Clear Sky Science · pt
Acompanhando as regiões: um quadro híbrido de aprendizado de máquina para estimar matrizes input–output regionais
Por que as economias regionais importam
Quando uma fábrica fecha, um novo hospital abre ou um porto é ampliado, os efeitos se propagam muito além do local de trabalho imediato. Economistas usam detalhadas tabelas "input–output" para traçar como dinheiro e empregos fluem entre setores como agricultura, manufatura e serviços. Ainda assim, para a maioria das regiões dentro dos países, construir essas tabelas é tão caro e exige tantos dados que elas são atualizadas raramente, se é que são. Este artigo apresenta uma nova forma de estimar esses mapas econômicos regionais usando aprendizado de máquina moderno, prometendo ferramentas mais rápidas e precisas para planejadores, analistas e qualquer pessoa interessada em como as economias locais estão conectadas.
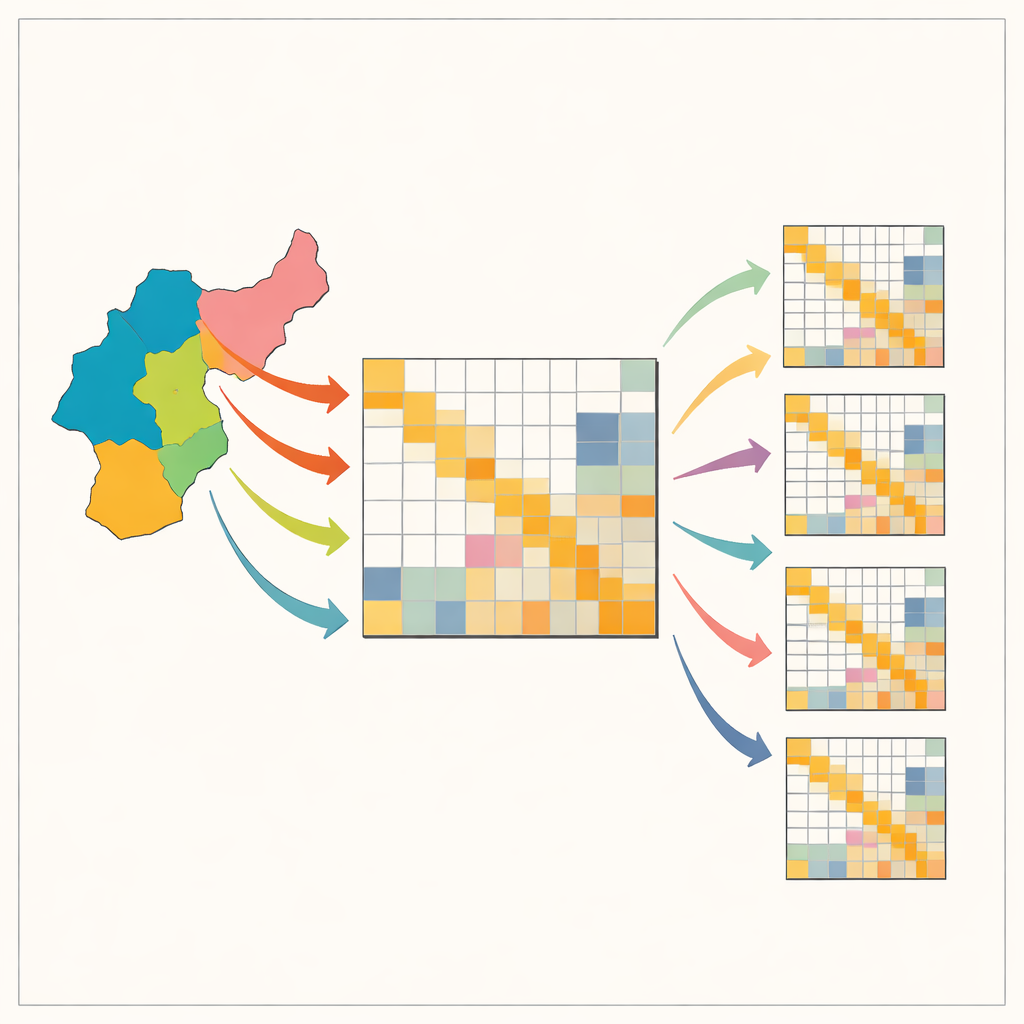
O quebra-cabeça de mapear os elos econômicos locais
As tabelas input–output descrevem quem compra o quê de quem em uma economia: quanto aço os fabricantes de automóveis compram, quantos serviços jurídicos os fabricantes utilizam, e assim por diante. Existem tabelas nacionais para muitos países, mas versões locais — para estados, províncias ou regiões metropolitanas — muitas vezes estão ausentes porque exigem grandes e caros levantamentos. Para contornar isso, economistas normalmente partem da tabela nacional e a remodelam com receitas matemáticas simples para que corresponda aos totais regionais conhecidos, como emprego ou produção por setor. Atalhos populares, com nomes como location quotients e RAS, são baratos e rápidos, mas podem distorcer padrões cruciais, especialmente a tendência das indústrias de comprar fortemente de si mesmas e de poucos parceiros-chave. Essas distorções podem induzir a erros em decisões sobre infraestrutura, política climática ou preparação para choques.
Misturando economia clássica com novos algoritmos
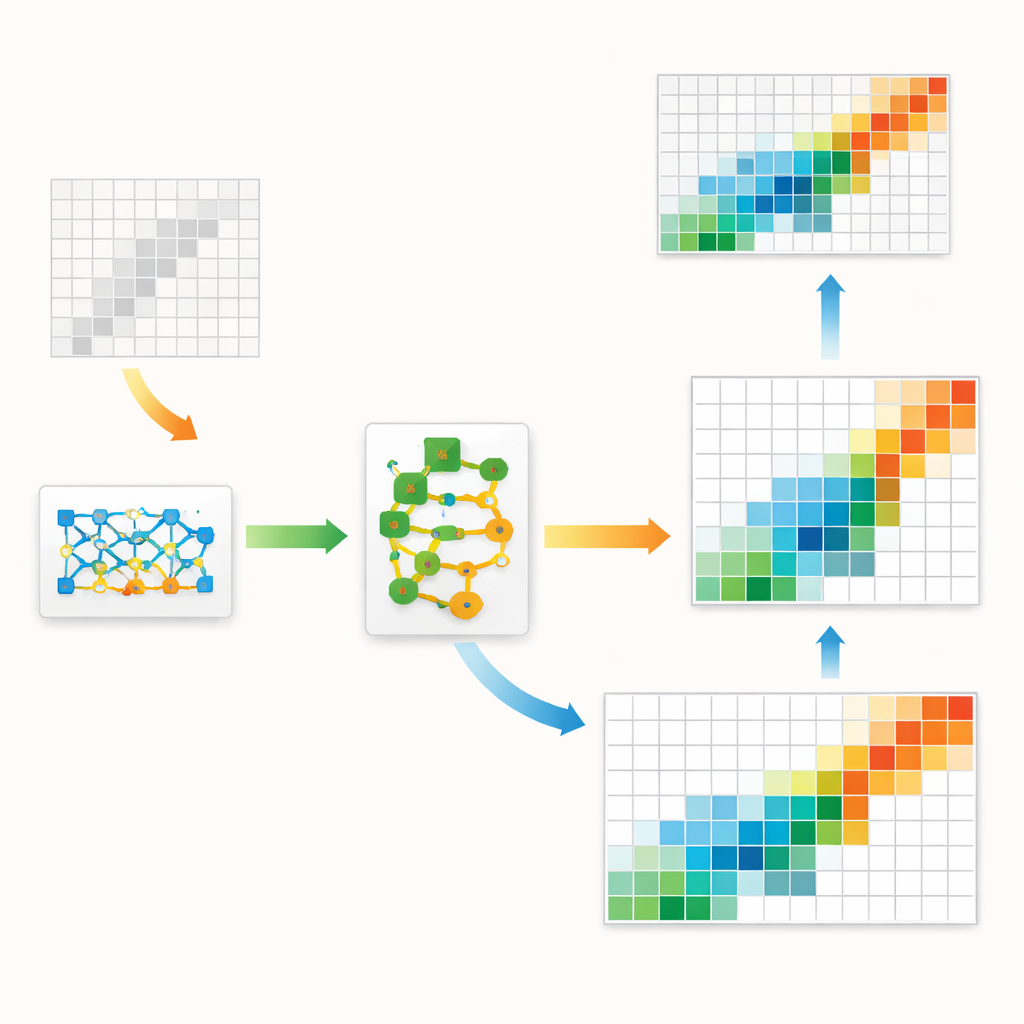
Os autores propõem uma estrutura híbrida que casa a estrutura econômica clássica com inteligência artificial de ponta. No núcleo está um tipo de modelo generativo chamado GAN, comumente usado para criar imagens realistas. Aqui, em vez de imagens, o GAN aprende a gerar tabelas input–output inteiras que se assemelham às observadas em dados históricos. Uma camada interna especial força cada tabela gerada a respeitar rígidas regras contábeis: os totais de linhas e colunas devem coincidir com os números regionais conhecidos e as entradas não podem ser negativas. Isso mantém o modelo de aprendizado de máquina ancorado na economia básica em vez de deixá-lo perseguir apenas padrões estatísticos.
Refinando o rascunho
Mesmo um GAN bem treinado tende a cometer pequenos erros sistemáticos — por exemplo, subestimar ligeiramente o quanto certos setores negociam consigo mesmos. Para corrigir isso, os autores acrescentam uma segunda etapa conhecida como residual boosting. Depois que o GAN produz sua melhor estimativa, um conjunto separado de modelos em ensemble baseados em árvores de decisão aprende os erros típicos que ele comete e prevê uma correção. A tabela corrigida é então ajustada suavemente para evitar valores irreais. Esse projeto em duas etapas tira proveito da habilidade do GAN em captar o quadro geral — como a forma e a concentração dos fluxos — enquanto usa o booster para afiar os detalhes locais. O método também é informado pelo fato de que economias reais têm alguns fluxos muito grandes e muitos fluxos minúsculos, um padrão assimétrico que o modelo é explicitamente estimulado a imitar.
Testando o método
Para verificar se essa abordagem híbrida funciona na prática, os autores a testam em dois grandes conjuntos de dados: uma coleção de tabelas nacionais de vários países e um conjunto de tabelas input–output mundiais que descrevem cadeias de suprimento globais através de dezenas de indústrias e regiões. Como as tabelas verdadeiras são conhecidas nesses casos, os pesquisadores podem comparar suas estimativas diretamente com a realidade e com versões aprimoradas do método RAS tradicional. Em uma ampla gama de métricas — ajuste geral, erros médios, quão bem a diagonal principal é reproduzida e quão de perto a dispersão desigual de fluxos grandes e pequenos é preservada — o método híbrido se destaca. No conjunto de dados nacional, ele melhora a medida padrão de qualidade de ajuste em quase nove pontos percentuais em relação ao RAS aprimorado, e mais do que duplica a precisão com que o auto-uso dentro dos setores é capturado. Nas tabelas globais, alcança um acordo ainda mais próximo, reproduzindo quase perfeitamente a estrutura subjacente.
O que isso significa para decisões do mundo real
Para não especialistas, a mensagem principal é que agora podemos construir retratos muito mais confiáveis das economias regionais sem enviar equipes de pesquisa porta a porta. O modelo híbrido mantém a lógica contábil familiar em que analistas de políticas confiam, mas permite que o aprendizado de máquina avançado descubra regularidades sutis que ferramentas mais antigas deixam passar. Tabelas input–output regionais melhores se traduzem em estimativas mais confiáveis de como choques locais se espalham, quais setores são mais críticos e como políticas irão reverberar em empregos, rendas e emissões. Embora o método ainda dependa de bons dados de treinamento e de mais poder computacional do que abordagens tradicionais, seu forte desempenho sugere que a ciência de dados moderna pode afiar significativamente as lentes com as quais vemos desenvolvimento regional, resiliência e mudança estrutural.
Citação: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Palavras-chave: matrizes input–output regionais, redes econômicas, aprendizado de máquina, modelos generativos, desenvolvimento regional