Clear Sky Science · pl
Screenathon 2.0: współpraca człowiek–AI przy przesiewaniu danych zdrowotnych generowanych przez pacjentów
Dlaczego to ma znaczenie dla codziennych badań zdrowotnych
Współczesna medycyna opiera się na przeszukiwaniu olbrzymich ilości artykułów naukowych, aby ustalić, co naprawdę działa. Jednak napływ nowych badań stał się tak duży, że nawet zorganizowane zespoły badawcze mają trudności, by nadążyć. Artykuł opisuje nowe podejście do współpracy ludzi i sztucznej inteligencji (AI), które przyspiesza to „przesiewanie” publikacji, zachowując jednocześnie ludzkie osądy jako ostateczne. Podejście nazwane Screenathon 2.0 pokazuje, jak grupy ekspertów i inteligentne oprogramowanie mogą współpracować, by poradzić sobie z ogromnymi zadaniami czytelniczymi w ciągu zaledwie kilku dni.
Od indywidualnego czytania do gry zespołowej
Tradycyjnie badacze przeprowadzają przeglądy systematyczne, mając przynajmniej dwie osoby czytające tytuł i streszczenie każdego artykułu i decydujące, czy odpowiada on pytaniu badawczemu. Ten staranny proces pomaga zapewnić wiarygodne wnioski, ale jest bolesnie powolny i trudny do skalowania wraz ze wzrostem liczby publikacji. Wcześniej ta sama grupa badaczy przetestowała przekształcenie przesiewania w „Screenathon”, gdzie dziesiątki ekspertów pracowały równolegle przez kilka dni, dzieląc zadania. To pierwsze wydarzenie udowodniło, że praca zespołowa pomaga, ale nadal opierała się wyłącznie na wysiłku ludzkim i nie eliminuje zmęczenia, zróżnicowanego doświadczenia ani błędów etykietowania.
Dodanie AI jako pomocnika w zespole
W Screenathon 2.0 zespół ulepszył proces, integrując AI bezpośrednio w przebieg pracy. Skupili się na badaniach dotyczących danych zdrowotnych generowanych przez pacjentów — informacji, które ludzie zbierają sami przy użyciu narzędzi takich jak opaski fitness, glukometry czy aplikacje zdrowotne. Korzystając z otwartoźródłowego programu ASReview, model AI uczył się w czasie rzeczywistym na podstawie każdego osądu dokonywanego przez recenzentów: za każdym razem, gdy ktoś oznaczył artykuł jako istotny lub nieistotny, system aktualizował swoje wewnętrzne reguły i przetasowywał pozostałe publikacje, przesuwając najbardziej obiecujące na początek kolejki. W ten sposób ludzie pozostawali decydentami, a AI działała jako stale doskonalący się przewodnik, sugerując, które artykuły sprawdzić jako następne.
Wielki eksperyment w dwa intensywne dni
Badacze przetestowali to partnerstwo człowiek–AI podczas trzydniowego spotkania europejskiego konsorcjum zdrowotnego. Dwudziestu siedmiu ekspertów z 27 organizacji partnerskich przesiewało niemal 7 000 rekordów naukowych rozdzielonych na 11 obszarów chorobowych, od nowotworów po schorzenia serca i zaburzenia neurologiczne. Pierwszego dnia uczestnicy otrzymali szkolenie dotyczące kryteriów włączenia i wprowadzenie do działania systemu AI. Drugiego dnia skupili się na intensywnym, współpracującym przesiewaniu, czasem kontynuując nieformalnie w przestrzeniach wspólnych. Na koniec oznaczyli 487 rekordów jako istotne i ponad 6 000 jako nieistotne — niektórzy przeglądali tylko garstkę artykułów, inni tysiące, a wszystkie ich decyzje zasilały wspólne modele AI dla każdego tematu chorobowego.
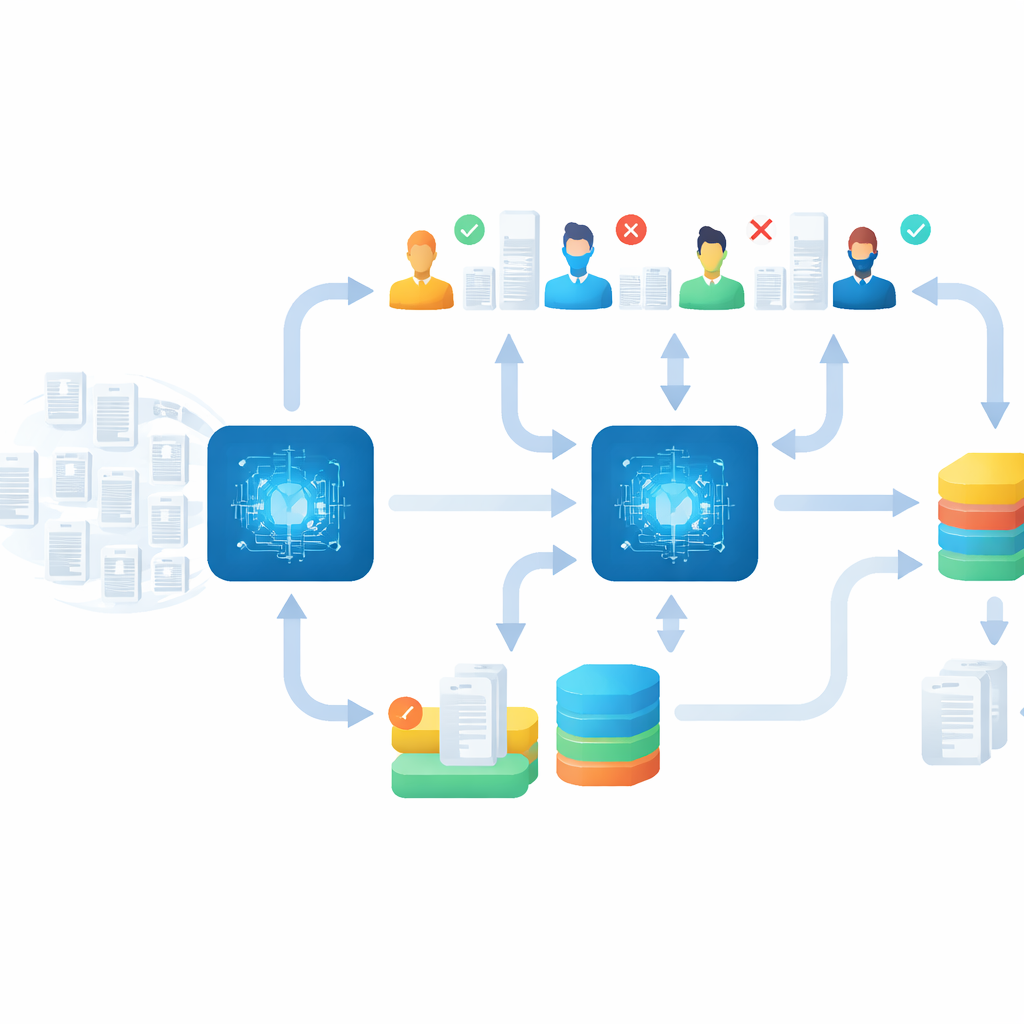
Weryfikacja wyników maszyny i ludzi
Samo tempo byłoby bezwartościowe, gdyby przez to pominięto ważne badania, dlatego zespół zaplanował solidną fazę „opieki po”. Po zakończeniu głównego wydarzenia spędzili kilka tygodni na sprawdzaniu i dopracowywaniu rezultatów. Przyporządkowywali ponownie artykuły umieszczone w niewłaściwych grupach chorobowych, ponownie czytali niepewne przypadki i przeprowadzili dodatkowe rundy przesiewania z rygorystycznymi regułami zatrzymywania, na przykład kontynuując do momentu pojawienia się dziesiątek nieprzerwanych nieistotnych rekordów. Wreszcie zastosowali specjalną metodę ponownego sprawdzenia wcześniej odrzuconych rekordów, które mogły zostać błędnie oznaczone. Ta staranna faza porządkowania ujawniła ponad 200 dodatkowych istotnych badań w różnych tematach, pokazując, że szybkie, wspomagane AI przesiewanie może iść w parze z dokładną kontrolą jakości.
Jak osoby oceniały pracę z AI
Podczas całego wydarzenia uczestnicy wypełniali ankiety dotyczące swojej pewności, motywacji i zaufania do recenzowania wspieranego przez AI. Ogólnie zgłaszali wysoką motywację i satysfakcję z doświadczenia, a ponad połowa stwierdziła, że woli przesiewanie wspomagane AI od metod w pełni tradycyjnych. Co ważne, ich zaufanie do recenzowania z wsparciem AI wzrosło po tym, jak faktycznie pracowali z systemem. Wielu chwaliło prostotę i czytelność oprogramowania, choć sugerowali też ulepszenia, takie jak lepsze opcje filtrowania i bardziej przejrzyste wskazówki wizualne pokazujące, jak AI priorytetyzuje artykuły.
Co mówi nam to nowe podejście
Dla czytelnika ogólnego kluczowy przekaz jest taki: nadążanie za badaniami medycznymi nie wymaga wyboru między ludźmi a maszynami. Screenathon 2.0 pokazuje, że połączenie fachowego osądu z adaptacyjną AI może pomóc zespołom badawczym szybko odnaleźć najistotniejsze badania bez rezygnacji z dbałości i nadzoru. AI przyspiesza poszukiwania, ale ostateczne decyzje i weryfikację podejmują ludzie. Przy solidnym szkoleniu i rygorystycznych kontrolach pośrednich taka współpraca człowiek–AI może sprawić, że gromadzenie dowodów stanie się szybsze, bardziej wiarygodne i bardziej zrównoważone w miarę dalszego wzrostu informacji zdrowotnych.
Cytowanie: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Słowa kluczowe: przeglądy systematyczne, współpraca człowiek–AI, dane zdrowotne generowane przez pacjentów, uczenie aktywne, przesiewanie literatury