Clear Sky Science · en
Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data
Why this matters for everyday health research
Modern medicine depends on sifting through mountains of scientific papers to figure out what really works. But the volume of new studies has grown so large that even organized research teams struggle to keep up. This article describes a new way of teaming up people and artificial intelligence (AI) to speed up this “screening” of papers, while still keeping human judgment in charge. The approach, called Screenathon 2.0, shows how crowds of experts and smart software can work together to handle huge reading tasks in just a few days.
From solo reading to team sport
Traditionally, researchers carry out systematic reviews by having at least two people read the title and summary of each paper and decide whether it matches their study question. This careful process helps ensure trustworthy conclusions, but it is painfully slow and hard to scale as the number of papers explodes. Earlier, the same group of researchers tried turning screening into a “Screenathon,” where dozens of experts worked side by side for several days to divide the workload. That first event proved that teamwork helps, but it still relied entirely on human effort and could not fully escape fatigue, uneven experience, and labeling mistakes.
Adding AI as a helpful teammate
In Screenathon 2.0, the team upgraded the process by weaving AI directly into the workflow. They focused on research about patient-generated health data—information people collect themselves using tools like fitness trackers, glucose monitors, or health apps. Using the open-source program ASReview, the AI model learned in real time from every judgment the human reviewers made: each time a person marked a paper as relevant or not, the system updated its internal rules and reshuffled the remaining papers, pushing the most promising ones to the front of the queue. In this way, humans remained the decision-makers, while the AI acted as an ever-improving guide, deciding which papers should be checked next.
A large experiment in two busy days
The researchers tested this human–AI partnership during a three-day meeting of a European health consortium. Twenty-seven experts from 27 partner organizations screened nearly 7,000 scientific records spread across 11 disease areas, from cancer to heart conditions and neurological disorders. On the first day, participants received training on the inclusion rules and an introduction to how the AI system worked. On the second day, they focused on intensive collaborative screening, sometimes even continuing informally in shared spaces. By the end, they had labeled 487 records as relevant and more than 6,000 as irrelevant, with some people screening only a handful of papers and others processing thousands, all feeding into shared AI models for each disease topic.
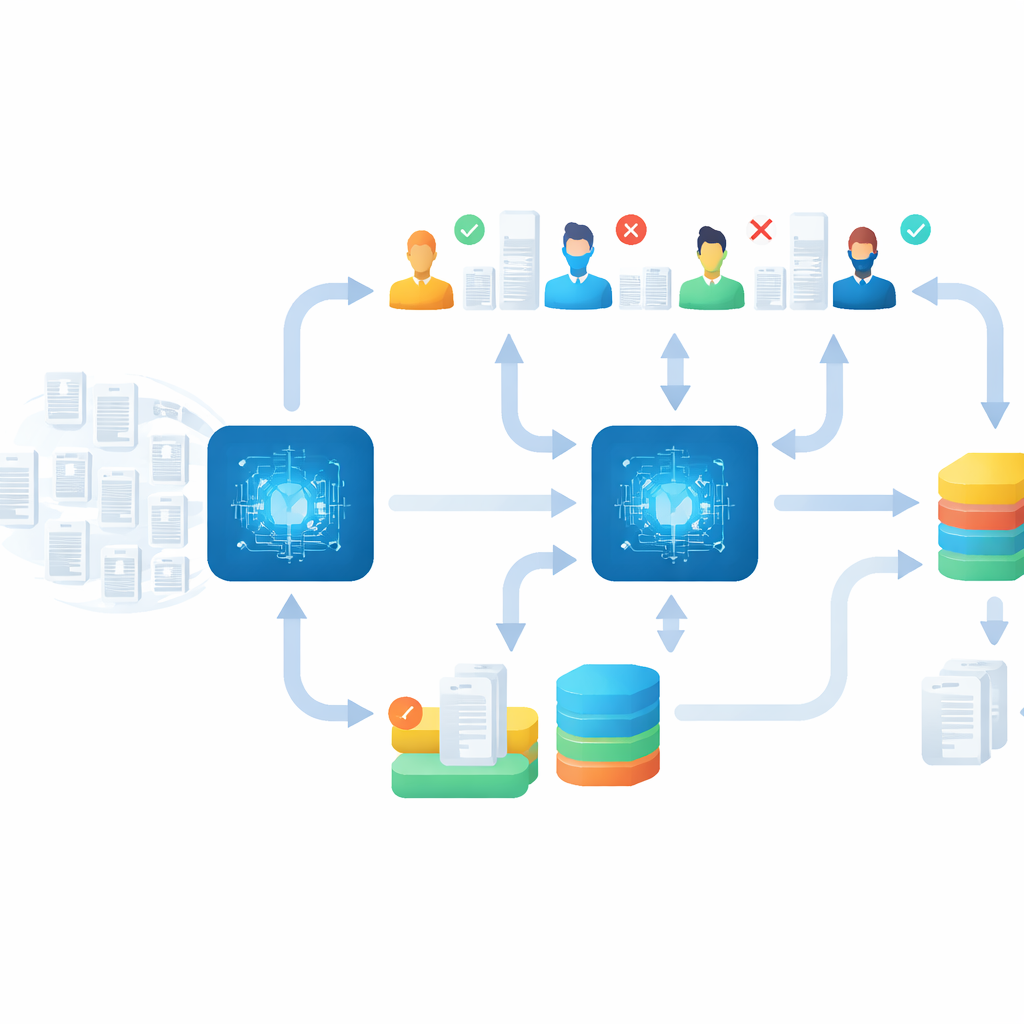
Checking the machine–human output
Speed alone would be meaningless if important studies were missed, so the team built a strong “aftercare” phase. Once the main event ended, they spent several weeks checking and refining the results. They re-assigned papers that had been placed in the wrong disease group, re-read uncertain cases, and ran additional rounds of screening using strict stopping rules, such as continuing until dozens of unbroken irrelevant papers appeared. Finally, they used a special method to re-examine previously rejected records that might have been labeled incorrectly. This careful clean-up phase uncovered more than 200 additional relevant studies across the topics, demonstrating that fast, AI-assisted screening can still be paired with thorough quality control.
How people felt about working with AI
Throughout the event, participants completed surveys about their confidence, motivation, and trust in AI-assisted reviewing. Overall, they reported high motivation and satisfaction with the experience, and more than half said they preferred AI-aided screening over fully traditional methods. Importantly, their trust in AI-supported reviewing increased after they had actually worked with the system. Many praised the simplicity and clarity of the software, though they also suggested improvements such as better filtering options and more transparent visual cues about how the AI was prioritizing papers.
What this new approach tells us
For a general reader, the key message is that the challenge of keeping up with medical research does not require choosing between humans and machines. Screenathon 2.0 shows that blending expert judgment with adaptive AI can help research teams quickly find the most relevant studies without sacrificing care and oversight. The AI speeds up the hunt, but humans still make the final calls and check the results. With strong training and robust post-checks, this kind of human–AI partnership could make evidence gathering faster, more reliable, and more sustainable as health information continues to grow.
Citation: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Keywords: systematic reviews, human–AI collaboration, patient-generated health data, active learning, literature screening