Clear Sky Science · sv
Screenathon 2.0: mänskligt–AI-samarbete vid screening av patientgenererade hälsodata
Varför detta betyder något för vardaglig hälsforskning
Modern medicin bygger på att sålla igenom berg av vetenskapliga artiklar för att avgöra vad som verkligen fungerar. Men mängden nya studier har blivit så stor att även organiserade forskarteam har svårt att hinna med. Denna artikel beskriver ett nytt sätt att låta människor och artificiell intelligens (AI) samarbeta för att påskynda denna ”screening” av artiklar, samtidigt som mänskligt omdöme hålls i förarsätet. Tillvägagångssättet, kallat Screenathon 2.0, visar hur folkmassor av experter och smart mjukvara kan arbeta tillsammans för att hantera enorma läsuppgifter på bara några dagar.
Från ensamläsning till lagsport
Traditionellt genomför forskare systematiska översikter genom att minst två personer läser titel och abstrakt för varje artikel och avgör om den matchar deras forskningsfråga. Denna noggranna process bidrar till tillförlitliga slutsatser, men är smärtsamt långsam och svår att skala upp när antalet artiklar exploderar. Tidigare prövade samma forskargrupp att omvandla screeningen till en ”Screenathon”, där flera dussin experter arbetade sida vid sida i flera dagar för att fördela arbetsbördan. Det första evenemanget visade att lagarbete hjälper, men det förlitade sig fortfarande helt på mänsklig insats och kunde inte helt undkomma trötthet, ojämn erfarenhet och felaktiga märkningar.
Lägga till AI som en hjälpsam lagkamrat
I Screenathon 2.0 uppgraderade teamet processen genom att integrera AI direkt i arbetsflödet. De fokuserade på forskning om patientgenererade hälsodata — information som människor samlar in själva med verktyg som aktivitetsmätare, glukosmonitorer eller hälsoappar. Med det öppna programmet ASReview lärde sig AI-modellen i realtid av varje bedömning som de mänskliga granskare gjorde: varje gång en person markerade en artikel som relevant eller inte uppdaterade systemet sina interna regler och omordnade de återstående artiklarna, så att de mest lovande kom till framsidan av kön. På så sätt förblev människor beslutsfattare, medan AI fungerade som en ständigt förbättrande guide som bestämde vilka artiklar som skulle granskas härnäst.
En stor övning på två intensiva dagar
Forskarna testade detta människa–AI-partnerskap under ett tredagarsmöte i ett europeiskt hälsonätverk. 27 experter från 27 partnerorganisationer granskade nästan 7 000 vetenskapliga poster fördelade över 11 sjukdomsområden, från cancer till hjärtsjukdomar och neurologiska störningar. Första dagen fick deltagarna träning i inklusionsreglerna och en introduktion till hur AI-systemet fungerade. Andra dagen fokuserade de på intensivt, kollaborativt screeningarbete, och fortsatte ibland informellt i gemensamma utrymmen. I slutet hade de markerat 487 poster som relevanta och mer än 6 000 som irrelevanta, med några personer som granskade bara ett fåtal artiklar och andra som bearbetade tusentals — allt för att mata de delade AI-modellerna för varje sjukdomstema.
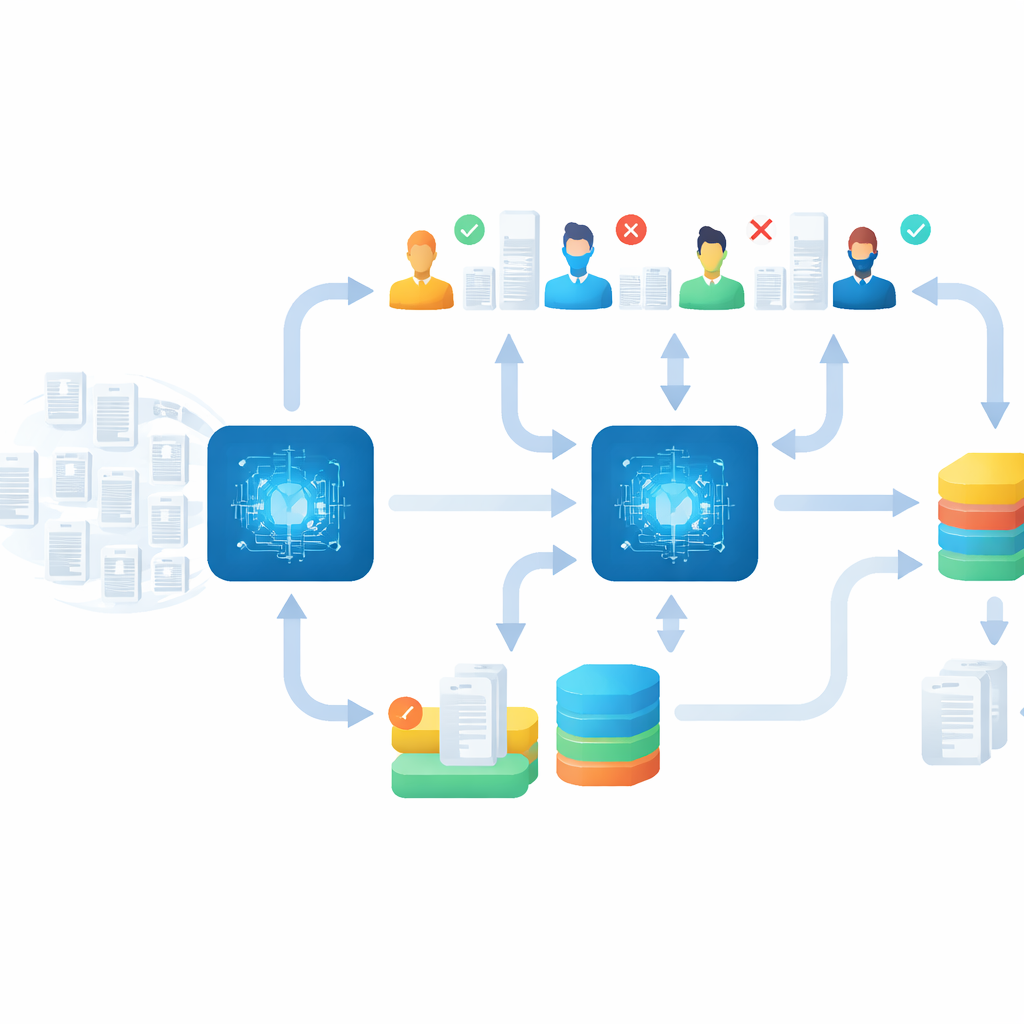
Kontroll av maskin–människa-resultaten
Hastighet skulle vara värdelöst om viktiga studier missades, så teamet byggde en stark ”eftervård” för resultaten. När huvudaktiviteten var över tillbringade de flera veckor med att kontrollera och förfina resultaten. De omlokalerade artiklar som hamnat i fel sjukdomsgrupp, läste om osäkra fall och körde ytterligare screeningsrundor med strikta stoppregler, till exempel att fortsätta tills dussintals obrutna irrelevanta artiklar dök upp. Slutligen använde de en särskild metod för att gå igenom tidigare avvisade poster som kunde ha märkts felaktigt. Denna noggranna uppstädningsfas avslöjade över 200 ytterligare relevanta studier över ämnena och visade att snabb, AI-assisterad screening fortfarande kan kombineras med grundlig kvalitetskontroll.
Hur människor upplevde att arbeta med AI
Under hela evenemanget fyllde deltagarna i enkäter om sin tilltro, motivation och förtroende för AI-assisterad granskning. Sammantaget rapporterade de hög motivation och nöjdhet med upplevelsen, och mer än hälften sade att de föredrog AI-stödd screening framför helt traditionella metoder. Viktigt är att deras förtroende för AI-stödd granskning ökade efter att de faktiskt arbetat med systemet. Många berömde mjukvarans enkelhet och tydlighet, även om de också föreslog förbättringar som bättre filtreringsalternativ och mer transparenta visuella signaler om hur AI prioriterade artiklar.
Vad detta nya tillvägagångssätt lär oss
För en allmän läsare är huvudbudskapet att utmaningen att hinna med medicinsk forskning inte kräver ett val mellan människor och maskiner. Screenathon 2.0 visar att en blandning av expertomdöme och adaptiv AI kan hjälpa forskarteam att snabbt hitta de mest relevanta studierna utan att tumma på omsorg och tillsyn. AI påskyndar sökandet, men människor fattar fortfarande slutliga beslut och granskar resultatet. Med gedigen utbildning och robusta efterkontroller kan denna typ av människa–AI-partnerskap göra insamling av bevis snabbare, mer tillförlitlig och mer hållbar i takt med att hälsoinformationen fortsätter att växa.
Citering: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Nyckelord: systematiska översikter, mänskligt–AI-samarbete, patientgenererade hälsodata, aktiv inlärning, litteraturscreening