Clear Sky Science · nl
Screenathon 2.0: mens–AI samenwerkend screenen toegepast op door patiënten gegenereerde gezondheidsgegevens
Waarom dit belangrijk is voor alledaags gezondheidsonderzoek
Moderne geneeskunde hangt af van het doorzoeken van bergen wetenschappelijke artikelen om te bepalen wat echt werkt. Maar de hoeveelheid nieuwe studies is zo enorm gegroeid dat zelfs georganiseerde onderzoeksteams moeite hebben om bij te blijven. Dit artikel beschrijft een nieuwe manier om mensen en kunstmatige intelligentie (AI) samen te laten werken om het ‘screenen’ van artikelen te versnellen, terwijl menselijke oordeelsvorming leidend blijft. De aanpak, Screenathon 2.0 genoemd, laat zien hoe groepen experts en slimme software samen enorme leesklussen in slechts enkele dagen aankunnen.
Van solistisch lezen naar teamsport
Traditioneel voeren onderzoekers systematische reviews uit door ten minste twee mensen de titel en samenvatting van elk artikel te laten lezen en te beslissen of het past bij hun onderzoeksvraag. Dit zorgvuldige proces helpt betrouwbare conclusies te waarborgen, maar het is pijnlijk traag en moeilijk schaalbaar nu het aantal artikelen explodeert. Eerder probeerde dezelfde onderzoeksgroep van screening een ‘Screenathon’ te maken, waarbij tientallen experts enkele dagen naast elkaar werkten om de werklast te verdelen. Dat eerste evenement toonde aan dat teamwork helpt, maar het steunde nog volledig op menselijke inzet en kon niet volledig ontsnappen aan vermoeidheid, ongelijke ervaring en labelfouten.
AI toevoegen als behulpzame teamgenoot
In Screenathon 2.0 verbeterde het team het proces door AI direct in de workflow te weven. Ze concentreerden zich op onderzoek naar door patiënten gegenereerde gezondheidsgegevens — informatie die mensen zelf verzamelen met hulpmiddelen zoals fitness-trackers, glucosesensoren of gezondheidsapps. Met het open-sourceprogramma ASReview leerde het AI-model realtime van elk oordeel dat menselijke beoordelaars maakten: elke keer dat iemand een artikel als relevant of niet relevant markeerde, werkte het systeem zijn interne regels bij en herschikte de overgebleven artikelen, waarbij de meest veelbelovende naar voren werden geschoven. Op deze manier bleven mensen de beslissers, terwijl de AI fungeerde als een voortdurend verbeterende gids die bepaalde welke artikelen als volgende gecontroleerd moesten worden.
Een groot experiment in twee drukke dagen
De onderzoekers testten dit mens–AI partnerschap tijdens een driedaagse bijeenkomst van een Europees gezondheidsconsortium. Zevenentwintig experts van 27 partnerorganisaties screenden bijna 7.000 wetenschappelijke records verspreid over 11 ziektegebieden, van kanker tot hartaandoeningen en neurologische stoornissen. Op de eerste dag kregen deelnemers training over de inclusieregels en een introductie over hoe het AI-systeem werkte. Op de tweede dag richtten ze zich op intensieve gezamenlijke screening, soms zelfs informeel verder in gedeelde ruimtes. Aan het eind hadden ze 487 records als relevant gemarkeerd en meer dan 6.000 als irrelevant, waarbij sommige mensen slechts een handvol artikelen screenden en anderen duizenden verwerkten, allemaal invoedend in gedeelde AI-modellen per ziekteonderwerp.
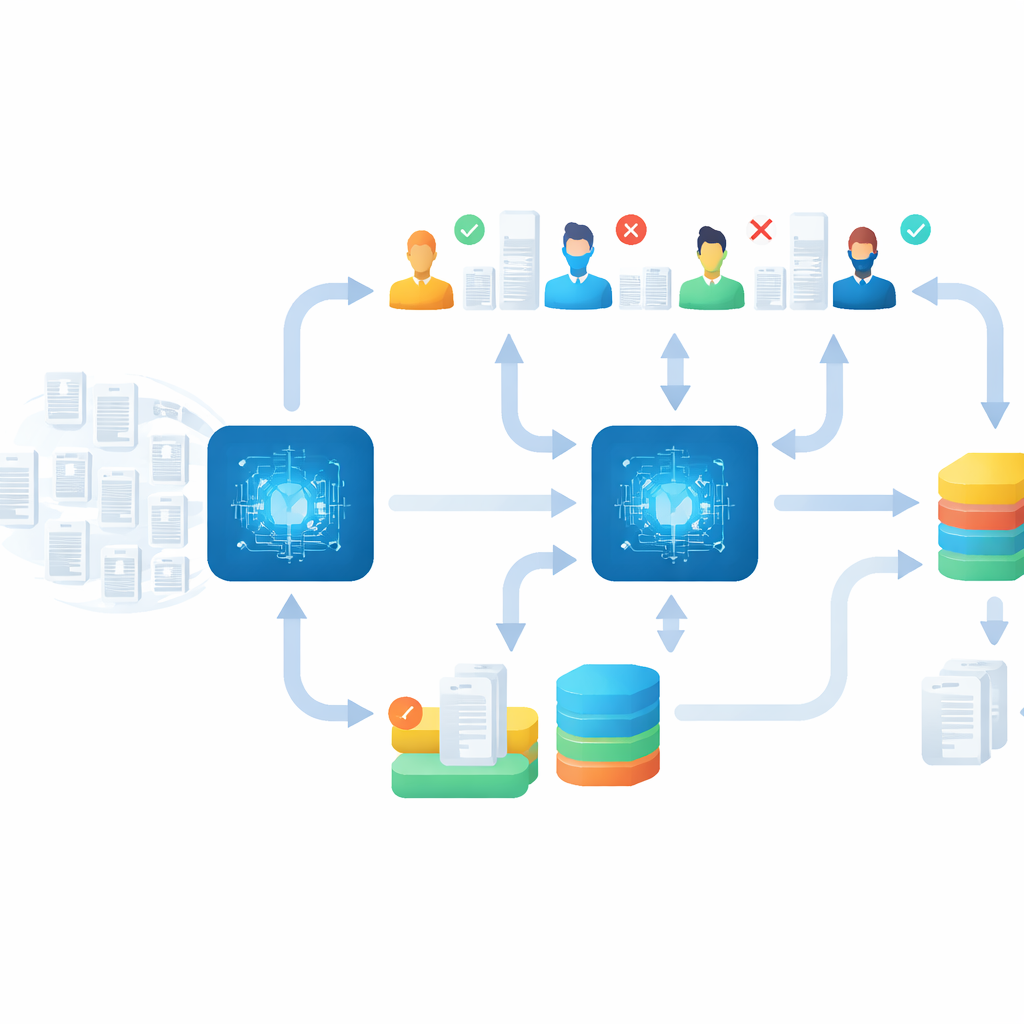
De machine–mens output controleren
Snelheid alleen zou geen waarde hebben als belangrijke studies over het hoofd werden gezien, dus het team bouwde een sterke ‘nazorg’-fase in. Zodra het hoofdevenement was afgelopen, besteedden ze meerdere weken aan het controleren en verfijnen van de resultaten. Ze herkenden artikelen die in de verkeerde ziektegroep waren geplaatst, lazen onzekere gevallen opnieuw en voerden aanvullende rondes van screening uit met strikte stopregels, zoals doorgaan totdat tientallen aaneengesloten irrelevante artikelen verschenen. Ten slotte gebruikten ze een speciale methode om eerder afgewezen records die mogelijk verkeerd gelabeld waren opnieuw te onderzoeken. Deze zorgvuldige opschoningsfase bracht meer dan 200 aanvullende relevante studies aan het licht over de onderwerpen heen, wat aantoont dat snel, AI-ondersteund screenen goed gecombineerd kan worden met grondige kwaliteitscontrole.
Hoe mensen het samenwerken met AI ervaarden
Gedurende het evenement vulden deelnemers vragenlijsten in over hun vertrouwen, motivatie en vertrouwen in AI-ondersteund beoordelen. Over het geheel genomen rapporteerden ze hoge motivatie en tevredenheid met de ervaring, en meer dan de helft gaf aan AI-ondersteund screenen te verkiezen boven volledig traditionele methoden. Belangrijk is dat hun vertrouwen in AI-ondersteund beoordelen toenam nadat ze daadwerkelijk met het systeem hadden gewerkt. Velen prezen de eenvoud en helderheid van de software, hoewel ze ook verbeteringen suggereerden zoals betere filteropties en meer transparante visuele aanwijzingen over hoe de AI artikelen prioriteerde.
Wat deze nieuwe aanpak ons vertelt
Voor een algemene lezer is de belangrijkste boodschap dat de uitdaging om medische literatuur bij te houden geen keuze vereist tussen mensen en machines. Screenathon 2.0 laat zien dat het combineren van expert-oordeel met adaptieve AI onderzoeksteams kan helpen snel de meest relevante studies te vinden zonder in te boeten aan zorg en toezicht. De AI versnelt de zoektocht, maar mensen nemen nog steeds de definitieve beslissingen en controleren de resultaten. Met goede training en robuuste nachecks zou dit soort mens–AI partnerschap het verzamelen van bewijs sneller, betrouwbaarder en duurzamer kunnen maken naarmate de hoeveelheid gezondheidsinformatie blijft groeien.
Bronvermelding: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Trefwoorden: systematische reviews, mens–AI samenwerking, door patiënten gegenereerde gezondheidsgegevens, actief leren, literatuurscreening