Clear Sky Science · es
Predicción del resultado funcional tras un ictus mediante aprendizaje automático explicable y datos integrados
Por qué es tan difícil predecir la recuperación tras un ictus
Tras un ictus isquémico, algunas personas se recuperan y vuelven a ponerse en pie en pocos meses, mientras que otras sufren discapacidad duradera. Familias y médicos desean saber pronto quién tiene probabilidad de recuperarse y quién podrá necesitar más apoyo. Este estudio explora si los métodos informáticos modernos, combinados con análisis sanguíneos detallados, pueden prever cómo funcionarán los pacientes en edad laboral tres meses después del ictus —y qué elementos de la información son los más importantes para esas predicciones.
Un vistazo más atento a pacientes más jóvenes
Los investigadores recurrieron a un estudio sueco de larga duración que siguió a 600 adultos que sufrieron un primer ictus isquémico entre los 18 y los 69 años, en una época previa a que los tratamientos trombolíticos fueran habituales. De ese grupo, 506 pacientes tenían datos completos y no presentaron recurrencia temprana del ictus. Los médicos registraron información clínica estándar —como la edad, la gravedad del ictus y los antecedentes médicos— y recogieron muestras de sangre unos días después del ictus. En esas muestras midieron no solo los valores de laboratorio de rutina, sino también un amplio panel de proteínas relacionadas con la coagulación, la inflamación, la actividad inmunitaria y el daño cerebral. Tres meses después, neurólogos evaluaron la capacidad de cada persona para desenvolverse en la vida diaria mediante una escala estandarizada del ictus y los agruparon en resultado favorable o desfavorable.
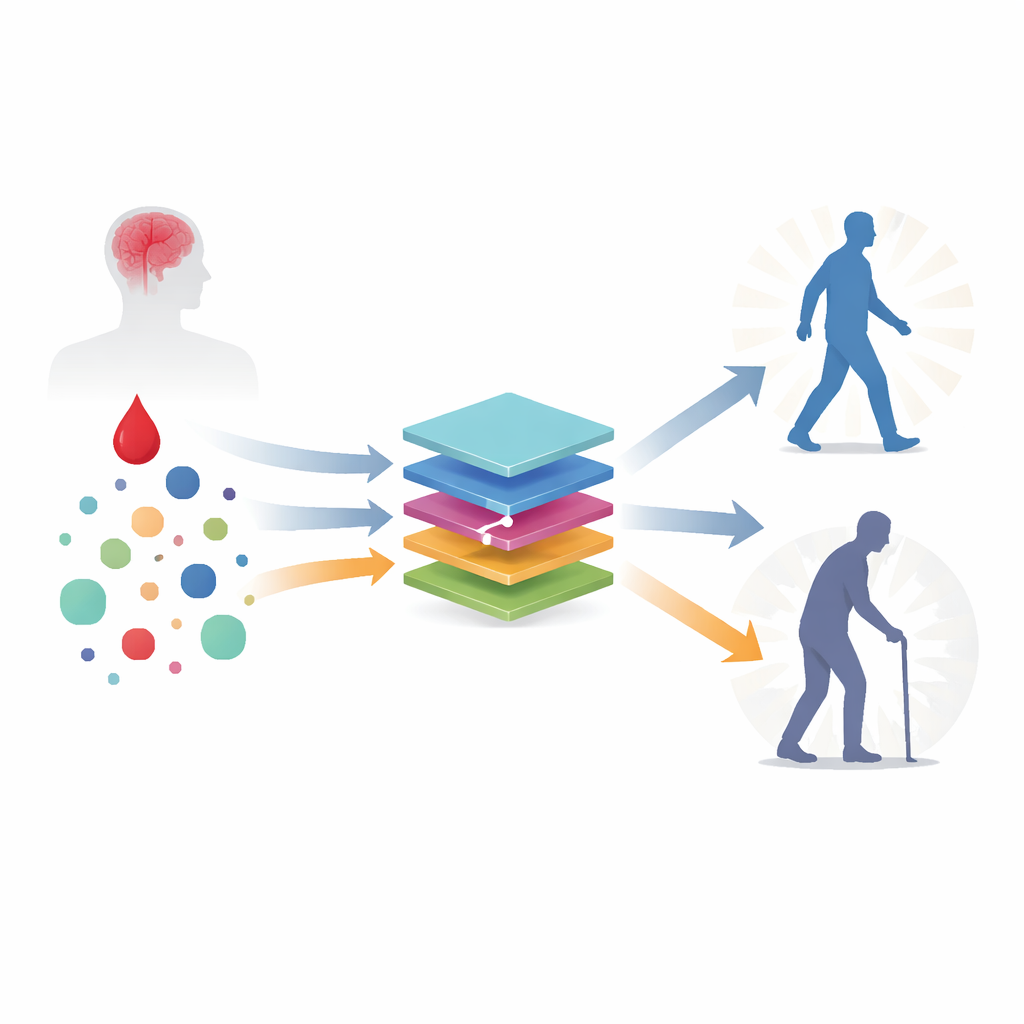
Enseñar a los ordenadores a detectar patrones de recuperación
Para evaluar qué tan bien distintos modelos informáticos podían predecir el resultado, el equipo comparó cuatro enfoques: dos formas de regresión logística regularizada (un pilar estadístico tradicional), un ensamble de árboles de decisión llamado XGBoost y un perceptrón multicapa, un tipo sencillo de red neuronal. Antes de entrenar estos modelos, gestionaron cuidadosamente los datos perdidos, estandarizaron todas las mediciones y aplicaron un método de selección de características (Boruta) para centrarse en las variables más informativas. Después evaluaron el rendimiento mediante validación cruzada repetida, entrenando los modelos en la mayor parte de los datos y probándolos en la porción restante de forma reiterada. Los cuatro métodos alcanzaron una precisión alta y muy similar, con medidas de rendimiento que indicaron que podían distinguir de forma fiable entre pacientes que mejorarían y los que no.
Qué variables dicen que importan más
Más allá de la precisión, la pregunta clave fue: ¿qué entradas estaban impulsando esas predicciones? Para responderla, los investigadores recurrieron a un método de inteligencia artificial explicable llamado SAGE, que estima cuánto contribuye cada característica al rendimiento global del modelo. En todos los modelos, un factor destacó por encima del resto: la gravedad de los síntomas neurológicos durante la primera semana, resumida como puntuación de gravedad del ictus. Los pacientes con déficits más graves tenían mucha más probabilidad de presentar un mal resultado. Pero los marcadores sanguíneos añadieron una matización importante. Los niveles de tau derivada del cerebro, una proteína liberada cuando las neuronas sufren daño, emergieron como el único marcador sanguíneo más informativo. Varias proteínas relacionadas con la inflamación —como oncostatina M e interleucina-6— también contribuyeron, aunque en menor medida, lo que sugiere que las respuestas inmunitaria y de coagulación del organismo aportan pistas adicionales sobre la recuperación.
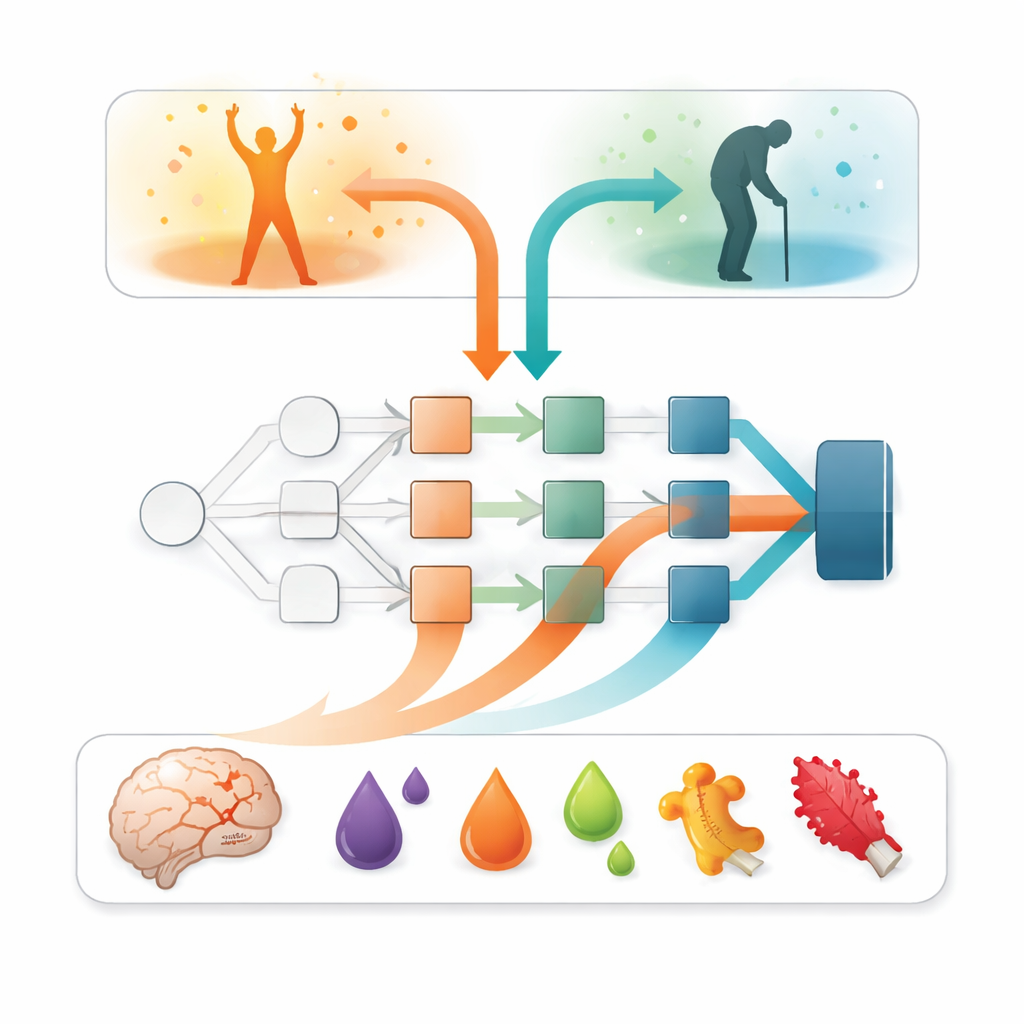
Equilibrar modelos complejos y uso en el mundo real
Los modelos más flexibles, especialmente la red neuronal y XGBoost, tendieron a identificar mejor a los pacientes que tendrían un resultado desfavorable, aunque a veces a costa de más falsos positivos. Este patrón sugiere que combinaciones sutiles y no lineales de datos clínicos y sanguíneos contienen poder predictivo adicional que los modelos lineales más sencillos pueden pasar por alto. Al mismo tiempo, los modelos lineales siguen siendo más fáciles de entender e implementar en clínicas concurridas. Los autores sostienen que combinar estas herramientas predictivas con métodos de explicación transparentes podría ayudar a que los clínicos confíen en ellas y las perfeccionen, mientras que trabajos futuros con grupos de pacientes más grandes y diversos —incluidos aquellos que reciben tratamientos de ictus modernos— serán necesarios para confirmar hasta qué punto se aplican estos hallazgos.
Qué significa esto para pacientes y equipos de cuidados
Para las personas en recuperación tras un ictus, el estudio refuerza un mensaje central: la gravedad temprana del ictus sigue contando la mayor parte de la historia, pero los análisis de sangre que captan el daño cerebral directo y la inflamación pueden afinar el panorama. En términos prácticos, combinar evaluaciones en la cabecera con paneles de biomarcadores sanguíneos y modelos de aprendizaje automático explicables podría, algún día, ofrecer pronósticos de recuperación más personalizados. Eso, a su vez, podría ayudar a ajustar la intensidad de la rehabilitación, planificar el apoyo en el hogar y en el trabajo, y diseñar ensayos clínicos dirigidos a quienes corren mayor riesgo de discapacidad a largo plazo.
Cita: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Palabras clave: ictus isquémico, aprendizaje automático, pronóstico, biomarcadores sanguíneos, tau derivada del cerebro