Clear Sky Science · de
Screenathon 2.0: mensch–KI-kollaboratives Screening angewandt auf patientengenerierte Gesundheitsdaten
Warum das für die alltägliche Gesundheitsforschung wichtig ist
Die moderne Medizin ist darauf angewiesen, Berge wissenschaftlicher Artikel zu durchforsten, um herauszufinden, was tatsächlich wirkt. Doch das Volumen neuer Studien ist so stark angewachsen, dass selbst organisierte Forschungsteams Mühe haben, Schritt zu halten. Dieser Artikel beschreibt eine neue Art der Zusammenarbeit zwischen Menschen und künstlicher Intelligenz (KI), die das „Screening“ von Artikeln beschleunigt und gleichzeitig menschliches Urteilsvermögen in der Verantwortung lässt. Der Ansatz, Screenathon 2.0 genannt, zeigt, wie Gruppen von Expertinnen und Experten und intelligente Software gemeinsam gewaltige Leseaufgaben in nur wenigen Tagen bewältigen können.
Vom Solo-Lesen zur Teamleistung
Traditionell führen Forschende systematische Übersichten durch, indem mindestens zwei Personen Titel und Zusammenfassung jedes Artikels lesen und entscheiden, ob er zur Fragestellung passt. Dieser sorgfältige Prozess trägt zu verlässlichen Schlussfolgerungen bei, ist aber quälend langsam und schwer skalierbar, wenn die Zahl der Artikel explodiert. Zuvor hatte dieselbe Forschungsgruppe versucht, das Screening in einen „Screenathon“ zu verwandeln, bei dem Dutzende Expertinnen und Experten mehrere Tage nebeneinander arbeiteten, um die Arbeit aufzuteilen. Dieses erste Ereignis zeigte, dass Teamarbeit hilft, doch es ruhte vollständig auf menschlicher Arbeit und konnte Ermüdung, ungleiches Erfahrungsspektrum und Kennzeichnungsfehler nicht vollständig vermeiden.
KI als hilfreiche Teamkollegin
In Screenathon 2.0 verbesserte das Team den Prozess, indem es die KI direkt in den Arbeitsablauf integrierte. Der Fokus lag auf Forschung zu patientengenerierten Gesundheitsdaten—Informationen, die Menschen selbst mit Geräten wie Fitness-Trackern, Glukosemessgeräten oder Gesundheits-Apps erfassen. Mit dem Open-Source-Programm ASReview lernte das KI-Modell in Echtzeit aus jedem Urteil der menschlichen Gutachterinnen und Gutachter: Jedes Mal, wenn eine Person einen Artikel als relevant oder nicht relevant markierte, aktualisierte das System seine internen Regeln und ordnete die verbleibenden Artikel neu, sodass die vielversprechendsten vorn in der Warteschlange landeten. Auf diese Weise blieben Menschen die Entscheidenden, während die KI als sich stetig verbessernder Leitfaden fungierte und bestimmte, welche Artikel als Nächstes geprüft werden sollten.
Ein großes Experiment in zwei intensiven Tagen
Die Forschenden testeten diese Mensch–KI-Partnerschaft während einer dreitägigen Tagung eines europäischen Gesundheitskonsortiums. Siebenundzwanzig Expertinnen und Experten aus 27 Partnerorganisationen sichteten fast 7.000 wissenschaftliche Einträge, verteilt auf 11 Krankheitsgebiete, von Krebs über Herzkrankheiten bis zu neurologischen Störungen. Am ersten Tag erhielten die Teilnehmenden Schulungen zu Einschlussregeln und eine Einführung in die Funktionsweise des KI-Systems. Am zweiten Tag konzentrierten sie sich auf intensives kollaboratives Screening und arbeiteten teils informell auch in gemeinsamen Räumen weiter. Am Ende hatten sie 487 Einträge als relevant und mehr als 6.000 als irrelevant markiert; einige Personen bearbeiteten nur ein paar Artikel, andere verarbeiteten Tausende—und alle speisten ihre Entscheidungen in gemeinsame KI-Modelle für jedes Krankheitsgebiet ein.
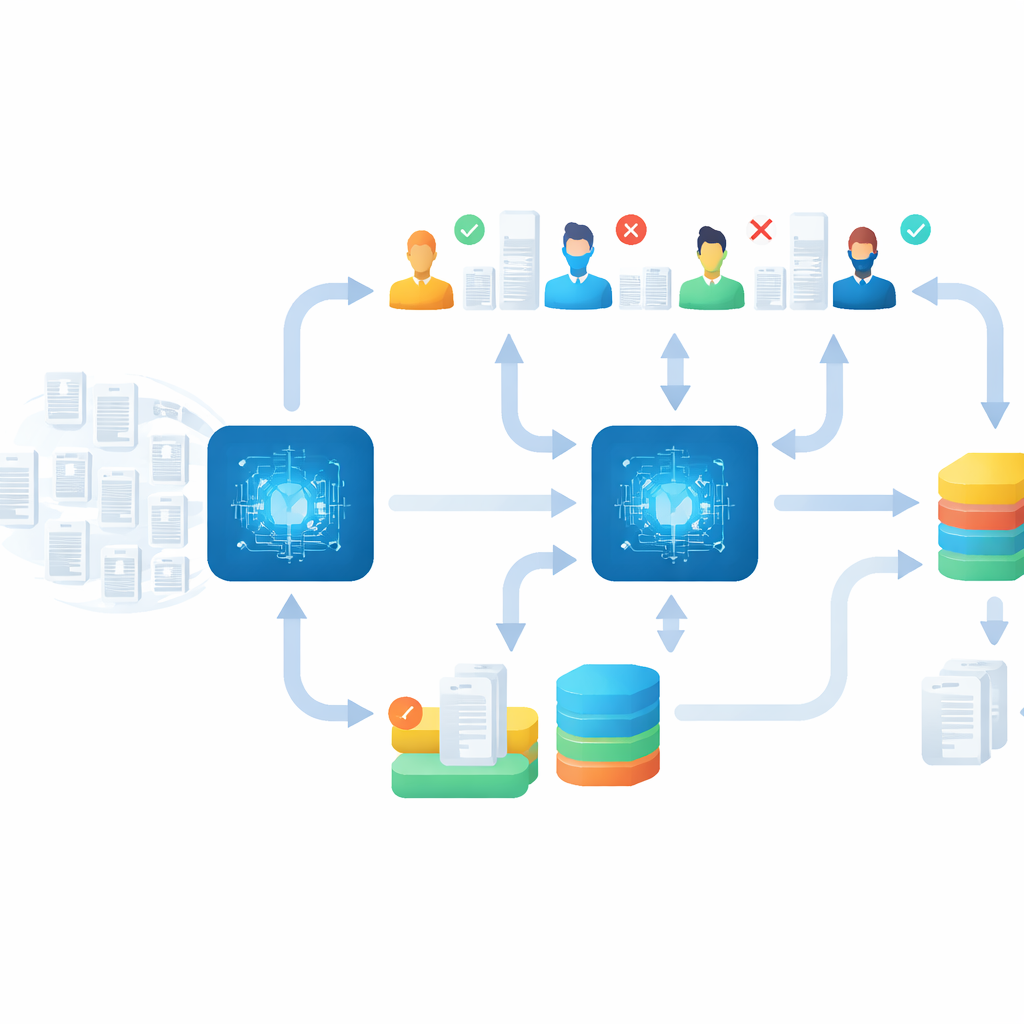
Überprüfung der Maschine–Mensch-Ergebnisse
Allein Geschwindigkeit wäre bedeutungslos, wenn wichtige Studien übersehen würden, deshalb baute das Team eine solide „Nachsorge“-Phase ein. Nachdem das Hauptevent beendet war, verbrachten sie mehrere Wochen damit, die Ergebnisse zu prüfen und zu verfeinern. Sie ordneten Artikel neu, die in die falsche Krankheitsgruppe geraten waren, lasen unsichere Fälle erneut und führten zusätzliche Screening-Runden mit strengen Abbruchregeln durch, zum Beispiel bis Dutzende ununterbrochene irrelevante Artikel erschienen. Schließlich verwendeten sie eine spezielle Methode, um zuvor abgelehnte Einträge erneut zu untersuchen, die möglicherweise falsch markiert worden waren. Diese sorgfältige Bereinigungsphase förderte mehr als 200 zusätzliche relevante Studien zutage und zeigte, dass schnelles, KI-unterstütztes Screening mit gründlicher Qualitätskontrolle kombinierbar ist.
Wie die Teilnehmenden das Arbeiten mit KI empfanden
Während der Veranstaltung füllten die Teilnehmenden Umfragen zu ihrem Vertrauen, ihrer Motivation und ihrem Vertrauen in KI-gestütztes Begutachten aus. Insgesamt berichteten sie von hoher Motivation und Zufriedenheit mit der Erfahrung, und mehr als die Hälfte gab an, AI-unterstütztes Screening klassischen Methoden vorzuziehen. Wichtig war, dass ihr Vertrauen in die KI-gestützte Begutachtung zunahm, nachdem sie tatsächlich mit dem System gearbeitet hatten. Viele lobten die Einfachheit und Klarheit der Software, schlugen aber auch Verbesserungen vor, etwa bessere Filteroptionen und transparentere visuelle Hinweise darauf, wie die KI die Artikel priorisierte.
Was dieser neue Ansatz uns verrät
Für eine allgemeine Leserschaft lautet die Kernbotschaft, dass die Herausforderung, mit der medizinischen Forschung Schritt zu halten, nicht erfordert, sich zwischen Menschen und Maschinen zu entscheiden. Screenathon 2.0 zeigt, dass die Verbindung von fachlichem Urteil und adaptiver KI Forschungsteams dabei helfen kann, schnell die relevantesten Studien zu finden, ohne Sorgfalt und Aufsicht zu opfern. Die KI beschleunigt die Suche, doch die Menschen treffen weiterhin die endgültigen Entscheidungen und prüfen die Ergebnisse. Mit guter Schulung und robuster Nachprüfung könnte diese Form der Mensch–KI-Partnerschaft die Evidenzgewinnung schneller, verlässlicher und nachhaltiger machen, während die Menge an Gesundheitsinformationen weiter wächst.
Zitation: Bergmann, J., Azzi, T., Neeleman, R. et al. Screenathon 2.0: human–AI collaborative screening applied to patient-generated health data. Sci Rep 16, 14487 (2026). https://doi.org/10.1038/s41598-026-45385-5
Schlüsselwörter: systematische Übersichten, Mensch–KI-Zusammenarbeit, patientengenerierte Gesundheitsdaten, aktives Lernen, Literatur-Screening