Clear Sky Science · sv
Hänga med i regionerna: ett hybridramverk med maskininlärning för att uppskatta regionala input–output-tabeller
Varför regionala ekonomier spelar roll
När en fabrik stänger, ett nytt sjukhus öppnar eller en hamn byggs ut, sprider sig effekterna långt bortom den omedelbara arbetsplatsen. Ekonomer använder detaljerade "input–output"-tabeller för att följa hur pengar och jobb flödar mellan sektorer som jordbruk, tillverkning och tjänster. För de flesta regioner inom länder är det dock så kostsamt och datakrävande att bygga dessa tabeller att de uppdateras sällan, om alls. Denna artikel presenterar ett nytt sätt att uppskatta sådana regionala ekonomiska kartor med modern maskininlärning, vilket lovar snabbare och mer precisa verktyg för planerare, analytiker och alla som är intresserade av hur lokala ekonomier är sammanlänkade.
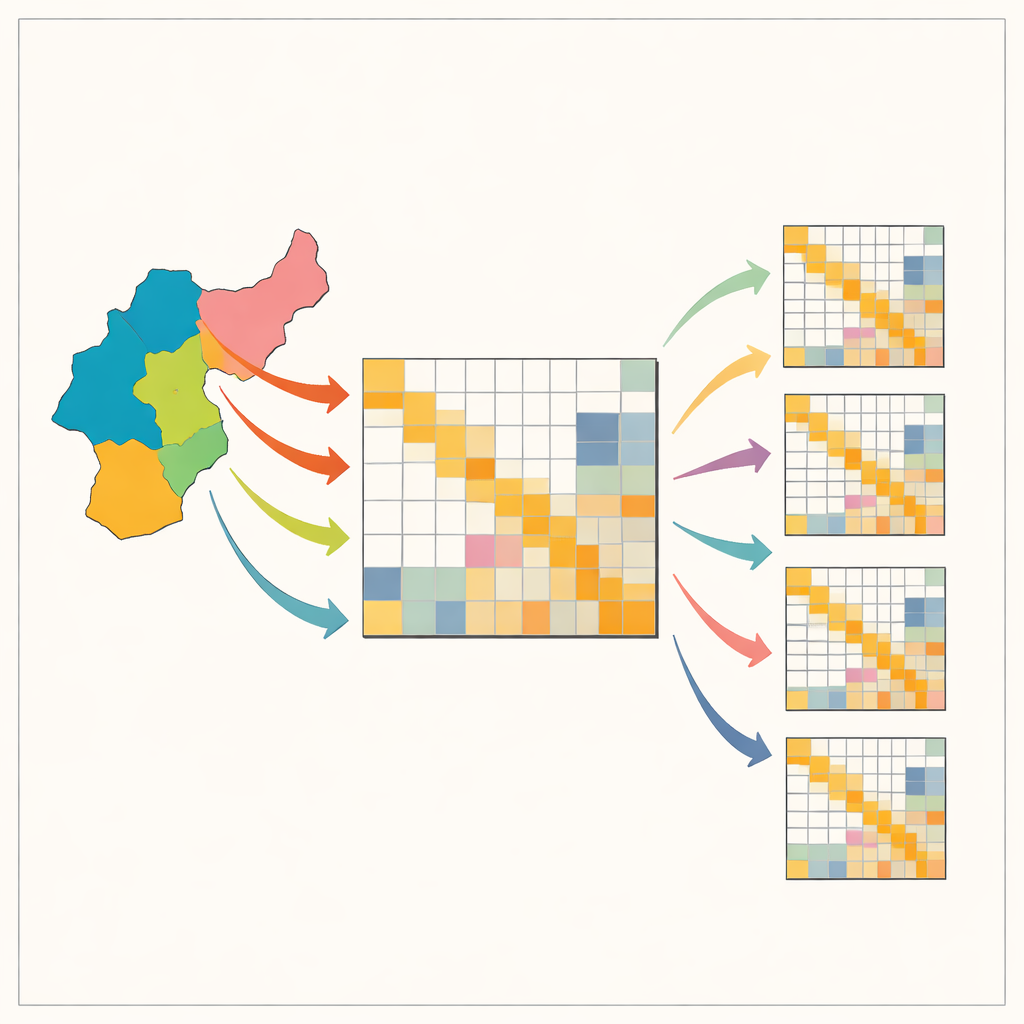
Pusslet med att kartlägga lokala ekonomiska länkar
Input–output-tabeller beskriver vem som köper vad av vem i en ekonomi: hur mycket stål bilbyggare köper, hur många juridiska tjänster tillverkare använder, och så vidare. Nationella tabeller finns för många länder, men lokala versioner — för delstater, provinser eller stadsregioner — saknas ofta eftersom de kräver stora, dyra undersökningar. För att komma runt detta utgår ekonomer vanligtvis från den nationella tabellen och omformar den med enkla matematiska recept så att den matchar kända regionala totaler, såsom sysselsättning eller sektorvis produktion. Populära genvägar, med namn som location quotients och RAS, är billiga och snabba men kan förvränga viktiga mönster, särskilt tendensen att industrier handlar mycket med sig själva och med några få nyckelpartnar. Dessa förvrängningar kan vilseleda beslut om infrastruktur, klimatpolitik eller beredskap för chocker.
Att blanda gammal ekonomi med nya algoritmer
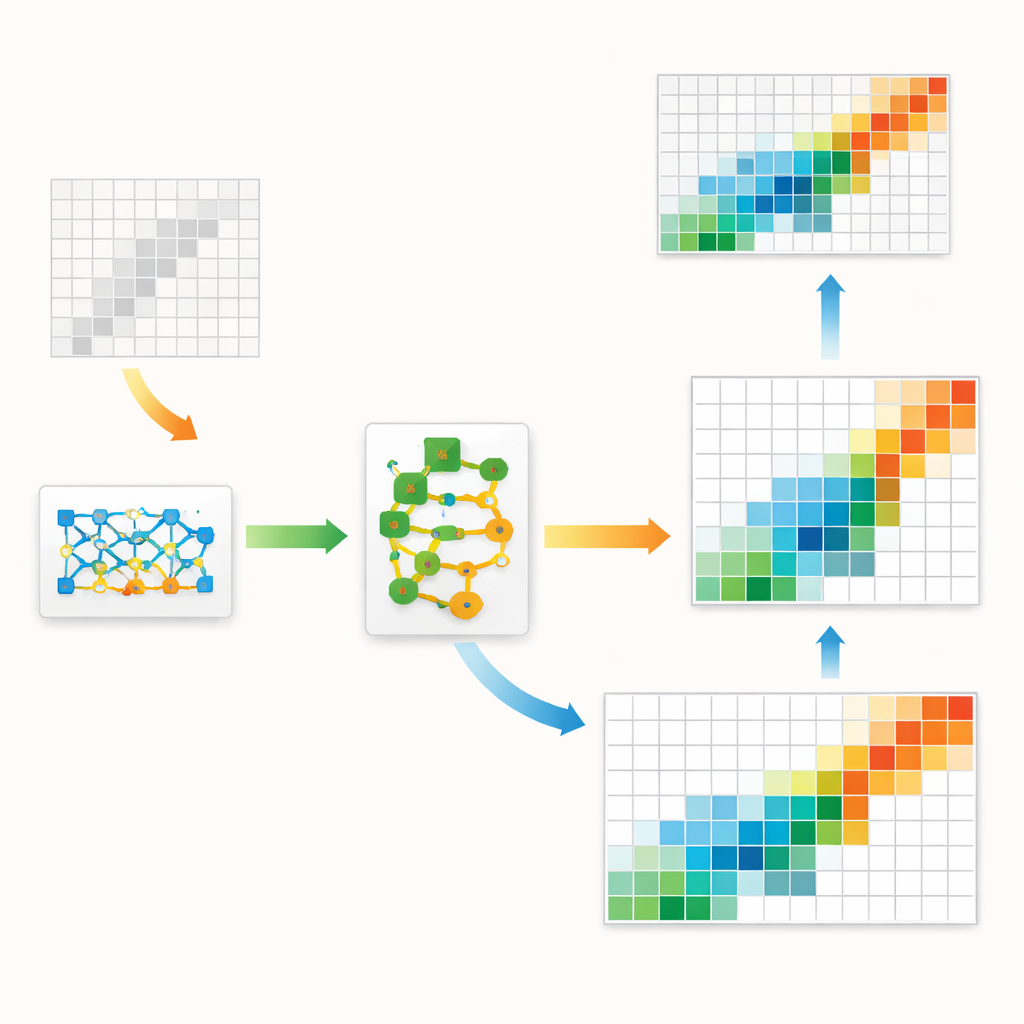
Författarna föreslår ett hybridramverk som förenar klassisk ekonomisk struktur med toppmodern artificiell intelligens. Kärnan är en typ av generativ modell kallad GAN, som vanligtvis används för att skapa realistiska bilder. Här, i stället för bilder, lär sig GAN:en att skapa hela input–output-tabeller som liknar dem som observerats i historiska data. Ett särskilt internt lager tvingar varje genererad tabell att respektera hårda redovisningsregler: rad- och kolumnsummor måste matcha kända regionala siffror och poster får inte vara negativa. Detta håller maskininlärningsmodellen förankrad i grundläggande ekonomiska principer i stället för att låta den jaga rent statistiska mönster.
Finjustering av utkastet
Även en vältränad GAN tenderar att göra små, systematiska fel — till exempel att något underskatta hur starkt vissa sektorer handlar med sig själva. För att åtgärda detta lägger författarna till en andra fas känd som residual boosting. Efter att GAN:en producerat sitt bästa gissning lär sig en separat ensemble av beslutsträdmodeller de typiska fel den gör och förutsäger en korrigering. Den korrigerade tabellen justeras sedan varsamt för att undvika orealistiska värden. Denna tvåstegsdesign utnyttjar GAN:ens förmåga att fånga helhetsbilden — som den övergripande formen och koncentrationen av flöden — samtidigt som boostern används för att skärpa lokala detaljer. Metoden är också informerad av det faktum att verkliga ekonomier har några mycket stora flöden och många små, ett snedvridet mönster som modellen uttryckligen uppmuntras att efterlikna.
Utvärdering av metoden
För att se om detta hybridförfarande fungerar i praktiken testar författarna det på två större datamängder: en samling nationella tabeller från många länder och ett set världsomspännande input–output-tabeller som beskriver globala leveranskedjor över flera dussin industrier och regioner. Eftersom de verkliga tabellerna är kända i dessa fall kan forskarna jämföra sina uppskattningar direkt med verkligheten och med förbättrade versioner av den traditionella RAS-metoden. Över en rad olika mått — total passform, genomsnittliga fel, hur väl huvuddiagonalen återges och hur väl den ojämna fördelningen av stora och små flöden bevaras — kommer hybridmetoden bäst ut. I den nationella datamängden förbättrar den standardmåttet för godhet av passform med nästan nio procentenheter jämfört med förbättrad RAS, och den fördubblar mer än noggrannheten i hur självköp inom sektorer fångas. På de globala tabellerna uppnår den ännu närmare överensstämmelse och reproducerar nästan perfekt den underliggande strukturen.
Vad detta betyder för verkliga beslut
För icke-specialister är huvudbudskapet att vi nu kan bygga mycket mer tillförlitliga bilder av regionala ekonomier utan att skicka ut intervjuteam hus till hus. Hybridmodellen behåller den välkända redovisningslogik som policyanalytiker litar på men låter avancerad maskininlärning upptäcka subtila regelbundenheter som äldre verktyg missar. Bättre regionala input–output-tabeller omsätts i mer trovärdiga uppskattningar av hur lokala chocker sprids, vilka sektorer som är mest kritiska och hur policyer kommer att reverbera genom jobb, inkomster och utsläpp. Även om metoden fortfarande är beroende av att ha bra träningsdata och mer beräkningskraft än traditionella tillvägagångssätt, tyder dess starka prestanda på att modern datavetenskap kan skärpa våra glasögon för att se regional utveckling, motståndskraft och strukturella förändringar betydligt bättre.
Citering: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Nyckelord: regionala input–output-tabeller, ekonomiska nätverk, maskininlärning, generativa modeller, regional utveckling