Clear Sky Science · de
Mit den Regionen Schritt halten: ein hybrides Machine-Learning‑Rahmenwerk zur Schätzung regionaler Input‑Output‑Tabellen
Warum regionale Volkswirtschaften wichtig sind
Wenn eine Fabrik schließt, ein neues Krankenhaus eröffnet oder ein Hafen erweitert wird, wirken sich die Folgen weit über den unmittelbaren Arbeitsplatz hinaus aus. Ökonominnen und Ökonomen verwenden detaillierte „Input‑Output“-Tabellen, um nachzuzeichnen, wie Geld und Arbeitsplätze zwischen Branchen wie Landwirtschaft, Industrie und Dienstleistungen fließen. Für die meisten Regionen innerhalb von Staaten sind solche Tabellen jedoch so kostspielig und datenintensiv in der Erstellung, dass sie selten oder gar nicht aktualisiert werden. Dieser Artikel stellt einen neuen Weg vor, diese regionalen Wirtschaftslandkarten mithilfe moderner Machine‑Learning‑Methoden zu schätzen, und verspricht schnellere und genauere Werkzeuge für Planer, Analysten und alle, die daran interessiert sind, wie lokale Wirtschaftsräume miteinander vernetzt sind.
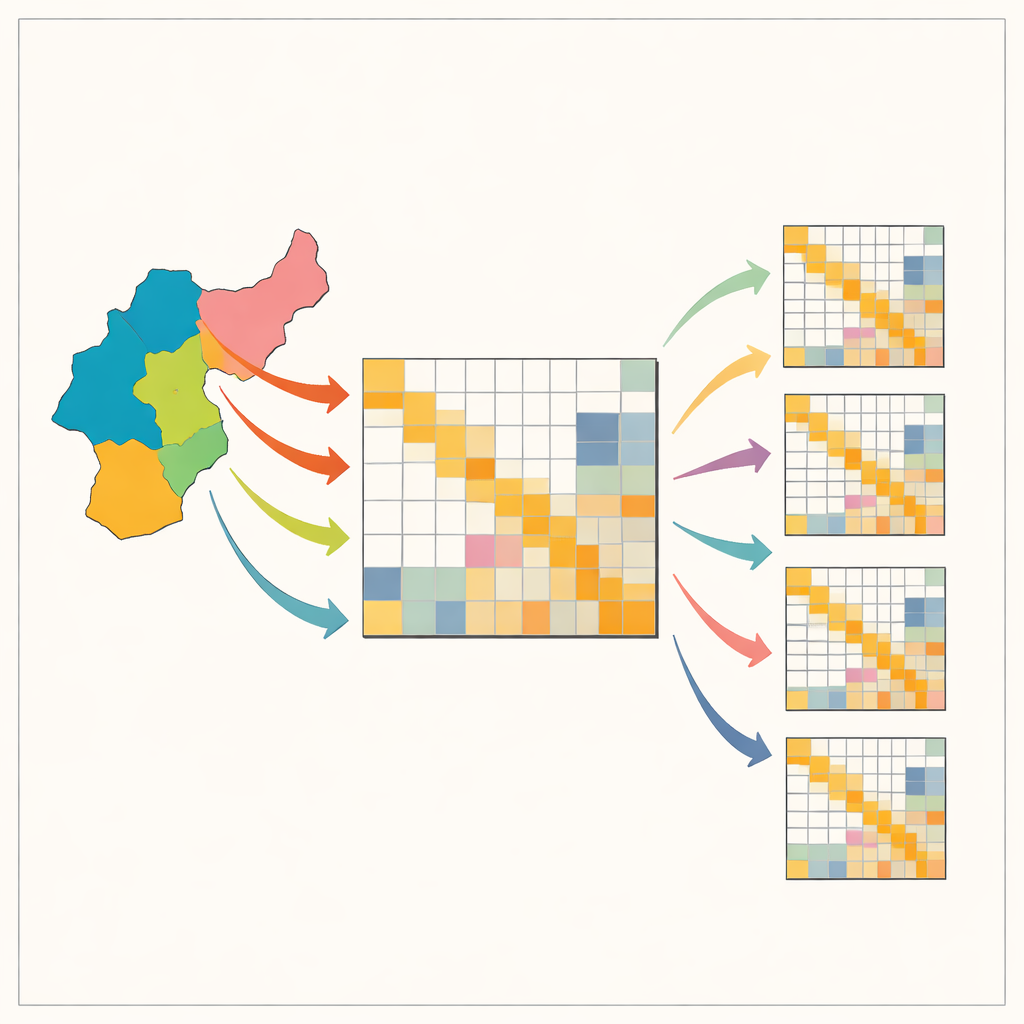
Das Rätsel der Abbildung lokaler Wirtschaftsverflechtungen
Input‑Output‑Tabellen beschreiben, wer in einer Volkswirtschaft was von wem kauft: wie viel Stahl Autohersteller beziehen, wie viele juristische Dienstleistungen Produktionsbetriebe in Anspruch nehmen, und so weiter. Nationale Tabellen existieren für viele Länder, doch lokale Versionen — für Bundesländer, Provinzen oder Stadtregionen — fehlen oft, weil sie große, teure Erhebungen erfordern. Um das zu umgehen, starten Ökonominnen und Ökonomen üblicherweise mit der nationalen Tabelle und formen sie mit einfachen mathematischen Verfahren so um, dass sie zu bekannten regionalen Summen passt, etwa Beschäftigung oder Produktion nach Sektor. Beliebte Abkürzungen mit Namen wie Location Quotients oder RAS sind billig und schnell, können aber entscheidende Muster verzerren, insbesondere die Neigung von Branchen, stark untereinander oder gegenüber wenigen wichtigen Partnern einzukaufen. Solche Verzerrungen können Fehlentscheidungen bei Infrastrukturplanung, Klimapolitik oder der Vorbereitung auf externe Schocks begünstigen.
Alte ökonomische Einsichten mit neuen Algorithmen verbinden
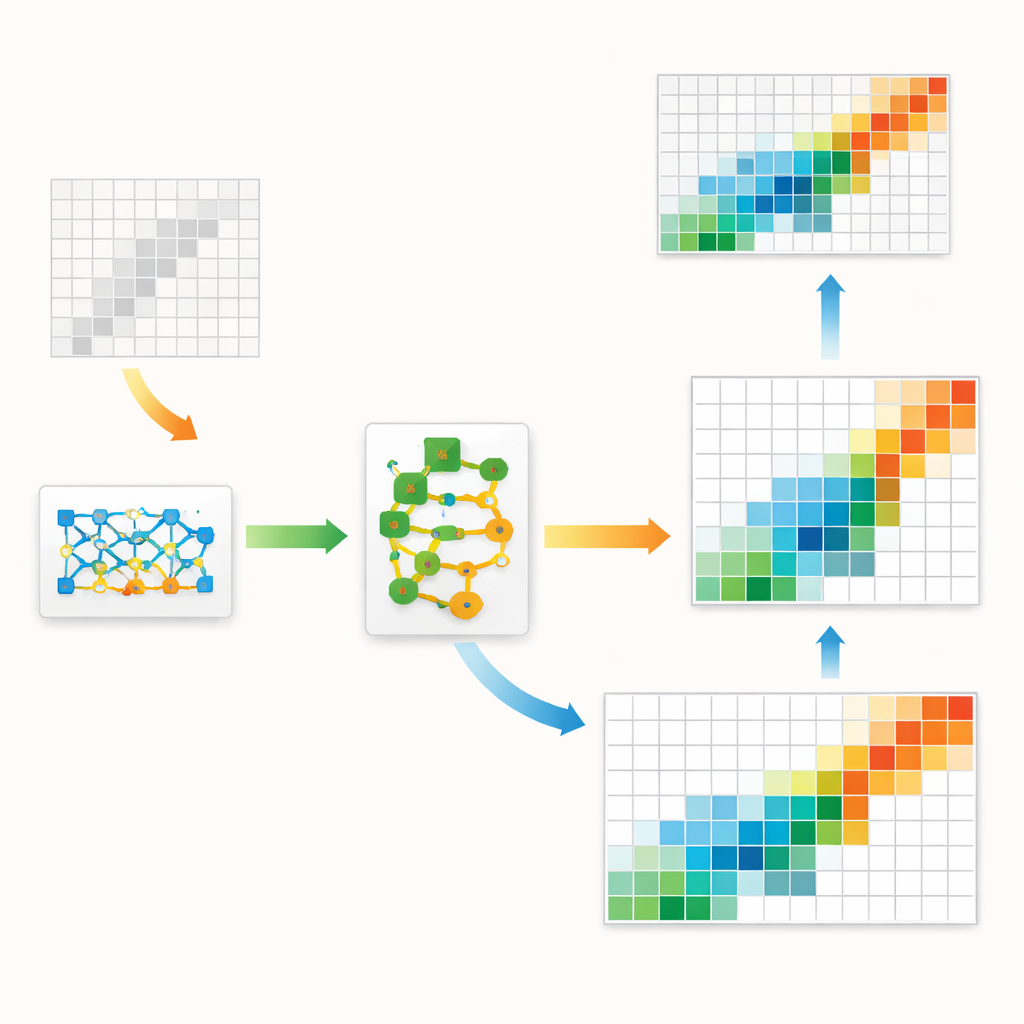
Die Autorinnen und Autoren schlagen ein hybrides Rahmenwerk vor, das klassische ökonomische Struktur mit moderner künstlicher Intelligenz verheiratet. Im Kern steht eine Art generatives Modell namens GAN, das häufig zum Erzeugen realistischer Bilder verwendet wird. Hier lernt das GAN statt Bildern ganze Input‑Output‑Tabellen zu erzeugen, die denen in historischen Daten ähneln. Eine spezielle interne Schicht zwingt jede generierte Tabelle, harte Buchungsregeln einzuhalten: Zeilen‑ und Spaltensummen müssen mit bekannten regionalen Größen übereinstimmen und Einträge dürfen nicht negativ sein. Das verankert das Machine‑Learning‑Modell in grundlegender Ökonomie, anstatt es rein statistischen Mustern nachlaufen zu lassen.
Den Rohentwurf feinjustieren
Auch ein gut trainiertes GAN neigt dazu, kleine, systematische Fehler zu machen — etwa die Neigung mancher Sektoren zur Selbstverwendung leicht zu unterschätzen. Zur Korrektur fügen die Autorinnen und Autoren eine zweite Stufe hinzu, die als Residual‑Boosting bezeichnet wird. Nachdem das GAN seine beste Schätzung geliefert hat, lernt ein separates Ensemble von Entscheidungsbaum‑Modellen die typischen Fehler und sagt eine Korrektur voraus. Die korrigierte Tabelle wird dann sanft angepasst, um unrealistische Werte zu vermeiden. Dieses zweistufige Design nutzt die Stärke des GAN, das große Bild zu erfassen — etwa Form und Konzentration der Flüsse — und setzt den Booster ein, um lokale Details zu schärfen. Die Methode berücksichtigt außerdem, dass reale Volkswirtschaften wenige sehr große und viele sehr kleine Flüsse aufweisen, ein schiefes Muster, das das Modell explizit nachahmen soll.
Den Ansatz auf die Probe stellen
Um zu prüfen, ob dieser hybride Ansatz in der Praxis funktioniert, testen die Autorinnen und Autoren ihn an zwei großen Datensätzen: einer Sammlung nationaler Tabellen vieler Länder und einem Satz weltweiter Input‑Output‑Tabellen, die globale Lieferketten über Dutzende Branchen und Regionen beschreiben. Da in diesen Fällen die wahren Tabellen bekannt sind, können die Forschenden ihre Schätzungen direkt mit der Realität und mit verbesserten Versionen der traditionellen RAS‑Methode vergleichen. Über eine breite Palette von Messgrößen — Gesamtgüte der Anpassung, mittlere Fehler, Reproduktion der Hauptdiagonale und wie gut die ungleiche Verteilung großer und kleiner Flüsse erhalten bleibt — liegt die hybride Methode vorn. Im nationalen Datensatz verbessert sie die standardmäßige Gütemaßzahl um nahezu neun Prozentpunkte gegenüber verbessertem RAS und verdoppelt mehr als die Genauigkeit, mit der die Selbstverwendung innerhalb von Sektoren erfasst wird. Bei den globalen Tabellen erzielt sie noch engere Übereinstimmung und reproduziert nahezu perfekt die zugrundeliegende Struktur.
Was das für Entscheidungen in der Praxis bedeutet
Für Nicht‑Spezialisten lautet die Kernbotschaft: Wir können jetzt wesentlich verlässlichere Abbildungen regionaler Ökonomien erstellen, ohne Erhebungsteams Tür‑zu‑Tür zu schicken. Das hybride Modell bewahrt die vertraute buchhalterische Logik, der Politikberater vertrauen, erlaubt aber gleichzeitig fortgeschrittenem Machine Learning, subtile Regelmäßigkeiten zu entdecken, die ältere Werkzeuge übersehen. Bessere regionale Input‑Output‑Tabellen führen zu glaubwürdigeren Schätzungen darüber, wie lokale Schocks sich ausbreiten, welche Sektoren am kritischsten sind und wie sich Politiken auf Beschäftigung, Einkommen und Emissionen auswirken. Zwar hängt die Methode weiterhin von guten Trainingsdaten und mehr Rechenleistung als traditionelle Ansätze ab, doch ihre starke Leistung deutet an, dass moderne Data Science die Linse, durch die wir regionale Entwicklung, Resilienz und strukturellen Wandel betrachten, deutlich schärfen kann.
Zitation: De Pretis, F., Tortoli, D. & Caria, S. Keeping up with the regions: a hybrid machine learning framework for estimating regional input-output tables. Sci Rep 16, 10893 (2026). https://doi.org/10.1038/s41598-026-45382-8
Schlüsselwörter: regionale Input‑Output‑Tabellen, wirtschaftliche Netzwerke, Machine Learning, generative Modelle, regionale Entwicklung