Clear Sky Science · it
Prevedere l’esito funzionale post-ictus usando machine learning spiegabile e dati integrati
Perché la prognosi della ripresa dopo un ictus è così difficile
Dopo un ictus ischemico, alcune persone si rimettono in piedi in pochi mesi, mentre altre si confrontano con disabilità durature. Famiglie e medici vogliono sapere fin da subito chi è più probabile che si riprenda e chi potrebbe aver bisogno di maggior supporto. Questo studio esplora se i moderni metodi computazionali, combinati con analisi del sangue dettagliate, possano prevedere quanto bene i pazienti in età lavorativa funzioneranno tre mesi dopo l’ictus — e quali informazioni sono più rilevanti per tali previsioni.
Uno sguardo più attento ai pazienti più giovani colpiti da ictus
I ricercatori si sono basati su uno studio svedese di lunga durata che ha seguito 600 adulti che hanno avuto un primo ictus ischemico tra i 18 e i 69 anni, prima che le attuali terapie trombolitiche fossero routinarie. Di questo gruppo, 506 pazienti avevano dati completi e non hanno avuto recidive precoci. I medici hanno registrato informazioni cliniche standard — come età, gravità dell’ictus e anamnesi — e hanno raccolto campioni di sangue pochi giorni dopo l’evento. In quei campioni hanno misurato non solo valori di laboratorio di routine ma anche un ampio pannello di proteine correlate alla coagulazione, all’infiammazione, all’attività immunitaria e al danno cerebrale. Dopo tre mesi, neurologi hanno valutato la capacità di ogni persona di svolgere le attività quotidiane usando una scala standard per l’ictus, quindi le hanno raggruppate in esito favorevole o sfavorevole.
Insegnare ai computer a riconoscere i modelli di recupero
Per valutare quanto bene diversi modelli computazionali potessero prevedere l’esito, il team ha confrontato quattro approcci: due forme di regressione logistica regolarizzata (un classico statistico), un insieme di alberi decisionali chiamato XGBoost e un perceptrone multistrato, un semplice tipo di rete neurale. Prima dell’addestramento hanno gestito con cura i dati mancanti, standardizzato tutte le misure e usato un metodo di selezione delle caratteristiche (Boruta) per concentrarsi sulle variabili più informative. Hanno poi valutato le prestazioni con cross-validazione ripetuta, addestrando ripetutamente i modelli sulla maggior parte dei dati e testandoli sulla parte rimanente. Tutti e quattro i metodi hanno raggiunto un’accuratezza molto simile e elevata, con misure di performance che indicano la capacità affidabile di distinguere tra pazienti che avrebbero avuto un buon esito e quelli che non lo avrebbero avuto.
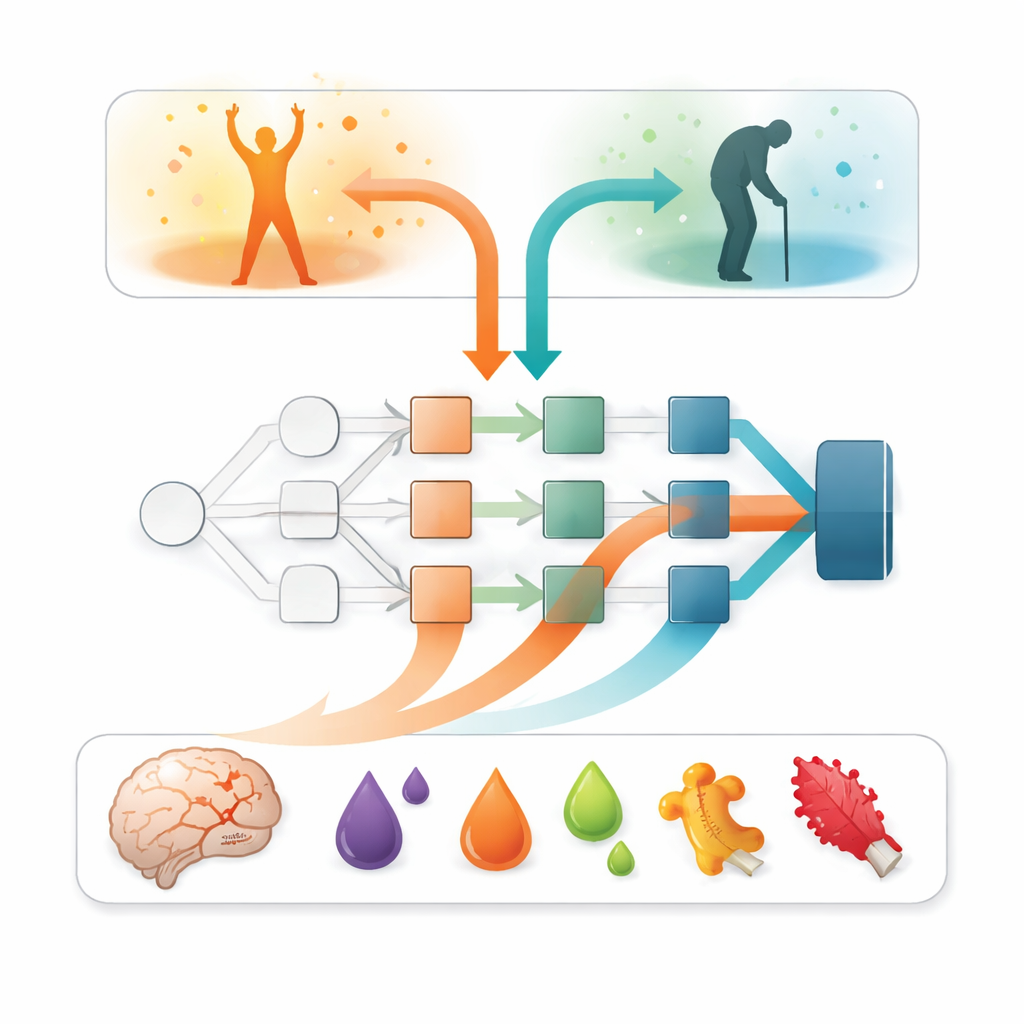
Ciò che i modelli indicano come più importante
Oltre all’accuratezza, la domanda chiave era: quali input guidano queste previsioni? Per rispondere, i ricercatori hanno utilizzato un metodo di intelligenza artificiale spiegabile chiamato SAGE, che stima quanto ciascuna caratteristica contribuisca alla performance complessiva del modello. In tutti i modelli, un fattore si è distinto nettamente: la gravità dei sintomi neurologici nella prima settimana, riassunta in un punteggio di gravità dell’ictus. I pazienti con deficit più gravi avevano molte più probabilità di avere un esito sfavorevole. Tuttavia i marcatori ematici aggiungevano importanti sfumature. I livelli di tau di origine cerebrale, una proteina rilasciata quando le cellule nervose sono danneggiate, sono emersi come il singolo marcatore ematico più informativo. Diverse proteine legate all’infiammazione — come oncostatin M e interleuchina-6 — hanno contribuito, sebbene in misura minore, suggerendo che le risposte immunitarie e di coagulazione del corpo forniscono ulteriori indizi sul recupero.
Bilanciare modelli complessi e uso nel mondo reale
I modelli più flessibili, in particolare la rete neurale e XGBoost, tendevano a essere migliori nell’identificare correttamente i pazienti che avrebbero avuto un esito sfavorevole, sebbene talvolta a costo di più falsi allarmi. Questo schema suggerisce che combinazioni sottili e non lineari di dati clinici ed ematici contengono potere predittivo aggiuntivo che i modelli lineari più semplici possono non cogliere. Allo stesso tempo, i modelli lineari restano più facili da comprendere e implementare nelle cliniche affollate. Gli autori sostengono che affiancare tali strumenti predittivi a metodi di spiegazione trasparenti potrebbe aiutare i clinici a fidarsi e a perfezionarli, mentre studi futuri con gruppi di pazienti più numerosi e diversificati — inclusi quelli trattati con le moderne terapie per l’ictus — saranno necessari per confermare quanto estesamente questi risultati siano applicabili.
Cosa significa questo per i pazienti e i team di cura
Per le persone in recupero dopo un ictus, lo studio rafforza un messaggio centrale: la gravità iniziale dell’ictus racconta ancora gran parte della storia, ma gli esami del sangue che rilevano il danno cerebrale diretto e l’infiammazione possono affinare il quadro. In termini pratici, combinare valutazioni al letto del paziente con pannelli di biomarcatori ematici e modelli di machine learning spiegabili potrebbe un giorno offrire previsioni di recupero più personalizzate. Ciò, a sua volta, potrebbe aiutare a modulare l’intensità della riabilitazione, pianificare il supporto a casa e sul lavoro e progettare trial clinici mirati a chi ha il rischio più alto di disabilità a lungo termine.
Citazione: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Parole chiave: ictus ischemico, machine learning, prognosi, biomarcatori ematici, tau di origine cerebrale