Clear Sky Science · pl
Dotrzymać kroku regionom: hybrydowe ramy uczenia maszynowego do szacowania regionalnych tablic input-output
Dlaczego gospodarki regionalne mają znaczenie
Kiedy zamyka się fabryka, otwiera nowy szpital lub rozbudowywany jest port, skutki rozchodzą się daleko poza bezpośrednie miejsce pracy. Ekonomiści stosują szczegółowe tablice „input–output”, by śledzić, jak pieniądze i miejsca pracy przepływają między sektorami takimi jak rolnictwo, przemysł i usługi. Jednak dla większości regionów w obrębie państw sporządzenie takich tablic jest tak kosztowne i wymaga tyle danych, że aktualizuje się je rzadko, jeśli w ogóle. Ten artykuł przedstawia nowy sposób estymowania tych regionalnych map gospodarczych z użyciem nowoczesnego uczenia maszynowego, obiecując szybsze i dokładniejsze narzędzia dla planistów, analityków i wszystkich zainteresowanych tym, jak lokalne gospodarki są ze sobą powiązane.
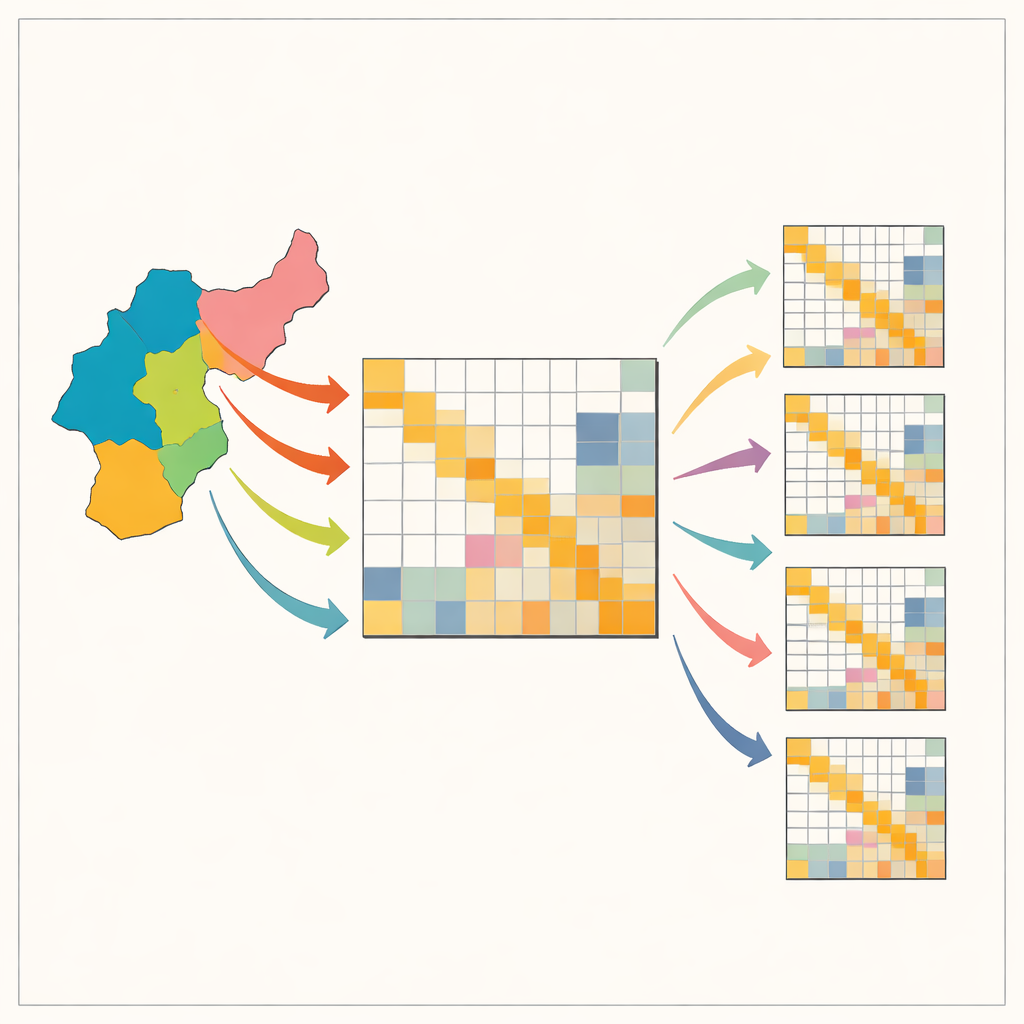
Zagadkę mapowania lokalnych powiązań gospodarczych
Tablice input–output opisują, kto od kogo kupuje, w gospodarce: ile stali nabywają producenci samochodów, ile usług prawnych wykorzystują wytwórcy i tak dalej. Tablice krajowe istnieją dla wielu krajów, ale wersje lokalne — dla stanów, prowincji czy obszarów miejskich — często są nieobecne, ponieważ wymagają dużych, kosztownych badań. Aby to obejść, ekonomiści zwykle zaczynają od tablicy krajowej i przekształcają ją prostymi algorytmami tak, aby zgadzała się z dostępnymi sumami regionalnymi, takimi jak zatrudnienie czy produkcja według sektorów. Popularne skróty, o nazwach takich jak location quotients i RAS, są tanie i szybkie, ale mogą zniekształcać istotne wzorce, zwłaszcza tendencję sektorów do intensywnego kupowania od siebie nawzajem i od kilku kluczowych partnerów. Takie zniekształcenia mogą wprowadzać w błąd przy podejmowaniu decyzji dotyczących infrastruktury, polityki klimatycznej czy przygotowań na wstrząsy.
Łączenie starej ekonomii z nowymi algorytmami
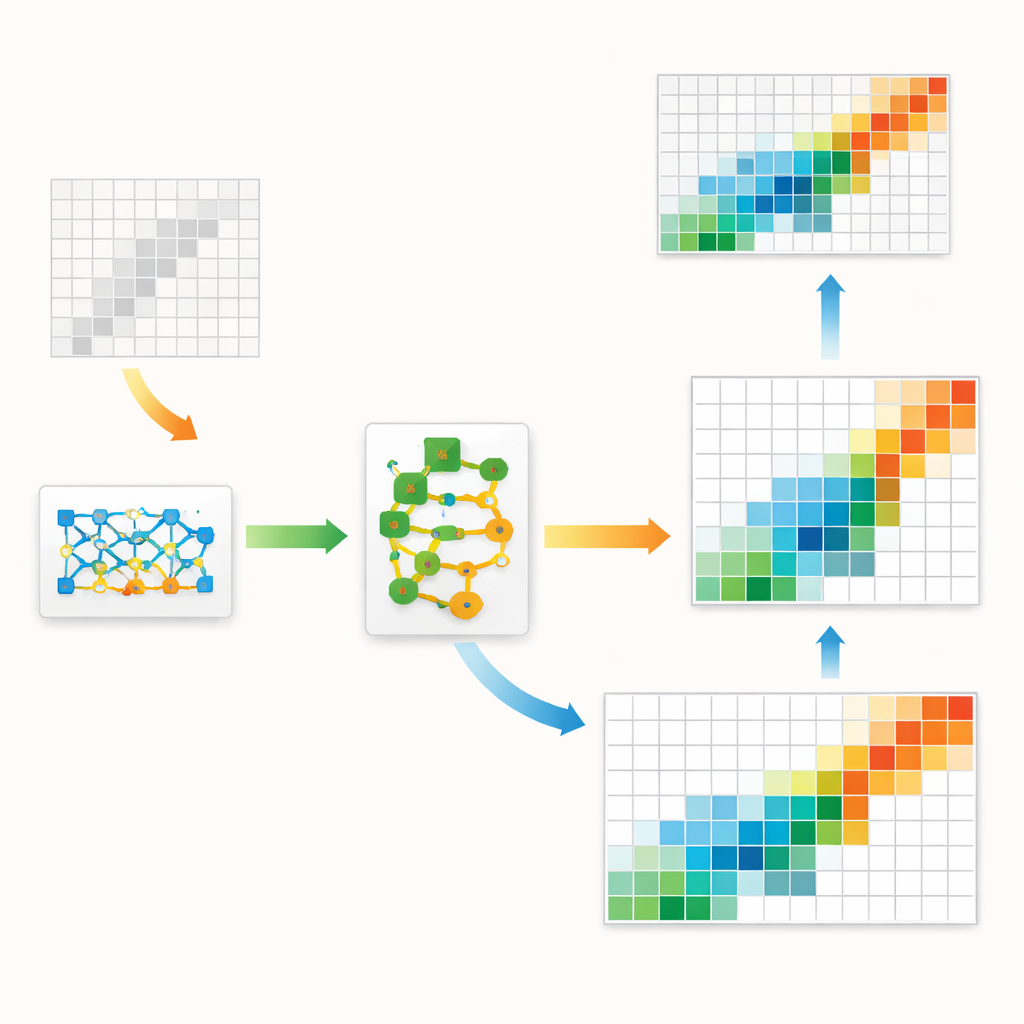
Autorzy proponują hybrydowe ramy łączące klasyczną strukturę ekonomiczną ze współczesną sztuczną inteligencją. W centrum znajduje się rodzaj modelu generatywnego zwanego GAN, powszechnie używanego do tworzenia realistycznych obrazów. Tutaj, zamiast obrazów, GAN uczy się tworzyć całe tablice input–output przypominające te obserwowane w danych historycznych. Specjalna wewnętrzna warstwa wymusza, by każda wygenerowana tablica przestrzegała twardych zasad rachunkowości: sumy w wierszach i kolumnach muszą odpowiadać znanym wielkościom regionalnym, a wartości nie mogą być ujemne. To utrzymuje model uczenia maszynowego w granicach podstawowej logiki ekonomicznej, zamiast pozwalać mu ścigać się jedynie za czysto statystycznymi wzorcami.
Dopracowywanie szkicu
Nawet dobrze wytrenowany GAN ma tendencję do popełniania drobnych, systematycznych błędów — na przykład nieco niedoszacowuje, jak silnie niektóre sektory handlują samymi ze sobą. Aby to naprawić, autorzy dodają drugi etap znany jako residual boosting. Po tym jak GAN wygeneruje swoją najlepszą estymację, oddzielny zespół modeli drzew decyzyjnych uczy się typowych błędów i przewiduje korektę. Skorygowana tablica jest następnie delikatnie poprawiana, aby uniknąć nierealistycznych wartości. Ten dwustopniowy projekt wykorzystuje zaletę GAN-a w uchwyceniu całościowego obrazu — na przykład ogólnego kształtu i koncentracji przepływów — podczas gdy booster wyostrza lokalne detale. Metoda uwzględnia także fakt, że realne gospodarki mają kilka bardzo dużych przepływów i wiele drobnych, skośny rozkład, który model jest explicite zachęcany do naśladowania.
Testowanie metody
Aby sprawdzić, czy to hybrydowe podejście działa w praktyce, autorzy testują je na dwóch głównych zbiorach danych: zbiorze tablic krajowych z wielu krajów oraz zestawie światowych tablic input–output opisujących globalne łańcuchy dostaw w dziesiątkach sektorów i regionów. Ponieważ w tych przypadkach prawdziwe tablice są znane, badacze mogą porównać swoje estymaty bezpośrednio z rzeczywistością i z ulepszonymi wersjami tradycyjnej metody RAS. W szerokim zakresie miar — dopasowania ogólnego, średnich błędów, odwzorowania głównej przekątnej i zachowania nierównomiernego rozkładu dużych i małych przepływów — metoda hybrydowa wypada lepiej. W krajowym zbiorze danych poprawia standardową miarę dopasowania o prawie dziewięć punktów procentowych w porównaniu z ulepszonym RAS, a dokładność uchwycenia wewnątrzsektorowego samowykorzystania zwiększa ponad dwukrotnie. W tablicach światowych osiąga jeszcze bliższą zgodność, niemal perfekcyjnie odtwarzając podstawową strukturę.
Co to oznacza dla decyzji w świecie rzeczywistym
Dla osób niebędących specjalistami kluczowy przekaz jest taki, że teraz możemy budować znacznie bardziej wiarygodne obrazy gospodarek regionalnych bez wysyłania zespołów ankieterów od drzwi do drzwi. Model hybrydowy zachowuje znaną logikę rachunkową, której ufają analitycy polityczni, lecz pozwala zaawansowanemu uczeniu maszynowemu odkrywać subtelne regularności, które ujmują starsze narzędzia. Lepsze regionalne tablice input–output przekładają się na bardziej wiarygodne oszacowania tego, jak lokalne wstrząsy się rozprzestrzeniają, które sektory są najbardziej kluczowe i jak polityki będą oddziaływać na miejsca pracy, dochody i emisje. Choć metoda nadal zależy od dobrych danych treningowych i większej mocy obliczeniowej niż podejścia tradycyjne, jej mocne wyniki sugerują, że nowoczesna nauka o danych może znacząco wyostrzyć soczewki, przez które patrzymy na rozwój regionalny, odporność i zmiany strukturalne.
Cytowanie: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Słowa kluczowe: regionalne tablice input-output, sieci ekonomiczne, uczenie maszynowe, modele generatywne, rozwój regionalny