Clear Sky Science · es
Mantenerse al día con las regiones: un marco híbrido de aprendizaje automático para estimar tablas regionales de insumo-producto
Por qué importan las economías regionales
Cuando una fábrica cierra, se inaugura un hospital o se amplía un puerto, los efectos se propagan mucho más allá del lugar de trabajo inmediato. Los economistas usan detalladas tablas de «insumo‑producto» para seguir cómo fluyen el dinero y los empleos entre sectores como la agricultura, la manufactura y los servicios. Sin embargo, para la mayoría de las regiones dentro de los países, construir esas tablas es tan costoso y exige tanto dato que se actualizan pocas veces, si acaso. Este artículo presenta una nueva forma de estimar esos mapas económicos regionales mediante aprendizaje automático moderno, que promete herramientas más rápidas y precisas para planificadores, analistas y cualquiera interesado en cómo se interconectan las economías locales.
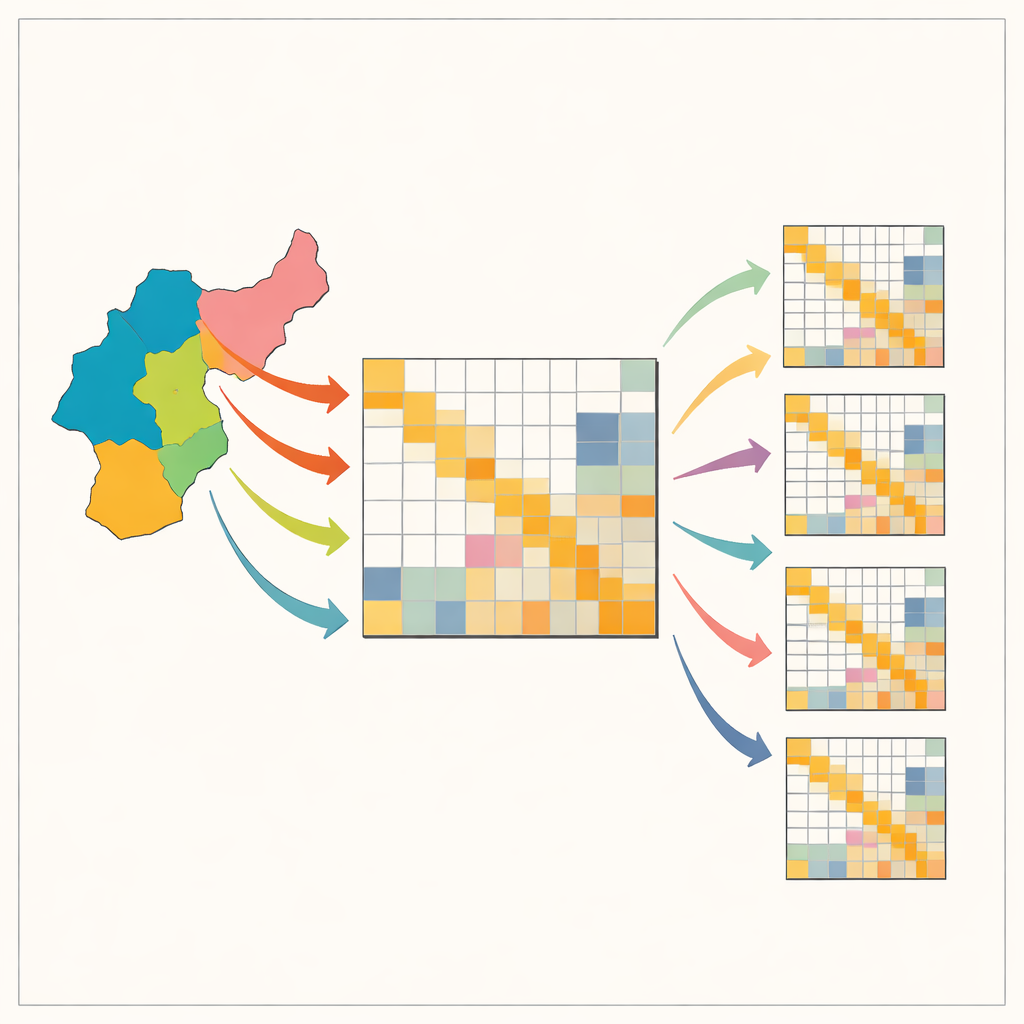
El rompecabezas de cartografiar los vínculos económicos locales
Las tablas de insumo‑producto describen quién compra qué a quién en una economía: cuánto acero compran los fabricantes de automóviles, cuántos servicios jurídicos utilizan los industriales, y así sucesivamente. Existen tablas nacionales para muchos países, pero las versiones locales —de estados, provincias o regiones metropolitanas— suelen faltar porque requieren encuestas grandes y caras. Para sortear esto, los economistas suelen partir de la tabla nacional y reconfigurarla con recetas matemáticas sencillas para que coincida con los totales regionales conocidos, como el empleo o la producción por sector. Atajos populares, con nombres como cocientes de localización y RAS, son baratos y rápidos pero pueden deformar patrones cruciales, especialmente la tendencia de las industrias a abastecerse intensamente a sí mismas y a unos pocos socios clave. Estas distorsiones pueden inducir a error decisiones sobre infraestructuras, política climática o preparación ante choques.
Mezclando la economía clásica con algoritmos modernos
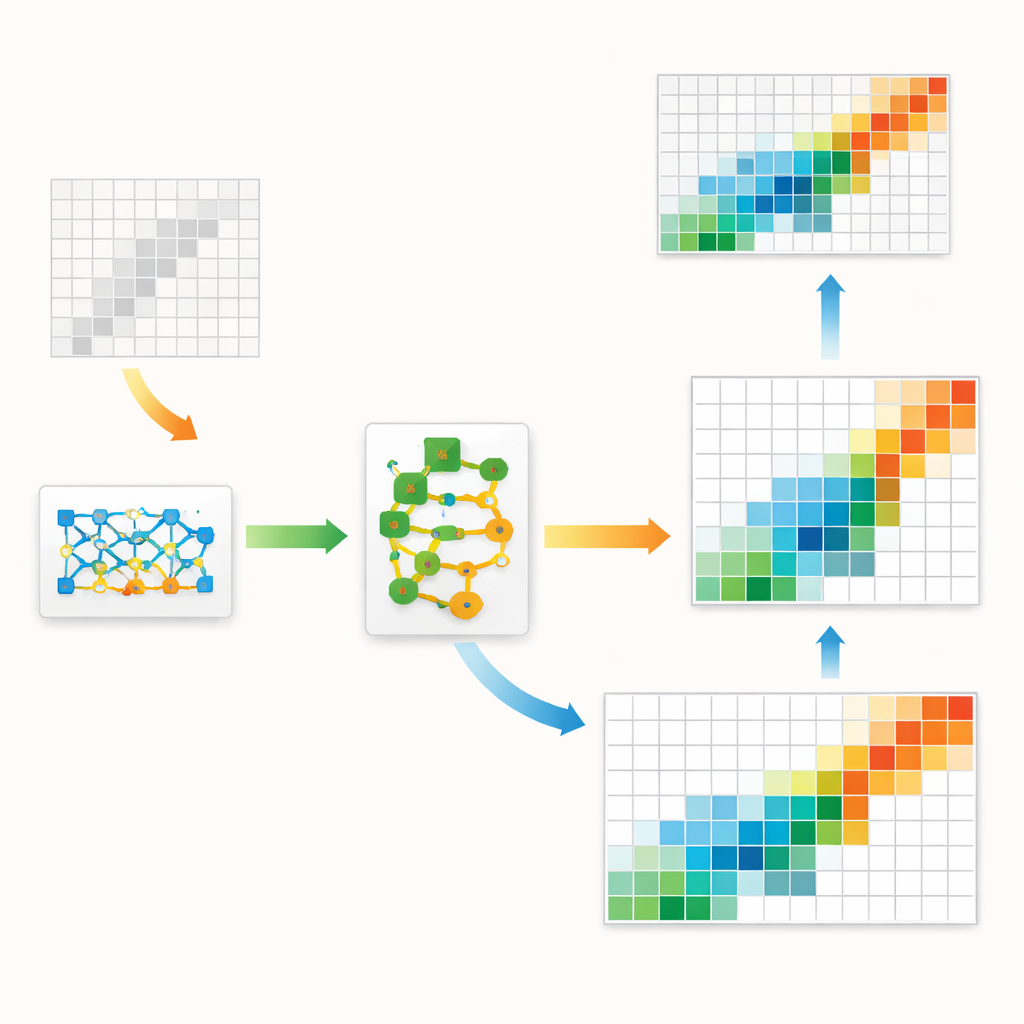
Los autores proponen un marco híbrido que une la estructura económica clásica con inteligencia artificial de vanguardia. En su núcleo hay un tipo de modelo generativo llamado GAN, empleado comúnmente para crear imágenes realistas. Aquí, en lugar de imágenes, el GAN aprende a generar tablas completas de insumo‑producto que se parecen a las observadas en datos históricos. Una capa interna especial obliga a que cada tabla generada respete reglas contables estrictas: los totales por fila y columna deben coincidir con las cifras regionales conocidas y las entradas no pueden ser negativas. Esto mantiene el modelo de aprendizaje automático anclado en principios económicos básicos en lugar de dejar que persiga solo patrones estadísticos.
Afinando el borrador
Incluso un GAN bien entrenado tiende a cometer errores pequeños y sistemáticos —por ejemplo, subestimar ligeramente la intensidad con que ciertos sectores comercian consigo mismos. Para corregir esto, los autores añaden una segunda etapa conocida como residual boosting. Después de que el GAN produce su mejor estimación, un conjunto separado de modelos de árboles de decisión aprende los errores típicos que comete y predice una corrección. La tabla corregida se ajusta luego con suavidad para evitar valores poco realistas. Este diseño en dos pasos aprovecha la capacidad del GAN para captar la fotografía general —como la forma y la concentración de los flujos— mientras que el booster afina los detalles locales. El método también se basa en el hecho de que las economías reales tienen pocos flujos muy grandes y muchos muy pequeños, un patrón sesgado que el modelo se anima explícitamente a imitar.
Poniendo el método a prueba
Para comprobar si este enfoque híbrido funciona en la práctica, los autores lo prueban con dos conjuntos de datos principales: una colección de tablas nacionales de muchos países y un conjunto de tablas mundiales de insumo‑producto que describen las cadenas de suministro globales entre decenas de industrias y regiones. Porque en estos casos las tablas verdaderas son conocidas, los investigadores pueden comparar sus estimaciones directamente con la realidad y con versiones mejoradas del método RAS tradicional. En una amplia gama de criterios —ajuste global, errores medios, qué tan bien se reproduce la diagonal principal y cuánto se preserva la distribución desigual de flujos grandes y pequeños—, el método híbrido sale adelante. En el conjunto de datos nacionales mejora la medida habitual de bondad de ajuste en casi nueve puntos porcentuales respecto al RAS mejorado, y más que duplica la precisión con la que se captura el autoabastecimiento dentro de los sectores. En las tablas globales logra un acuerdo aún más estrecho, reproduciendo casi perfectamente la estructura subyacente.
Qué significa esto para decisiones del mundo real
Para los no especialistas, el mensaje clave es que ahora podemos construir imágenes mucho más fiables de las economías regionales sin enviar equipos de encuestadores puerta a puerta. El modelo híbrido mantiene la lógica contable familiar en la que confían los analistas de políticas, pero permite que el aprendizaje automático avanzado descubra regularidades sutiles que las herramientas antiguas pasan por alto. Mejores tablas regionales de insumo‑producto se traducen en estimaciones más creíbles de cómo se propagan los choques locales, qué sectores son más críticos y cómo las políticas reverberarán en el empleo, los ingresos y las emisiones. Aunque el método sigue dependiendo de disponer de buenos datos de entrenamiento y más potencia de cálculo que los enfoques tradicionales, su sólido rendimiento sugiere que la ciencia de datos moderna puede afinar considerablemente las lentes con las que observamos el desarrollo regional, la resiliencia y el cambio estructural.
Cita: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Palabras clave: tablas regionales de insumo-producto, redes económicas, aprendizaje automático, modelos generativos, desarrollo regional