Clear Sky Science · ru
Прогнозирование функционального исхода после инсульта с помощью объяснимого машинного обучения и интегрированных данных
Почему восстановление после инсульта так трудно предсказать
После ишемического инсульта одни пациенты возвращаются к нормальной жизни в течение нескольких месяцев, тогда как другие сталкиваются с длительной инвалидностью. Близкие и врачи хотят как можно раньше понять, кто, скорее всего, восстановится, а кому потребуется большая поддержка. В этом исследовании изучается, могут ли современные вычислительные методы в сочетании с детальным анализом крови прогнозировать, насколько хорошо пациенты трудоспособного возраста будут функционировать через три месяца после инсульта, и какие именно данные наиболее важны для таких прогнозов.
Более внимательный взгляд на молодых пациентов с инсультом
Исследователи опирались на длительное шведское исследование, в котором наблюдали 600 взрослых, переживших первый ишемический инсульт в возрасте от 18 до 69 лет, до того как современные тромболитические методы стали рутиной. Из этой когорты у 506 пациентов были полные данные и не было раннего повторного инсульта. Врачи фиксировали стандартную клиническую информацию — такую как возраст, тяжесть инсульта и анамнез — и брали образцы крови через несколько дней после инсульта. В этих образцах измеряли не только рутинные лабораторные показатели, но и широкий набор белков, связанных с свертыванием крови, воспалением, иммунной активностью и повреждением мозга. Через три месяца неврологи оценивали способность каждого человека к повседневной деятельности по стандартной шкале для инсульта и разделяли их на группы с благоприятным или неблагоприятным исходом.
Обучение компьютеров распознавать паттерны восстановления
Чтобы выяснить, насколько хорошо разные модели прогнозируют исход, команда сравнила четыре подхода: две версии регуляризованной логистической регрессии (традиционный статистический инструмент), ансамбль решающих деревьев XGBoost и многослойный персептрон — простой тип нейронной сети. Перед обучением моделей данные аккуратно дополняли при отсутствии значений, стандартизировали все измерения и применяли метод отбора признаков Boruta, чтобы сосредоточиться на наиболее информативных переменных. Затем производили оценку качества с помощью повторной кросс-валидации, многократно обучая модели на большей части данных и тестируя на оставшейся. Все четыре метода продемонстрировали очень схожую и высокую точность, показатели показывали, что они надежно различают пациентов с благоприятным и неблагоприятным исходом.
Что модели считают наиболее важным
Помимо точности, ключевой вопрос заключался в том, какие входные данные определяют эти прогнозы. Для ответа исследователи использовали объяснимый метод ИИ SAGE, который оценивает вклад каждого признака в общую производительность модели. Во всех моделях один фактор выделялся заметно сильнее остальных: тяжесть неврологических симптомов в первую неделю, суммированная в балле тяжести инсульта. Пациенты с более выраженными нарушениями значительно чаще имели неблагоприятный исход. Однако маркеры крови добавляли важные уточнения. Уровни таау, происходящего из мозга (белка, высвобождаемого при повреждении нервных клеток), оказались самым информативным маркером крови. Несколько белков, связанных с воспалением — например онкостатин М и интерлейкин‑6 — также вносили вклад, хотя и в меньшей степени, что указывает на то, что иммунные и свертывающие реакции организма дают дополнительные подсказки о восстановлении.
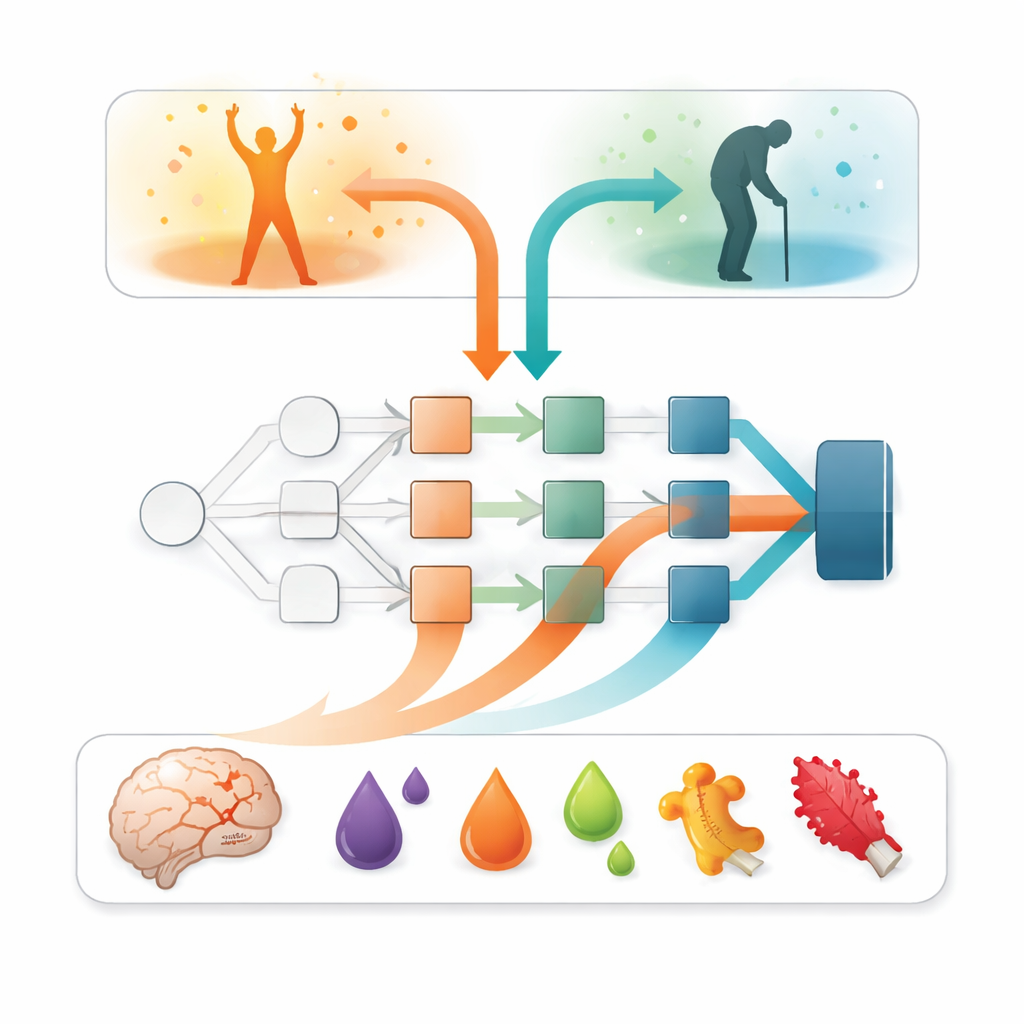
Баланс между сложными моделями и реальным использованием
Более гибкие модели, особенно нейронная сеть и XGBoost, как правило, лучше выявляли пациентов с неблагоприятным исходом, хотя иногда это сопровождалось большим числом ложных срабатываний. Такая картина намекает, что тонкие нелинейные комбинации клинических и лабораторных данных дают дополнительную предсказательную силу, которую простые линейные модели могут не уловить. В то же время линейные модели остаются более понятными и проще внедряемыми в загруженных клиниках. Авторы предполагают, что сочетание таких инструментов прогнозирования с прозрачными методами объяснения поможет клиницистам доверять им и дорабатывать их, а будущие исследования на больших и более разнообразных группах пациентов — в том числе получающих современные методы лечения инсульта — будут нужны, чтобы подтвердить широту применимости этих выводов.
Что это значит для пациентов и команд по уходу
Для людей, восстанавливающихся после инсульта, исследование подтверждает центральную мысль: ранняя тяжесть инсульта по‑прежнему объясняет большую часть прогноза, но анализы крови, фиксирующие прямое повреждение мозга и воспаление, помогут уточнить картину. На практике сочетание прикроватных оценок с панелями биомаркеров крови и объяснимыми моделями машинного обучения может в будущем предоставить более персонализированные прогнозы восстановления. Это, в свою очередь, поможет адаптировать интенсивность реабилитации, планировать поддержку дома и на работе, а также проектировать клинические испытания, нацеленные на тех, кто в наибольшей степени рискует длительной инвалидности.
Цитирование: Olsson, J., Stanne, T.M., Andersson, B. et al. Predicting post-stroke functional outcome using explainable machine learning and integrated data. Sci Rep 16, 12462 (2026). https://doi.org/10.1038/s41598-026-47814-x
Ключевые слова: ишемический инсульт, машинное обучение, прогноз, биомаркеры крови, таау, происходящий из мозга