. Samtidigt är linjära modeller fortfarande lättare att förstå och implementera i pressade kliniska miljöer. Författarna menar att att para ihop sådana prediktiva verktyg med transparenta förklaringsmetoder kan hjälpa kliniker att lita på och förfina dem, medan framtida studier med större och mer varierade patientgrupper — inklusive dem som får moderna strokebehandlingar — krävs för att bekräfta hur brett resultaten kan tillämpas.
Vad detta betyder för patienter och vårdteam
För personer som återhämtar sig efter stroke förstärker studien ett centralt budskap: tidig strokesvårighetsgrad berättar fortfarande mest, men blodtester som fångar direkt hjärnskada och inflammation kan förfina bilden. I praktiska termer kan kombinationen av sängkantsbedömningar med paneler av blodmarkörer och förklarbara maskininlärningsmodeller en dag ge mer personligt anpassade prognoser för återhämtning. Det kan i sin tur hjälpa till att skräddarsy rehabiliteringsinsatser, planera stöd i hem och arbete och att utforma kliniska prövningar som riktar sig mot dem med högst risk för långvarig funktionsnedsättning.
Citering: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Nyckelord: ischemisk stroke, maskininlärning, prognos, blodmarkörer, hjärn‑härledd tau