Clear Sky Science · fr
Suivre les régions : un cadre hybride d’apprentissage automatique pour estimer les tableaux input–output régionaux
Pourquoi les économies régionales comptent
Lorsqu’une usine ferme, qu’un nouvel hôpital ouvre ou qu’un port est agrandi, les effets se répercutent bien au-delà du lieu de travail immédiat. Les économistes utilisent des tableaux détaillés « input–output » pour retracer comment l’argent et les emplois circulent entre des secteurs tels que l’agriculture, la fabrication et les services. Pourtant, pour la plupart des régions à l’intérieur des pays, la construction de ces tableaux est si coûteuse et exigeante en données qu’ils sont mis à jour rarement, voire jamais. Cet article présente une nouvelle façon d’estimer ces cartes économiques régionales en utilisant l’apprentissage automatique moderne, promettant des outils plus rapides et plus précis pour les planificateurs, les analystes et tous ceux qui s’intéressent à la manière dont les économies locales sont reliées.
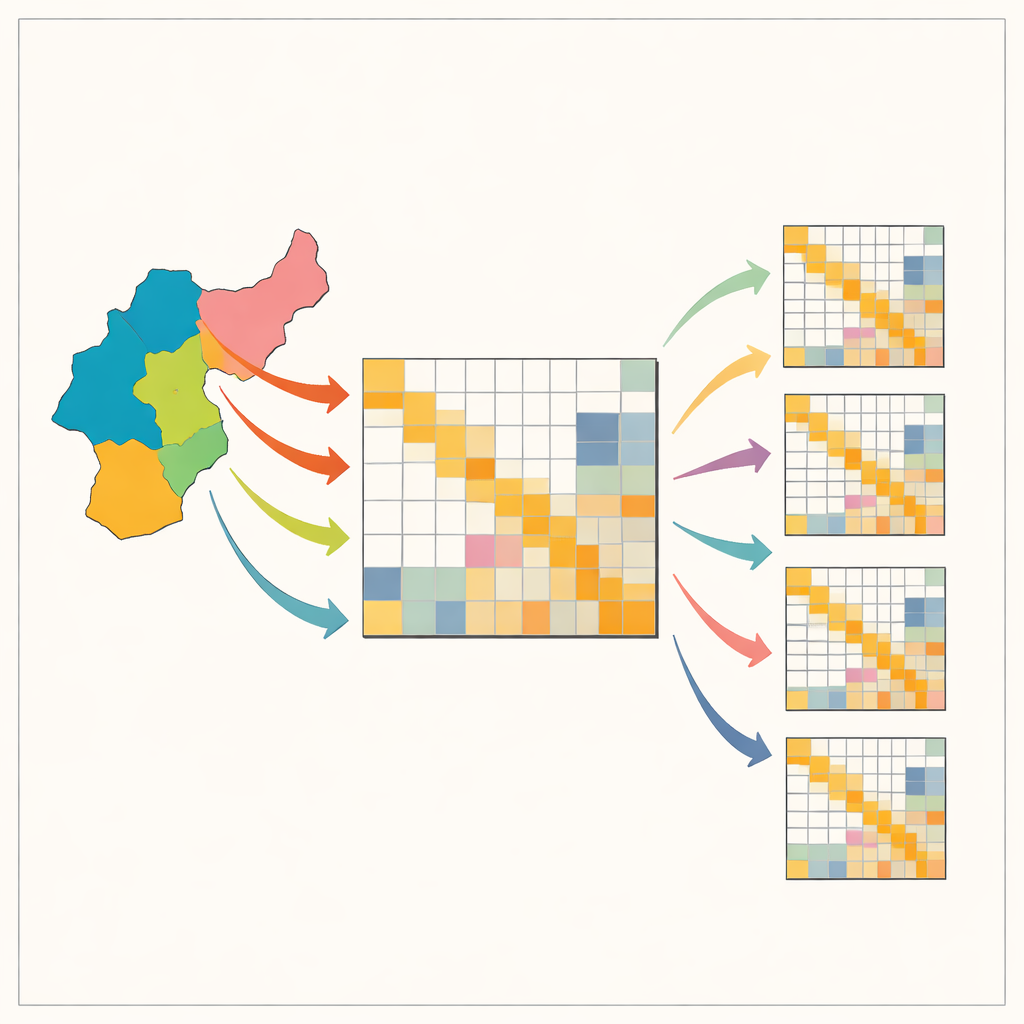
Le casse-tête de la cartographie des liens économiques locaux
Les tableaux input–output décrivent qui achète quoi à qui dans une économie : combien d’acier achètent les constructeurs automobiles, combien de services juridiques utilisent les fabricants, et ainsi de suite. Des tableaux nationaux existent pour de nombreux pays, mais les versions locales — pour des États, des provinces ou des régions urbaines — sont souvent absentes parce qu’elles nécessitent de vastes enquêtes coûteuses. Pour contourner cela, les économistes partent généralement du tableau national et le remodelent avec des recettes mathématiques simples pour qu’il corresponde aux totaux régionaux connus, comme l’emploi ou la production par secteur. Des raccourcis populaires, portant des noms comme « quotients de localisation » et RAS, sont bon marché et rapides mais peuvent déformer des motifs cruciaux, en particulier la tendance des industries à s’acheter fortement entre elles et à quelques partenaires clés. Ces distorsions peuvent induire en erreur des décisions concernant les infrastructures, la politique climatique ou la préparation aux chocs.
Mêler l’économie classique et les nouveaux algorithmes
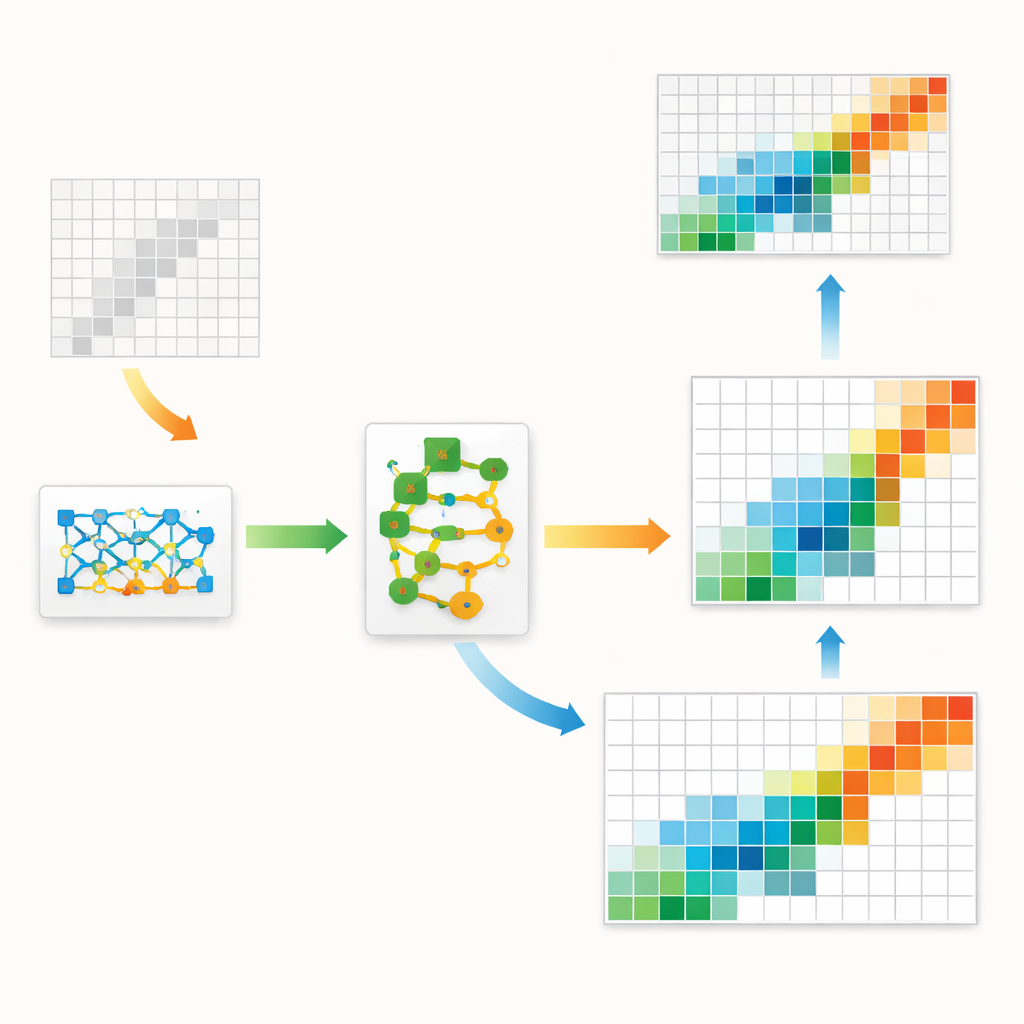
Les auteurs proposent un cadre hybride qui marie la structure économique classique avec l’intelligence artificielle de pointe. Au cœur se trouve un type de modèle génératif appelé GAN, couramment utilisé pour créer des images réalistes. Ici, au lieu d’images, le GAN apprend à générer des tableaux input–output entiers qui ressemblent à ceux observés dans les données historiques. Une couche interne spéciale force chaque tableau généré à respecter des règles comptables strictes : les totaux de lignes et de colonnes doivent correspondre aux chiffres régionaux connus et les éléments ne peuvent pas être négatifs. Cela ancre le modèle d’apprentissage automatique dans des principes économiques fondamentaux au lieu de le laisser poursuivre des motifs purement statistiques.
Affiner l’ébauche
Même un GAN bien entraîné tend à commettre de petites erreurs systématiques — par exemple, sous-estimer légèrement à quel point certains secteurs commercent avec eux-mêmes. Pour y remédier, les auteurs ajoutent une seconde étape connue sous le nom de « residual boosting ». Après que le GAN ait produit sa meilleure estimation, un ensemble distinct de modèles par arbres de décision apprend les erreurs typiques qu’il commet et prédit une correction. Le tableau corrigé est ensuite ajusté avec précaution pour éviter des valeurs irréalistes. Cette conception en deux étapes tire parti de l’habileté du GAN à saisir la vue d’ensemble — comme la forme générale et la concentration des flux — tout en utilisant le booster pour affiner les détails locaux. La méthode tient également compte du fait que les économies réelles présentent quelques flux très importants et de nombreux flux très faibles, un motif asymétrique que le modèle est explicitement encouragé à imiter.
Mettre la méthode à l’épreuve
Pour vérifier si cette approche hybride fonctionne en pratique, les auteurs la testent sur deux jeux de données majeurs : une collection de tableaux nationaux de nombreux pays et un ensemble de tableaux input–output mondiaux qui décrivent les chaînes d’approvisionnement globales à travers des dizaines de secteurs et de régions. Parce que les vrais tableaux sont connus dans ces cas, les chercheurs peuvent comparer leurs estimations directement à la réalité et à des versions améliorées de la méthode RAS traditionnelle. Selon un large éventail d’indicateurs — ajustement global, erreurs moyennes, qualité de reproduction de la diagonale principale et conservation de la répartition inégale des flux importants et faibles — la méthode hybride s’en sort mieux. Dans le jeu de données national, elle améliore la mesure standard d’adéquation d’un peu près neuf points de pourcentage par rapport au RAS amélioré, et double plus que la précision avec laquelle l’autoconsommation des secteurs est capturée. Sur les tableaux mondiaux, elle atteint une concordance encore plus étroite, reproduisant presque parfaitement la structure sous-jacente.
Ce que cela signifie pour les décisions réelles
Pour les non-spécialistes, le message clé est que nous pouvons désormais construire des représentations beaucoup plus fiables des économies régionales sans envoyer des équipes d’enquête porte à porte. Le modèle hybride conserve la logique comptable familière que les analystes politiques connaissent, mais permet à l’apprentissage automatique avancé de découvrir des régularités subtiles que les outils anciens manquaient. De meilleurs tableaux input–output régionaux se traduisent par des estimations plus crédibles de la manière dont les chocs locaux se propagent, quels secteurs sont les plus critiques et comment les politiques se répercuteront sur l’emploi, les revenus et les émissions. Bien que la méthode dépende encore de bonnes données d’entraînement et nécessite plus de puissance de calcul que les approches traditionnelles, ses performances solides suggèrent que la science des données moderne peut affiner sensiblement la façon dont nous observons le développement régional, la résilience et le changement structurel.
Citation: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Mots-clés: tableaux input–output régionaux, réseaux économiques, apprentissage automatique, modèles génératifs, développement régional