Clear Sky Science · fr
Prédire l’évolution fonctionnelle après un AVC à l’aide d’un apprentissage automatique explicable et de données intégrées
Pourquoi la récupération après un AVC est si difficile à prévoir
Après un AVC ischémique, certaines personnes retrouvent leur autonomie en quelques mois, tandis que d’autres gardent des séquelles durables. Familles et médecins cherchent dès le départ à savoir qui a le plus de chances de récupérer et qui nécessitera un soutien accru. Cette étude examine si des méthodes informatiques modernes, associées à des analyses sanguines détaillées, peuvent prédire la capacité fonctionnelle des patients en âge actif trois mois après l’AVC — et quelles informations sont les plus déterminantes pour ces prédictions.
Regarder de plus près les patients plus jeunes
Les chercheurs se sont appuyés sur une étude suédoise de longue durée qui a suivi 600 adultes ayant eu un premier AVC ischémique entre 18 et 69 ans, à une époque où les traitements thrombolytiques n’étaient pas encore systématiques. Parmi ce groupe, 506 patients disposaient de données complètes et n’avaient pas eu de récidive précoce. Les médecins ont consigné les informations cliniques standard — âge, sévérité de l’AVC et antécédents médicaux — et prélevé des échantillons sanguins quelques jours après l’AVC. Dans ces échantillons, ils ont mesuré non seulement les analyses de routine mais aussi un large panel de protéines liées à la coagulation, à l’inflammation, à l’activité immunitaire et aux lésions cérébrales. Trois mois plus tard, des neurologues ont évalué la capacité de chaque personne à fonctionner au quotidien à l’aide d’une échelle standard pour l’AVC, puis les ont classées selon un pronostic favorable ou défavorable.
Apprendre aux ordinateurs à repérer les schémas de récupération
Pour évaluer la capacité de différents modèles informatiques à prédire le pronostic, l’équipe a comparé quatre approches : deux formes de régression logistique régularisée (outil statistique classique), un ensemble d’arbres décisionnels appelé XGBoost, et un perceptron multicouche, un type simple de réseau neuronal. Avant d’entraîner ces modèles, ils ont géré soigneusement les données manquantes, standardisé toutes les mesures et utilisé une méthode de sélection de caractéristiques (Boruta) pour se concentrer sur les variables les plus informatives. Ils ont ensuite évalué la performance par validation croisée répétée, entraînant les modèles sur la majeure partie des données et les testant sur la partie restante à plusieurs reprises. Les quatre méthodes ont atteint des performances très similaires et élevées, indiquant qu’elles pouvaient distinguer de manière fiable les patients susceptibles de bien récupérer de ceux qui ne le seraient pas.
Ce que les modèles indiquent comme le plus important
Au‑delà de la précision, la question clé était : quelles entrées expliquent ces prédictions ? Pour répondre, les chercheurs ont utilisé une méthode d’intelligence artificielle explicable appelée SAGE, qui estime la contribution de chaque variable à la performance globale du modèle. Pour l’ensemble des modèles, un facteur s’est détaché nettement : la sévérité des symptômes neurologiques durant la première semaine, résumé par un score de sévérité de l’AVC. Les patients présentant des déficits plus sévères avaient beaucoup plus de chances d’avoir un mauvais pronostic. Mais les marqueurs sanguins ont apporté un éclairage important. Le taux de tau d’origine cérébrale, une protéine libérée lors de lésions neuronales, est apparu comme le marqueur sanguin le plus informatif. Plusieurs protéines liées à l’inflammation — telles que l’oncostatine M et l’interleukine‑6 — ont également contribué, quoique dans une moindre mesure, suggérant que les réponses immunitaires et de coagulation apportent des indices supplémentaires sur la récupération.
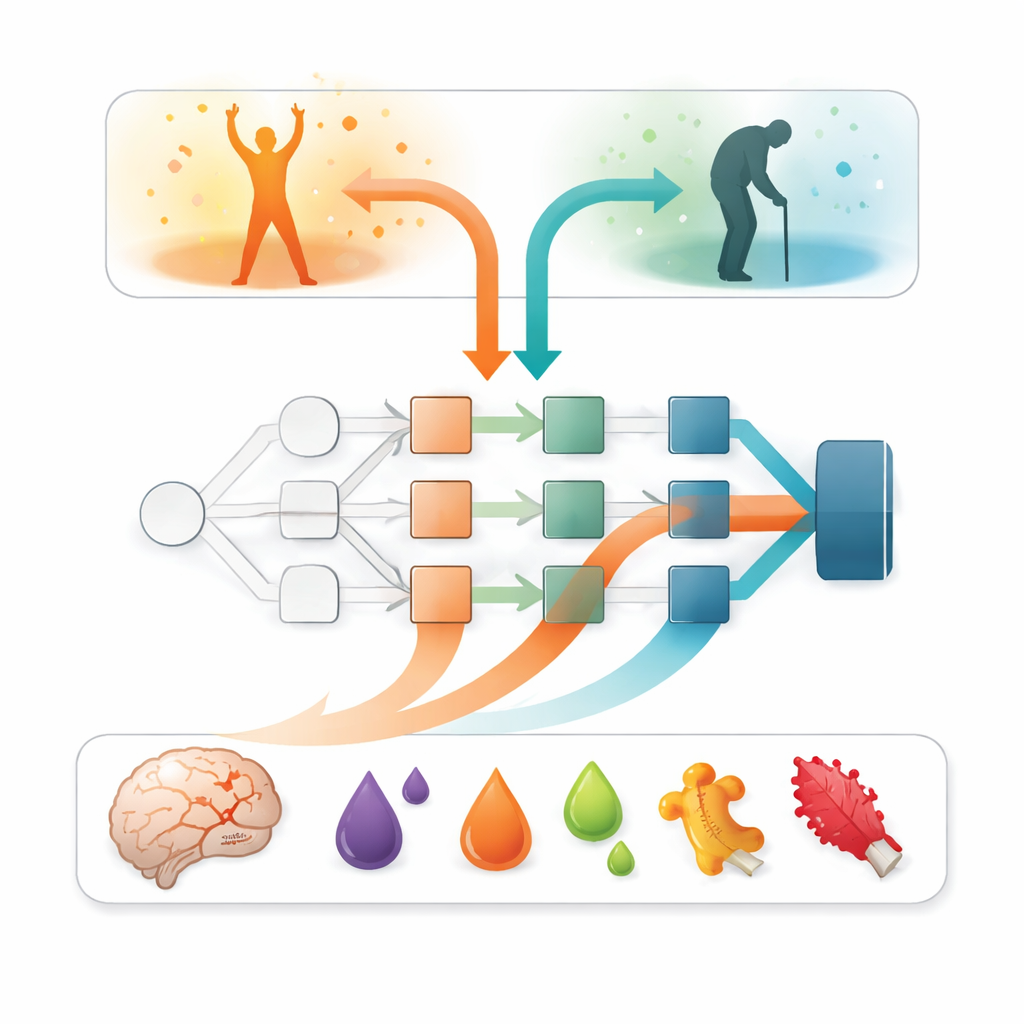
Concilier modèles complexes et usage en pratique
Les modèles plus flexibles, en particulier le réseau neuronal et XGBoost, avaient tendance à mieux identifier les patients avec un pronostic défavorable, parfois au prix d’un nombre plus élevé de faux positifs. Ce schéma suggère que des combinaisons subtiles et non linéaires de données cliniques et sanguines contiennent un pouvoir prédictif supplémentaire que les modèles linéaires simples peuvent manquer. En même temps, les modèles linéaires restent plus faciles à comprendre et à déployer dans des services cliniques chargés. Les auteurs soutiennent que l’association de tels outils prédictifs avec des méthodes d’explication transparentes pourrait aider les cliniciens à leur faire confiance et à les affiner, tandis que des travaux futurs sur des cohortes plus larges et plus diversifiées — y compris des patients ayant reçu les traitements modernes de l’AVC — seront nécessaires pour confirmer l’étendue d’application de ces résultats.
Ce que cela signifie pour les patients et les équipes soignantes
Pour les personnes en convalescence après un AVC, l’étude renforce un message central : la sévérité initiale de l’AVC reste l’indicateur principal, mais des analyses sanguines captant les lésions cérébrales directes et l’inflammation peuvent affiner le diagnostic. Concrètement, la combinaison d’évaluations au chevet, de panels de biomarqueurs sanguins et de modèles d’apprentissage automatique explicables pourrait un jour fournir des prévisions de récupération plus personnalisées. Cela pourrait à son tour aider à adapter l’intensité de la rééducation, planifier le soutien à domicile et au travail, et concevoir des essais cliniques ciblant les personnes à plus haut risque de handicap durable.
Citation: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Mots-clés: AVC ischémique, apprentissage automatique, pronostic, biomarqueurs sanguins, tau d’origine cérébrale