Clear Sky Science · pl
Prognozowanie funkcjonowania po udarze z użyciem wyjaśnialnego uczenia maszynowego i zintegrowanych danych
Dlaczego przewidywanie powrotu do zdrowia po udarze jest tak trudne
Po udarze niedokrwiennym niektórzy pacjenci wracają do samodzielnego funkcjonowania w ciągu kilku miesięcy, podczas gdy inni borykają się z trwałą niepełnosprawnością. Rodziny i lekarze chcą jak najwcześniej wiedzieć, kto ma szansę na powrót do sprawności, a kto będzie potrzebował większego wsparcia. W badaniu tym sprawdzono, czy współczesne metody obliczeniowe w połączeniu ze szczegółowymi badaniami krwi potrafią przewidzieć, jak dobrze pacjenci w wieku produkcyjnym będą funkcjonować trzy miesiące po udarze — oraz które informacje mają największe znaczenie dla tych prognoz.
Uważniejsze spojrzenie na młodszych pacjentów po udarze
Naukowcy oparli się na wieloletnim szwedzkim badaniu obejmującym 600 dorosłych, którzy przeszli pierwszy udar niedokrwienny w wieku 18–69 lat, w okresie, gdy rutynowe leczenie trombolityczne nie było powszechne. Z tej grupy 506 pacjentów miało kompletne dane i nie doznało wczesnego nawrotu udaru. Lekarze zanotowali standardowe informacje kliniczne — takie jak wiek, ciężkość udaru i wywiad chorobowy — oraz pobrali próbki krwi kilka dni po incydencie. W tych próbkach mierzono nie tylko rutynowe parametry laboratoryjne, lecz także rozbudowany panel białek związanych z krzepnięciem, stanem zapalnym, aktywnością układu odpornościowego i uszkodzeniem mózgu. Trzy miesiące później neurolodzy ocenili zdolność każdej osoby do funkcjonowania w codziennym życiu przy użyciu standardowej skali po udarze i zakwalifikowali wyniki jako korzystne lub niekorzystne.
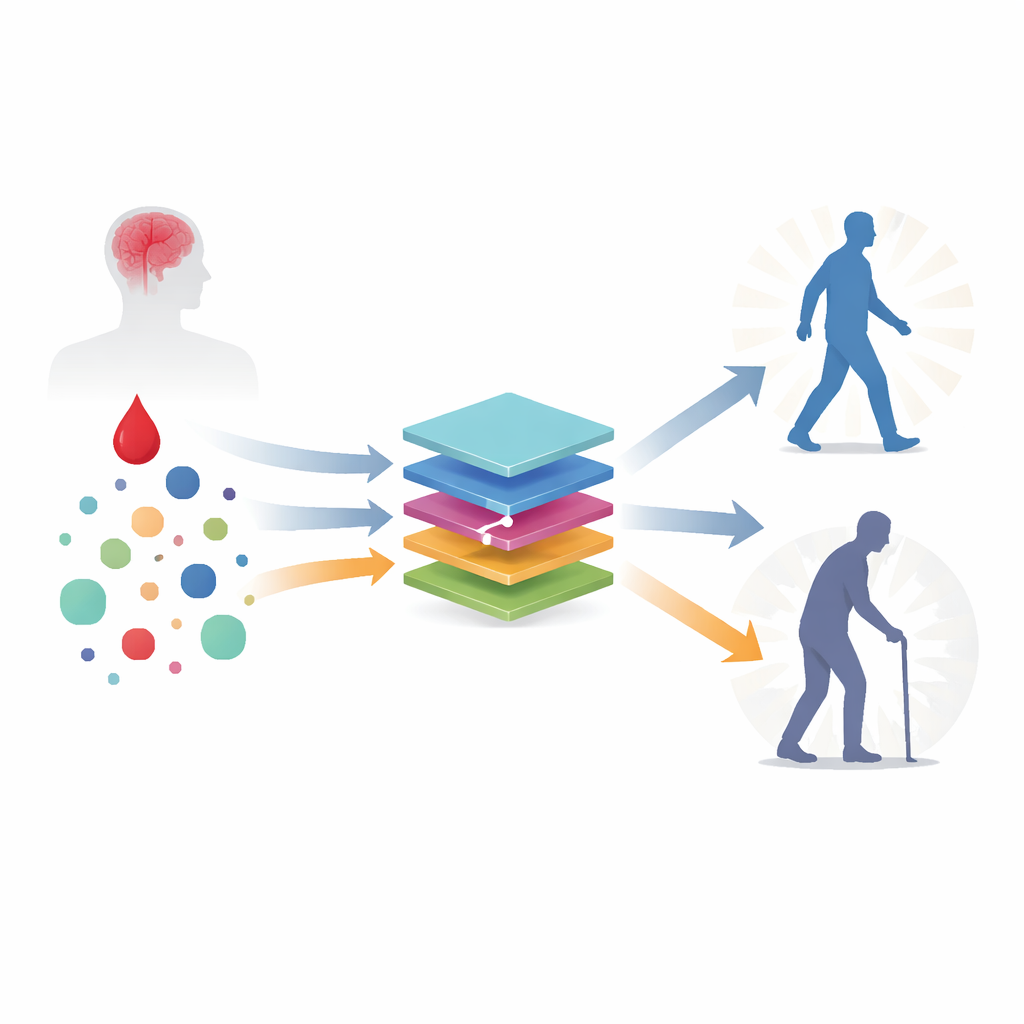
Uczenie komputerów rozpoznawania wzorców powrotu do zdrowia
Aby sprawdzić, jak dobrze różne modele komputerowe potrafią przewidzieć wynik, zespół porównał cztery podejścia: dwie formy zregularizowanej regresji logistycznej (tradycyjny statystyczny model), ensemble drzew decyzyjnych XGBoost oraz perceptron wielowarstwowy, prosty typ sieci neuronowej. Przed trenowaniem modeli starannie poradzono sobie z brakującymi danymi, wystandaryzowano wszystkie pomiary i zastosowano metodę selekcji cech (Boruta), aby skupić się na najbardziej informatywnych zmiennych. Następnie oceniano wydajność za pomocą powtarzalnej walidacji krzyżowej, wielokrotnie trenując modele na większości danych i testując je na pozostałej części. Wszystkie cztery metody osiągnęły bardzo podobną i wysoką dokładność, co wskazywało, że potrafią wiarygodnie odróżnić pacjentów, którzy poradzą sobie dobrze, od tych, którzy będą mieli gorsze wyniki.
Co modele uznały za najważniejsze
Ponad samą dokładność kluczowe było pytanie: które wejścia napędzają te prognozy? Aby na nie odpowiedzieć, badacze użyli wyjaśnialnej metody sztucznej inteligencji zwanej SAGE, która szacuje, ile każda cecha wnosi do całkowitej wydajności modelu. We wszystkich modelach jedna zmienna wyraźnie dominowała: nasilenie objawów neurologicznych w pierwszym tygodniu, podsumowane jako wynik nasilenia udaru. Pacjenci z poważniejszymi deficytami znacznie częściej mieli niekorzystne wyniki. Jednak markery krwi wniosły istotną dodatkową informację. Poziom tau pochodzenia mózgowego — białka uwalnianego przy uszkodzeniu komórek nerwowych — okazał się najważniejszym pojedynczym markrem krwi. Kilka białek związanych z zapaleniem — takich jak onkostatyna M i interleukina-6 — także się przyczyniało, choć w mniejszym stopniu, co sugeruje, że odpowiedź immunologiczna i procesy krzepnięcia niosą dodatkowe wskazówki dotyczące rokowania.
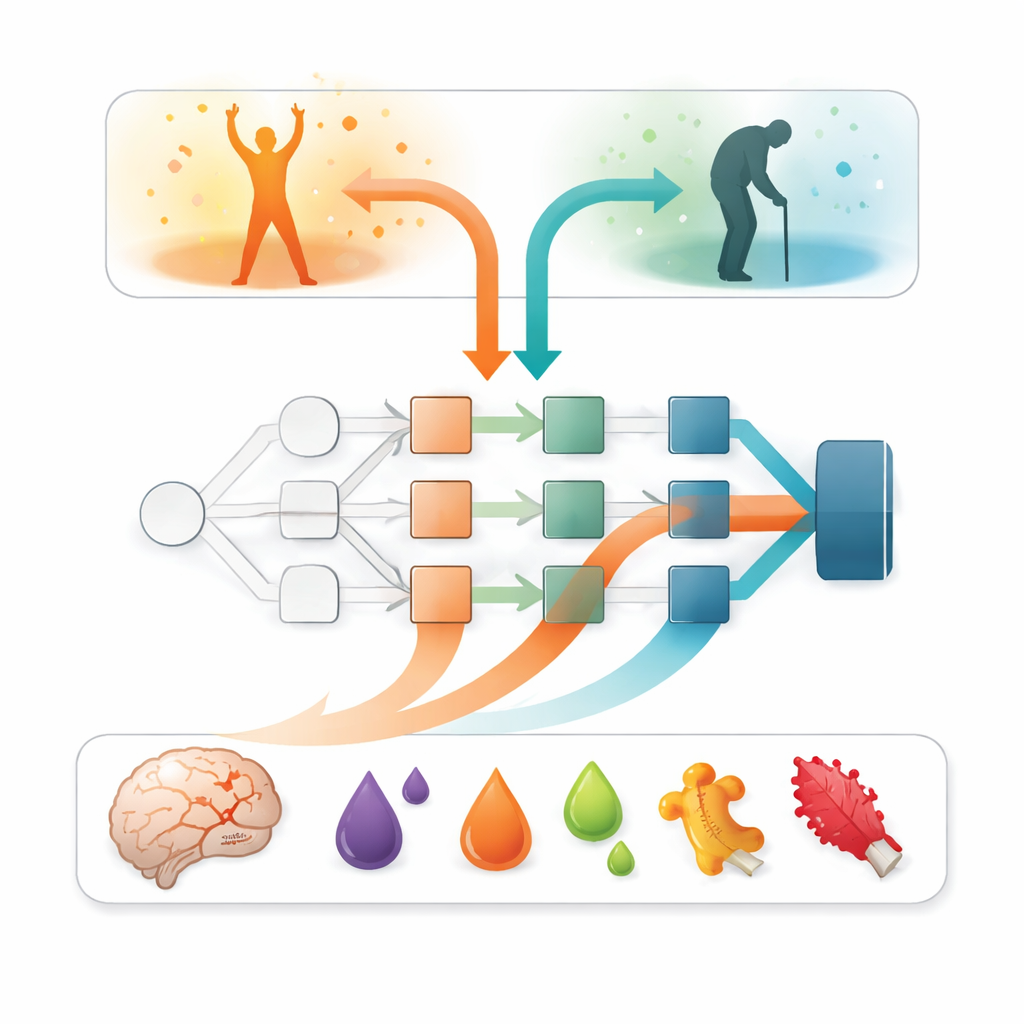
Równoważenie złożonych modeli i zastosowań w praktyce
Bardziej elastyczne modele, zwłaszcza sieć neuronowa i XGBoost, miały tendencję do lepszego wykrywania pacjentów, którzy będą mieli niekorzystny wynik, choć czasem kosztem większej liczby fałszywych alarmów. Ten wzorzec sugeruje, że subtelne, nieliniowe kombinacje danych klinicznych i krwiowych zawierają dodatkową moc predykcyjną, której proste modele liniowe mogą nie wychwycić. Jednocześnie modele liniowe pozostają łatwiejsze do zrozumienia i wdrożenia w zatłoczonych warunkach klinicznych. Autorzy argumentują, że łączenie takich narzędzi predykcyjnych z przezroczystymi metodami wyjaśniania może pomóc klinicystom zaufać im i je udoskonalać, podczas gdy przyszłe prace na większych i bardziej zróżnicowanych grupach pacjentów — w tym u osób otrzymujących współczesne terapie udarowe — będą potrzebne, aby potwierdzić szeroką użyteczność tych ustaleń.
Co to oznacza dla pacjentów i zespołów opieki
Dla osób rekonwalescencyjnych po udarze badanie podkreśla zasadniczy wniosek: wczesne nasilenie udaru wciąż wyjaśnia większą część rokowania, ale badania krwi odzwierciedlające bezpośrednie uszkodzenie mózgu i stan zapalny mogą doprecyzować obraz. W praktyce połączenie ocen przy łóżku pacjenta z panelami markerów krwi i wyjaśnialnymi modelami uczenia maszynowego może kiedyś umożliwić bardziej spersonalizowane prognozy powrotu do zdrowia. To z kolei może pomóc dostosować intensywność rehabilitacji, zaplanować wsparcie w domu i w pracy oraz projektować badania kliniczne ukierunkowane na osoby o największym ryzyku długotrwałej niepełnosprawności.
Cytowanie: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Słowa kluczowe: udar niedokrwienny, uczenie maszynowe, rokowanie, markerów krwi, tau pochodzenia mózgowego