Clear Sky Science · fr
Screenathon 2.0 : dépistage collaboratif humain–IA appliqué aux données de santé générées par les patients
Pourquoi cela importe pour la recherche en santé de tous les jours
La médecine moderne repose sur le tri de montagnes d'articles scientifiques pour déterminer ce qui fonctionne vraiment. Mais le nombre de nouvelles études a tellement augmenté que même des équipes de recherche organisées ont du mal à suivre. Cet article décrit une nouvelle façon d'associer des personnes et l'intelligence artificielle (IA) pour accélérer ce « criblage » des articles, tout en laissant le jugement humain au cœur du processus. L'approche, appelée Screenathon 2.0, montre comment des foules d'experts et des logiciels intelligents peuvent coopérer pour traiter d'énormes volumes de lecture en quelques jours seulement.
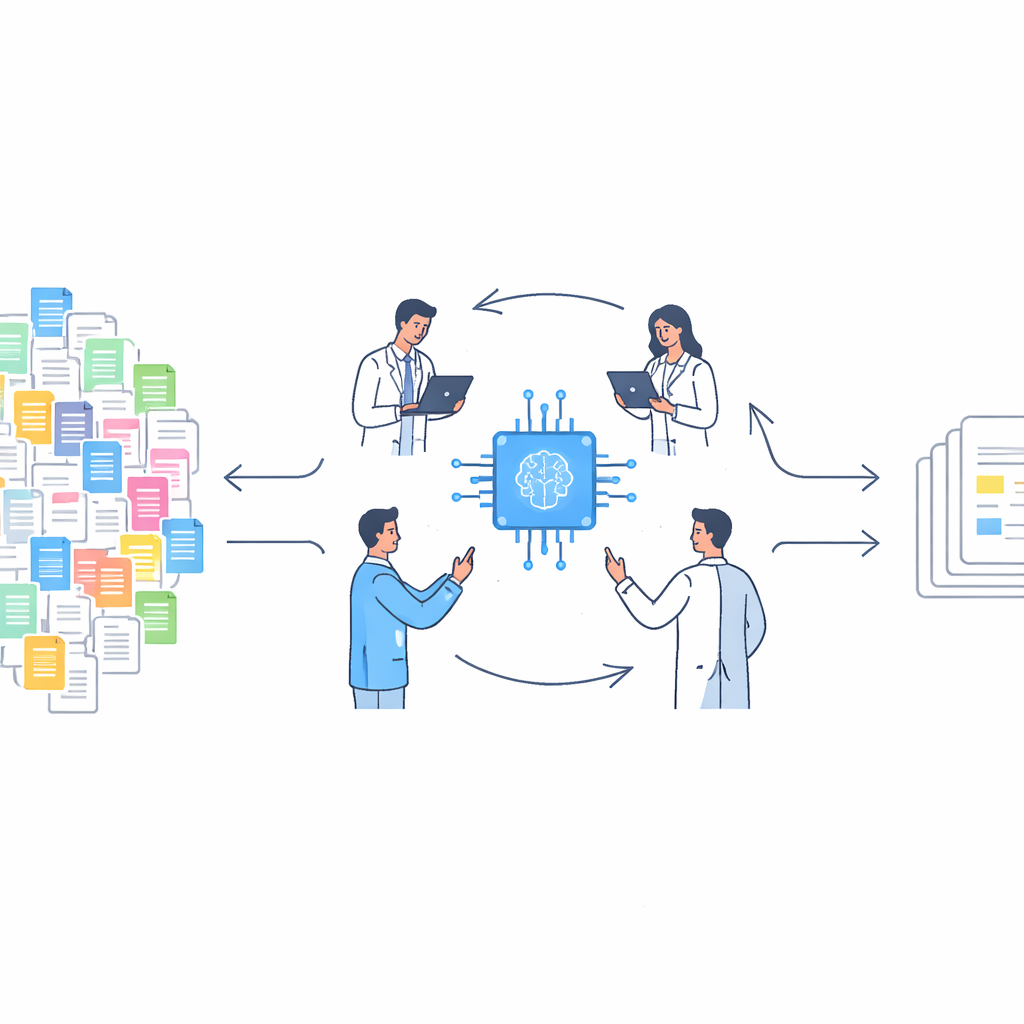
Du travail en solitaire à un sport d'équipe
Traditionnellement, les chercheurs réalisent des revues systématiques en demandant à au moins deux personnes de lire le titre et le résumé de chaque article et de décider s'il correspond à la question d'étude. Ce processus minutieux contribue à garantir des conclusions fiables, mais il est terriblement lent et difficile à étendre à mesure que le nombre d'articles explose. Précédemment, le même groupe de chercheurs avait transformé le criblage en un « Screenathon », où des dizaines d'experts travaillaient côte à côte pendant plusieurs jours pour répartir la charge. Ce premier événement a prouvé que le travail d'équipe aide, mais il dépendait entièrement de l'effort humain et ne permettait pas d'échapper totalement à la fatigue, aux différences d'expérience et aux erreurs d'étiquetage.
Ajouter l'IA comme coéquipière utile
Dans Screenathon 2.0, l'équipe a amélioré le processus en intégrant l'IA directement dans le flux de travail. Ils se sont concentrés sur la recherche concernant les données de santé générées par les patients — des informations que les personnes collectent elles-mêmes avec des outils comme des traqueurs d'activité, des lecteurs de glycémie ou des applications de santé. En utilisant le logiciel open source ASReview, le modèle d'IA apprenait en temps réel à partir de chaque jugement des relecteurs humains : chaque fois qu'une personne marquait un article comme pertinent ou non, le système mettait à jour ses règles internes et réorganisait les articles restants, poussant les plus prometteurs en tête de file. De cette façon, les humains restaient les décideurs, tandis que l'IA servait de guide en constante amélioration, décidant quels articles devraient être vérifiés ensuite.
Une grande expérience sur deux jours intenses
Les chercheurs ont testé ce partenariat humain–IA lors d'une réunion de trois jours d'un consortium européen en santé. Vingt-sept experts de 27 organisations partenaires ont examiné près de 7 000 notices scientifiques réparties sur 11 domaines de maladie, du cancer aux affections cardiaques et troubles neurologiques. Le premier jour, les participants ont reçu une formation sur les règles d'inclusion et une introduction au fonctionnement du système d'IA. Le deuxième jour, ils se sont consacrés au criblage collaboratif intensif, parfois même de façon informelle dans des espaces partagés. À la fin, ils avaient étiqueté 487 notices comme pertinentes et plus de 6 000 comme non pertinentes, certains personnes ayant examiné seulement quelques articles et d'autres des milliers, tous alimentant des modèles d'IA partagés pour chaque thématique de maladie.
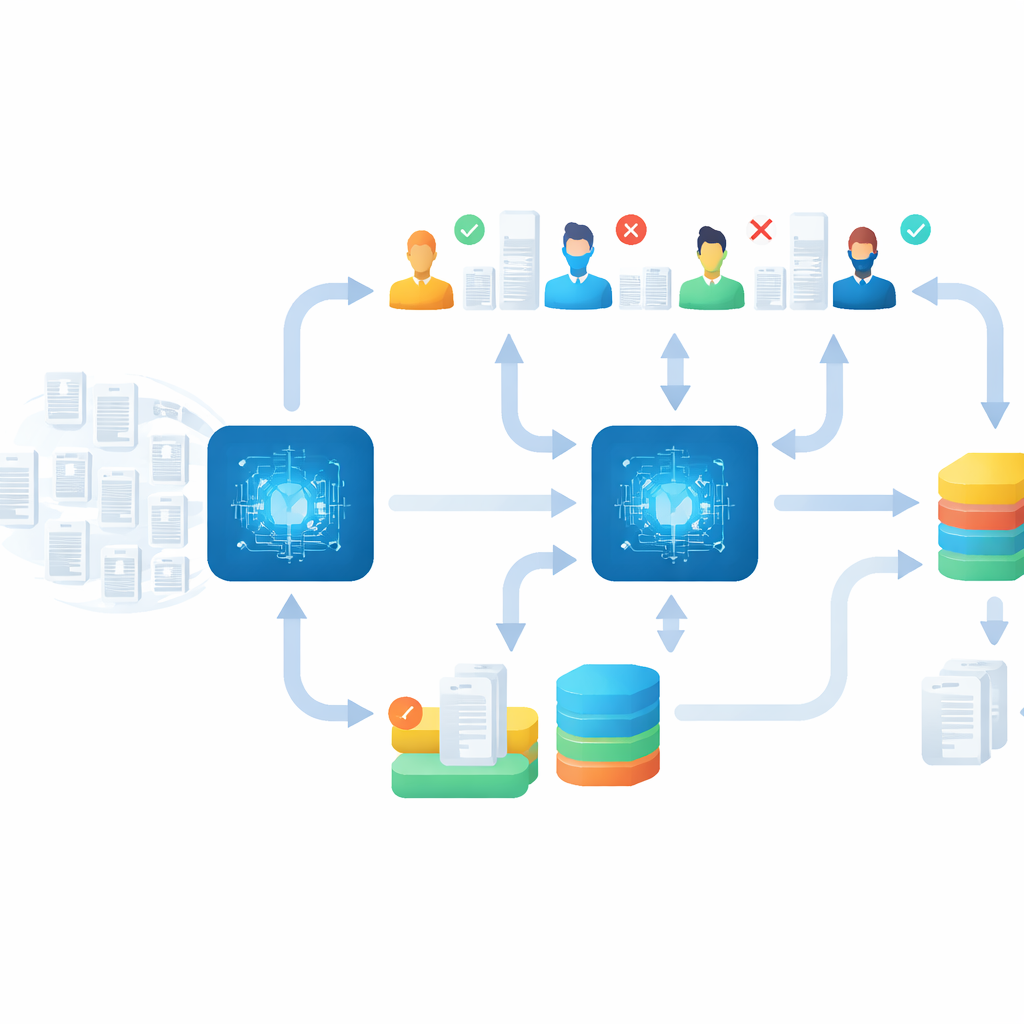
Vérifier les résultats machine–humain
La vitesse à elle seule serait vaine si des études importantes étaient manquées, aussi l'équipe a-t-elle mis en place une solide phase de « suivi ». Une fois l'événement principal terminé, ils ont passé plusieurs semaines à vérifier et affiner les résultats. Ils ont réattribué les articles qui avaient été placés dans le mauvais groupe de maladies, relu les cas incertains et effectué des tours supplémentaires de criblage en appliquant des règles d'arrêt strictes, par exemple en continuant jusqu'à l'apparition de dizaines d'articles non pertinents consécutifs. Enfin, ils ont utilisé une méthode spéciale pour réexaminer les notices précédemment rejetées qui pourraient avoir été mal étiquetées. Cette phase de nettoyage minutieuse a permis de retrouver plus de 200 études pertinentes supplémentaires à travers les thématiques, démontrant qu'un criblage rapide assisté par l'IA peut être associé à un contrôle qualité approfondi.
Comment les participants ont perçu le travail avec l'IA
Tout au long de l'événement, les participants ont rempli des enquêtes sur leur confiance, leur motivation et leur confiance dans la relecture assistée par l'IA. Dans l'ensemble, ils ont fait état d'une forte motivation et d'une grande satisfaction vis‑à‑vis de l'expérience, et plus de la moitié a déclaré préférer le criblage assisté par l'IA aux méthodes entièrement traditionnelles. Fait notable, leur confiance dans la relecture assistée par l'IA a augmenté après qu'ils eurent réellement utilisé le système. Beaucoup ont salué la simplicité et la clarté du logiciel, bien qu'ils aient également suggéré des améliorations comme de meilleures options de filtrage et des repères visuels plus transparents sur la façon dont l'IA priorisait les articles.
Ce que cette nouvelle approche nous apprend
Pour un lecteur général, le message clé est que le défi de suivre la recherche médicale n'oblige pas à choisir entre humains et machines. Screenathon 2.0 montre que mêler le jugement d'experts à une IA adaptative peut aider les équipes de recherche à trouver rapidement les études les plus pertinentes sans sacrifier le soin et la supervision. L'IA accélère la recherche, mais les humains prennent toujours les décisions finales et vérifient les résultats. Avec une formation solide et des vérifications postérieures robustes, ce type de partenariat humain–IA pourrait rendre la collecte de preuves plus rapide, plus fiable et plus durable à mesure que l'information en santé continue de croître.
Citation: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Mots-clés: revues systématiques, collaboration humain–IA, données de santé générées par les patients, apprentissage actif, criblage de la littérature