Clear Sky Science · ru
В ногу с регионами: гибридная рамочная модель машинного обучения для оценки региональных таблиц «затраты — выпуск»
Почему важны региональные экономики
Когда закрывается завод, открывается новая больница или расширяется порт, последствия распространяются далеко за пределы непосредственного рабочего места. Экономисты используют подробные таблицы «затраты–выпуск», чтобы проследить, как деньги и рабочие места перемещаются между секторами, такими как сельское хозяйство, производство и услуги. Однако для большинства регионов внутри стран составление таких таблиц дорого и требует больших объёмов данных, поэтому они обновляются редко или вовсе отсутствуют. В этой статье представлен новый способ оценки этих региональных экономических карт с помощью современных методов машинного обучения, обещающий более быстрые и точные инструменты для планировщиков, аналитиков и всех, кого интересует устройство местных экономик.
Задача картирования локальных экономических связей
Таблицы затрат–выпуска описывают, кто и что покупает в экономике: сколько стали закупают автозаводы, сколько юридических услуг используют производители и так далее. Национальные таблицы существуют во многих странах, но локальные версии — для штатов, провинций или городских регионов — часто отсутствуют, поскольку требуют крупных и дорогостоящих опросов. Чтобы обойти это, экономисты обычно берут национальную таблицу и преобразуют её простыми математическими приёмами так, чтобы она соответствовала известным региональным суммам, таким как занятость или выпуск по секторам. Популярные упрощения, такие как location quotients и метод RAS, дешёвы и быстры, но могут искажать важные закономерности, особенно склонность отраслей интенсивно покупать у самих себя и у нескольких ключевых партнёров. Эти искажения могут ввести в заблуждение при принятии решений по инфраструктуре, климатической политике или подготовке к шокам.
Сочетание классической экономики и новых алгоритмов
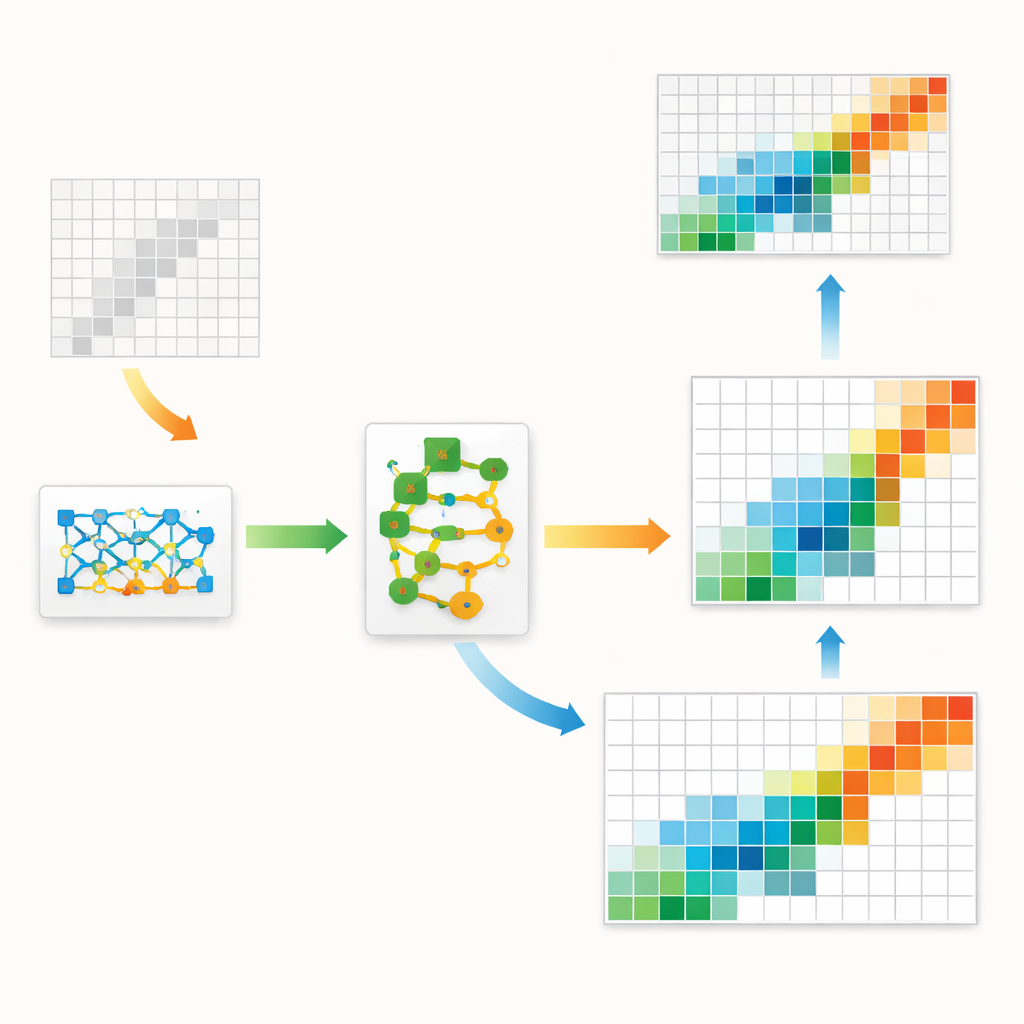
Авторы предлагают гибридную рамочную модель, которая сочетает классическую экономическую структуру с передними достижениями искусственного интеллекта. В её основе — тип генеративной модели, называемой GAN, обычно используемой для создания реалистичных изображений. Здесь, вместо картинок, GAN учится генерировать целые таблицы затрат–выпуска, похожие на наблюдаемые в исторических данных. Особый внутренний слой заставляет каждую сгенерированную таблицу соблюдать жёсткие бухгалтерские правила: суммы по строкам и столбцам должны соответствовать известным региональным показателям, а значения не могут быть отрицательными. Это удерживает модель машинного обучения в рамках базовой экономической логики, не позволяя ей гнаться только за статистическими паттернами.
Доработка черновика
Даже хорошо обученный GAN склонен допускать небольшие систематические ошибки — например, слегка недооценивать силу внутрисекторной торговли. Чтобы исправить это, авторы добавляют второй этап, известный как residual boosting. После того как GAN выдаёт свой лучший вариант, отдельный ансамбль деревьев решений изучает типичные ошибки и предсказывает поправку. Исправленная таблица затем аккуратно корректируется, чтобы избежать нереалистичных значений. Такая двухэтапная конструкция использует способность GAN захватывать общую картину — форму и концентрацию потоков — а бустер уточняет локальные детали. Метод также учитывает, что в реальной экономике есть несколько очень крупных потоков и множество крошечных, — асимметричный паттерн, который модели явным образом предлагается воспроизводить.
Проверка метода на практике
Чтобы выяснить, работает ли этот гибридный подход на практике, авторы тестируют его на двух крупных наборах данных: сборнике национальных таблиц многих стран и наборе мировых таблиц затрат–выпуска, описывающих глобальные цепочки поставок по десяткам отраслей и регионов. Поскольку в этих случаях истинные таблицы известны, исследователи могут напрямую сравнить свои оценки с реальностью и с улучшенными версиями традиционного метода RAS. По широкому набору критериев — общая согласованность, средние ошибки, точность воспроизведения главной диагонали и сохранение неравномерного распределения крупных и мелких потоков — гибридный метод оказывается впереди. В национальном наборе данных он улучшает стандартную меру качества подгонки почти на девять процентных пунктов по сравнению с улучшенным RAS и более чем вдвое повышает точность захвата внутрисекторного самопотребления. На глобальных таблицах он достигает ещё более тесного соответствия, почти идеально воспроизводя исходную структуру.
Что это значит для практических решений
Для неспециалистов ключевая мысль в том, что теперь мы можем строить гораздо более надёжные представления о региональных экономиках без обхода с опросными бригадами от двери к двери. Гибридная модель сохраняет привычную бухгалтерскую логику, которой доверяют аналитики политики, но позволяет продвинутому машинному обучению обнаруживать тонкие закономерности, которые старые инструменты пропускают. Улучшенные региональные таблицы затрат–выпуска переводятся в более достоверные оценки того, как локальные шоки распространяются, какие сектора наиболее критичны и как политики отзовутся в занятости, доходах и выбросах. Хотя метод по‑прежнему зависит от наличия хороших обучающих данных и требует больше вычислительных ресурсов, чем традиционные подходы, его высокая эффективность указывает на то, что современная наука о данных может существенно улучшить наше понимание регионального развития, устойчивости и структурных изменений.
Цитирование: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Ключевые слова: региональные таблицы затрат–выпуска, экономические сети, машинное обучение, генеративные модели, региональное развитие