Clear Sky Science · it
Screenathon 2.0: screening collaborativo umano–IA applicato ai dati sanitari generati dai pazienti
Perché questo è importante per la ricerca sanitaria quotidiana
La medicina moderna dipende dall’esaminare montagne di articoli scientifici per capire cosa funziona davvero. Ma il numero di nuovi studi è cresciuto così tanto che persino i team di ricerca organizzati faticano a stare al passo. Questo articolo descrive un nuovo modo di far collaborare persone e intelligenza artificiale (IA) per accelerare il “screening” degli articoli, mantenendo comunque il giudizio umano al comando. L’approccio, chiamato Screenathon 2.0, mostra come folle di esperti e software intelligenti possano lavorare insieme per affrontare enormi compiti di lettura in pochi giorni.
Dalla lettura in solitaria a uno sport di squadra
Tradizionalmente, i ricercatori conducono revisioni sistematiche facendo leggere il titolo e il riassunto di ogni articolo ad almeno due persone, che decidono se corrisponde alla domanda di studio. Questo processo accurato aiuta a garantire conclusioni affidabili, ma è dolorosamente lento e difficile da scalare con l’esplosione del numero di articoli. In precedenza, lo stesso gruppo di ricerca aveva trasformato lo screening in un “Screenathon”, in cui decine di esperti lavoravano fianco a fianco per diversi giorni per dividere il carico di lavoro. Quel primo evento dimostrò che il lavoro di squadra aiuta, ma si basava ancora interamente sul lavoro umano e non poteva sfuggire completamente a fatica, esperienza disomogenea e errori di etichettatura.
Aggiungere l’IA come compagno utile
In Screenathon 2.0, il team ha aggiornato il processo integrando l’IA direttamente nel flusso di lavoro. Si sono concentrati sulla ricerca sui dati sanitari generati dai pazienti—informazioni che le persone raccolgono da sole usando strumenti come tracker di attività, monitor della glicemia o app per la salute. Utilizzando il programma open source ASReview, il modello di IA ha imparato in tempo reale da ogni giudizio dei revisori umani: ogni volta che una persona segnava un articolo come rilevante o non rilevante, il sistema aggiornava le sue regole interne e riorganizzava gli articoli rimanenti, spingendo in cima alla lista quelli più promettenti. In questo modo gli umani sono rimasti i decisori, mentre l’IA ha funzionato come una guida in continuo miglioramento, scegliendo quali articoli controllare per primi.
Un grande esperimento in due giorni intensi
I ricercatori hanno testato questa collaborazione umano–IA durante una riunione di tre giorni di un consorzio sanitario europeo. Ventisette esperti provenienti da 27 organizzazioni partner hanno selezionato quasi 7.000 record scientifici distribuiti su 11 aree patologiche, dal cancro alle malattie cardiache e neurologiche. Il primo giorno i partecipanti hanno ricevuto formazione sulle regole di inclusione e un’introduzione al funzionamento del sistema IA. Il secondo giorno si sono concentrati su uno screening collaborativo intensivo, talvolta proseguendo in modo informale anche negli spazi comuni. Alla fine avevano etichettato 487 record come rilevanti e oltre 6.000 come non rilevanti, con alcune persone che hanno esaminato solo pochi articoli e altre che ne hanno processati migliaia, alimentando modelli IA condivisi per ciascun argomento di malattia.
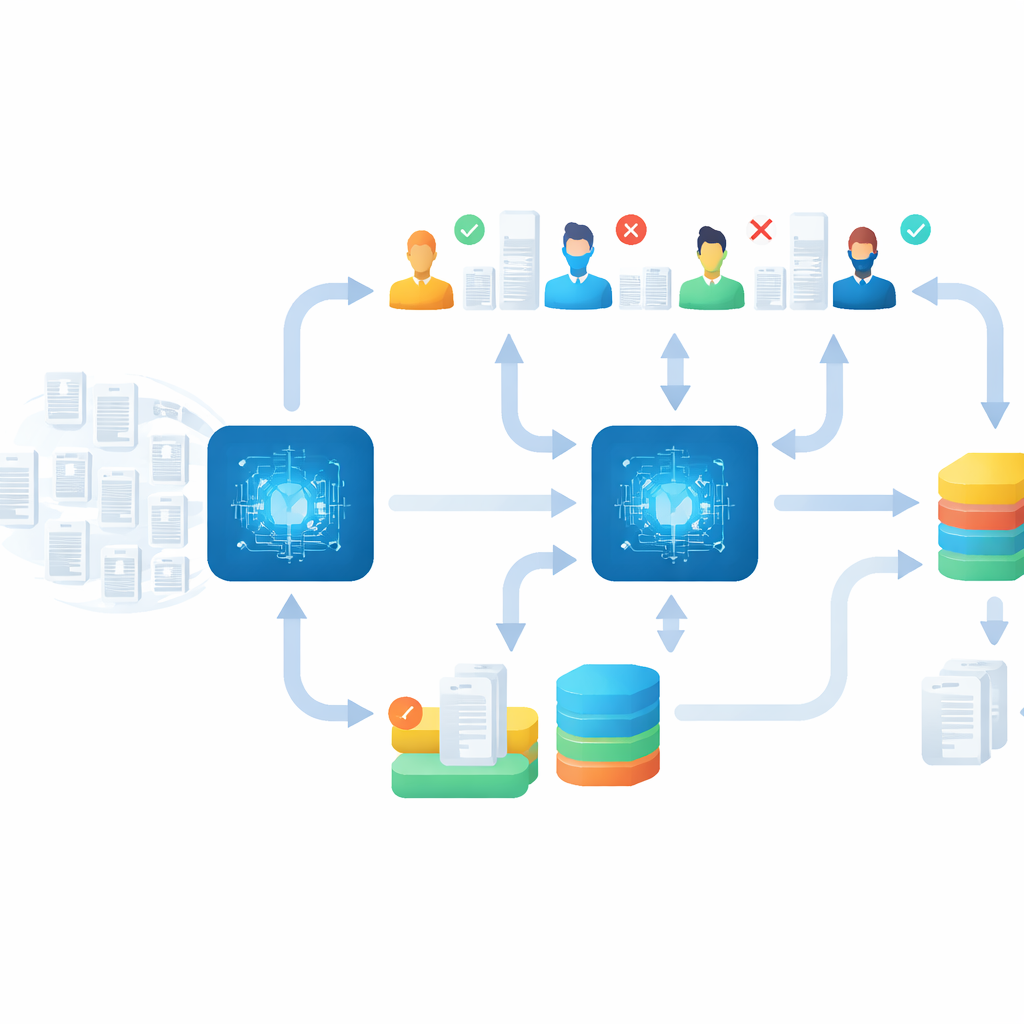
Verificare l’output macchina–uomo
La velocità da sola sarebbe priva di senso se studi importanti venissero persi, quindi il team ha costruito una solida fase di «follow-up». Terminato l’evento principale, hanno impiegato diverse settimane per controllare e perfezionare i risultati. Hanno riallocato articoli assegnati al gruppo di malattia sbagliato, riletto i casi incerti e eseguito ulteriori round di screening usando regole di arresto rigorose, per esempio continuando fino a quando non apparivano decine di articoli irrilevanti consecutivi. Infine, hanno utilizzato un metodo speciale per riesaminare i record precedentemente scartati che potevano essere stati etichettati in modo errato. Questa accurata fase di pulizia ha portato alla luce oltre 200 studi rilevanti aggiuntivi nei vari argomenti, dimostrando che uno screening veloce assistito dall’IA può comunque essere abbinato a un accurato controllo di qualità.
Come si sono sentite le persone nel lavorare con l’IA
Durante l’evento i partecipanti hanno compilato questionari sulla fiducia, la motivazione e la fiducia nella revisione assistita dall’IA. Nel complesso hanno riportato elevata motivazione e soddisfazione per l’esperienza, e più della metà ha dichiarato di preferire lo screening assistito dall’IA rispetto ai metodi totalmente tradizionali. Importante, la loro fiducia nella revisione supportata dall’IA è aumentata dopo aver effettivamente lavorato con il sistema. Molti hanno elogiato la semplicità e la chiarezza del software, pur suggerendo miglioramenti come migliori opzioni di filtraggio e indizi visivi più trasparenti su come l’IA stava dando priorità agli articoli.
Cosa ci insegna questo nuovo approccio
Per il lettore generale, il messaggio chiave è che la sfida di stare al passo con la ricerca medica non richiede una scelta tra esseri umani e macchine. Screenathon 2.0 dimostra che combinare il giudizio degli esperti con un’IA adattiva può aiutare i team di ricerca a trovare rapidamente gli studi più rilevanti senza sacrificare cura e supervisione. L’IA accelera la ricerca, ma gli esseri umani prendono ancora le decisioni finali e verificano i risultati. Con una solida formazione e controlli post-evento robusti, questo tipo di collaborazione umano–IA potrebbe rendere la raccolta di evidenze più rapida, più affidabile e più sostenibile man mano che le informazioni sanitarie continuano a crescere.
Citazione: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Parole chiave: revisioni sistematiche, collaborazione umano–IA, dati sanitari generati dai pazienti, apprendimento attivo, selezione della letteratura