Clear Sky Science · en
Predicting post-stroke functional outcome using explainable machine learning and integrated data
Why stroke recovery is so hard to predict
After an ischemic stroke, some people are back on their feet within months, while others face lasting disability. Families and doctors want to know early on who is likely to recover and who may need more support. This study explores whether modern computer methods, combined with detailed blood tests, can forecast how well working‑age stroke patients will function three months after their stroke—and which pieces of information matter most for those predictions.
Taking a closer look at younger stroke patients
The researchers drew on a long‑running Swedish study that followed 600 adults who had a first ischemic stroke between ages 18 and 69, before today’s clot‑busting treatments were routine. From this group, 506 patients had complete data and no early repeat stroke. Doctors recorded standard clinical information—such as age, stroke severity, and medical history—and collected blood samples a few days after the stroke. In those samples, they measured not only routine lab values but also a wide panel of proteins linked to blood clotting, inflammation, immune activity, and brain injury. Three months later, neurologists rated each person’s ability to function in daily life using a standard stroke scale, then grouped them as having either a favorable or unfavorable outcome.
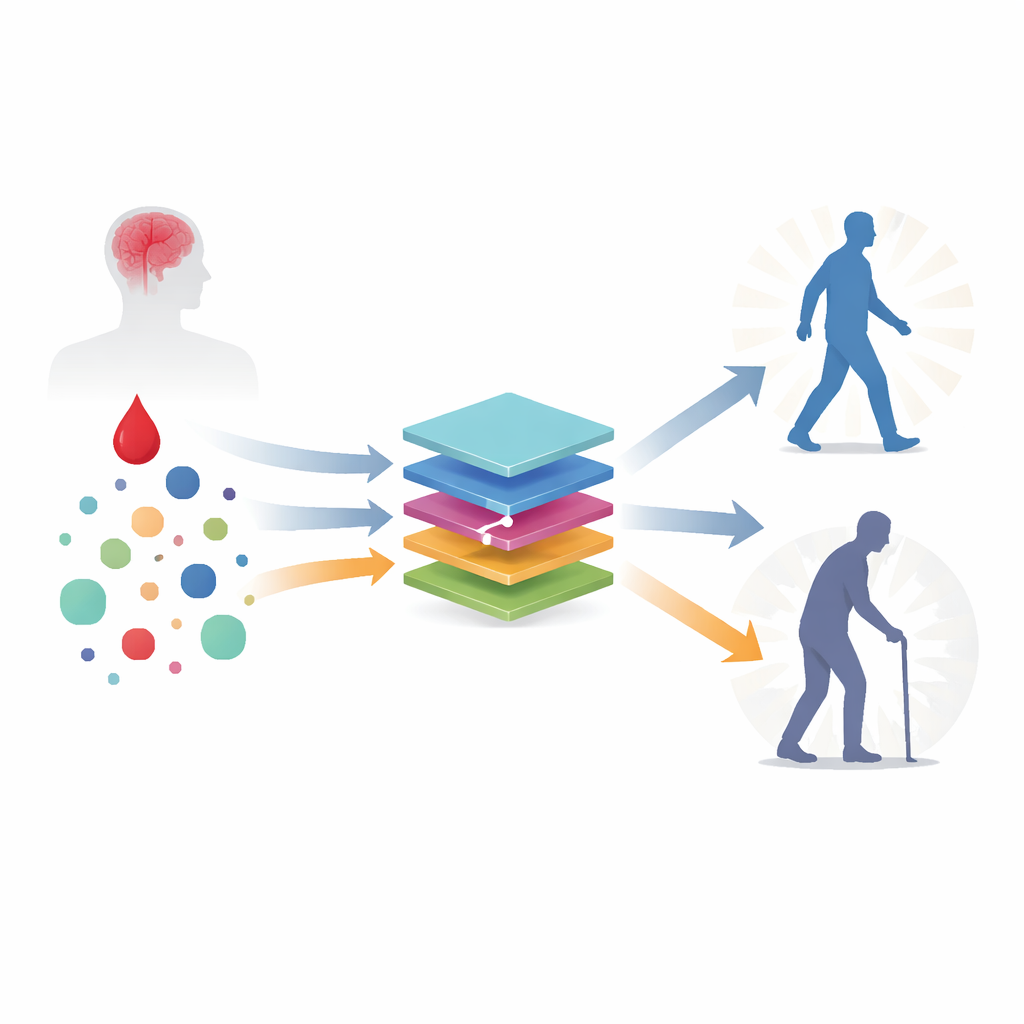
Teaching computers to spot recovery patterns
To see how well different computer models could predict outcome, the team compared four approaches: two forms of regularized logistic regression (a traditional statistical workhorse), an ensemble of decision trees called XGBoost, and a multilayer perceptron, a simple type of neural network. Before training these models, they carefully handled missing data, standardized all measurements, and used a feature‑selection method (Boruta) to focus on the most informative variables. They then evaluated performance with repeated cross‑validation, repeatedly training the models on most of the data and testing them on the remaining part. All four methods reached very similar and high accuracy, with measures of performance indicating that they could reliably distinguish between patients who would do well and those who would not.
What the models say matters most
Beyond accuracy, the key question was: which inputs were driving these predictions? To answer this, the researchers turned to an explainable artificial intelligence method called SAGE, which estimates how much each feature contributes to overall model performance. Across all models, one factor stood head and shoulders above the rest: the severity of neurological symptoms during the first week, summarized as a stroke severity score. Patients with more severe deficits were much more likely to do poorly. But blood markers added important nuance. Levels of brain‑derived tau, a protein released when nerve cells are injured, emerged as the single most informative blood marker. Several inflammation‑related proteins—such as oncostatin M and interleukin‑6—also contributed, though to a lesser extent, suggesting that the body’s immune and clotting responses carry additional clues about recovery.
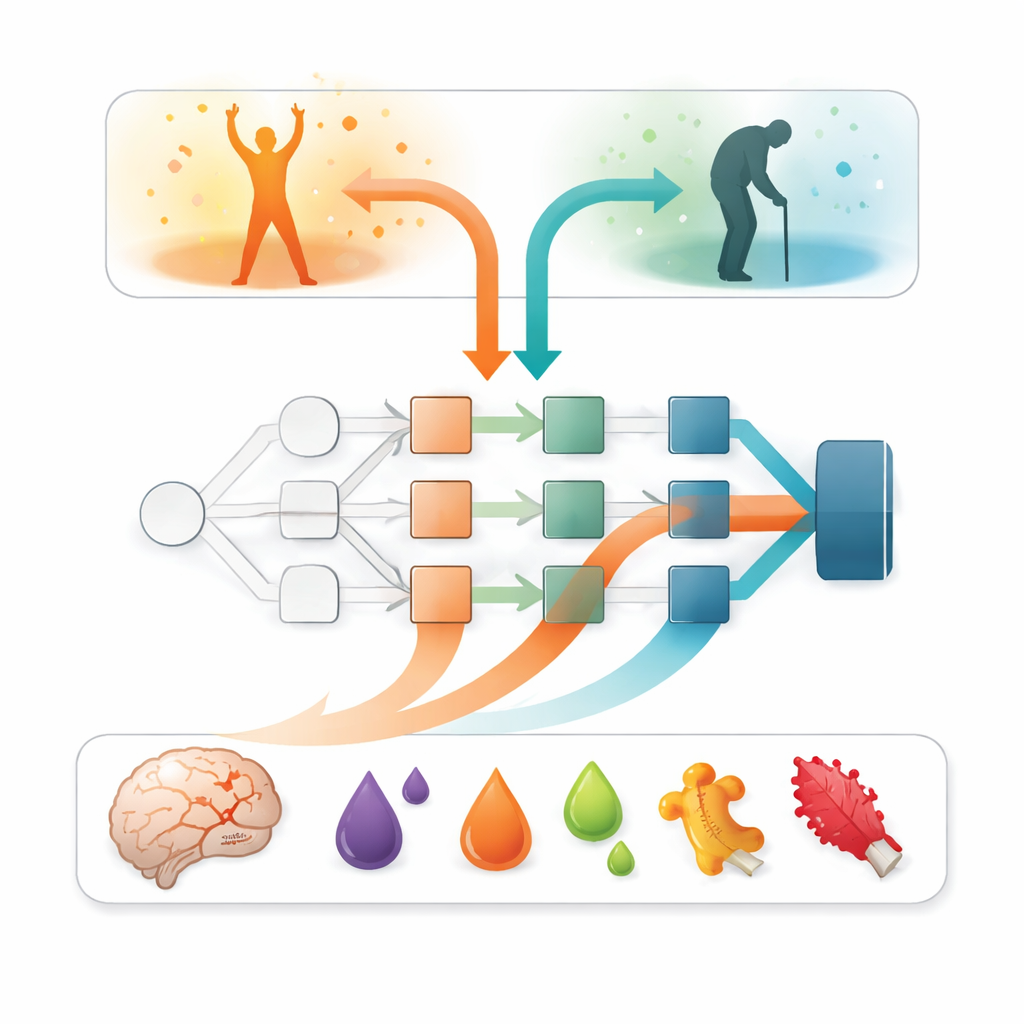
Balancing complex models and real‑world use
The more flexible models, especially the neural network and XGBoost, tended to be better at correctly identifying patients who would have an unfavorable outcome, though sometimes at the cost of more false alarms. This pattern hints that subtle, non‑linear combinations of clinical and blood data hold extra predictive power that simpler linear models can miss. At the same time, linear models remain easier to understand and implement in busy clinics. The authors argue that pairing such predictive tools with transparent explanation methods could help clinicians trust and refine them, while future work with larger and more diverse patient groups—including those receiving modern stroke treatments—will be needed to confirm how broadly these findings apply.
What this means for patients and care teams
For people recovering from stroke, the study reinforces a central message: early stroke severity still tells most of the story, but blood tests capturing direct brain injury and inflammation can sharpen the picture. In practical terms, combining bedside assessments with panels of blood biomarkers and explainable machine‑learning models could one day offer more personalized forecasts of recovery. That, in turn, might help tailor rehabilitation intensity, plan support at home and work, and design clinical trials that target those at highest risk of long‑term disability.
Citation: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Keywords: ischemic stroke, machine learning, prognosis, blood biomarkers, brain-derived tau