Clear Sky Science · sv
Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing
Seeing Signs Through the Mist
On a foggy morning, even familiar roads can feel uncertain: highway signs fade into gray, lane markings blur, and digital displays become hard to read. For human drivers and automated systems alike, being able to reliably spot text in such poor visibility is crucial for safety. This study presents a way to teach computers to "see" written information—such as road signs and other traffic text—even when heavy fog makes images murky and low in contrast.
Why Fog Confuses Smart Cameras
Modern cars, traffic cameras, and delivery robots increasingly rely on computer vision to read words in everyday scenes. Deep-learning systems have become remarkably good at detecting text on clear images, from storefronts to license plates. But foggy weather still poses a stubborn problem. Fog reduces contrast, washes out colors, and softens edges, turning crisp letters into smeared, pale shapes. Many leading text-detection methods either miss these faint traces of writing or confuse bright but irrelevant regions—like reflections or parts of vehicles—for text. As a result, systems trained on standard clear-weather datasets can fail when conditions become hazy, just when reliable information might matter most.
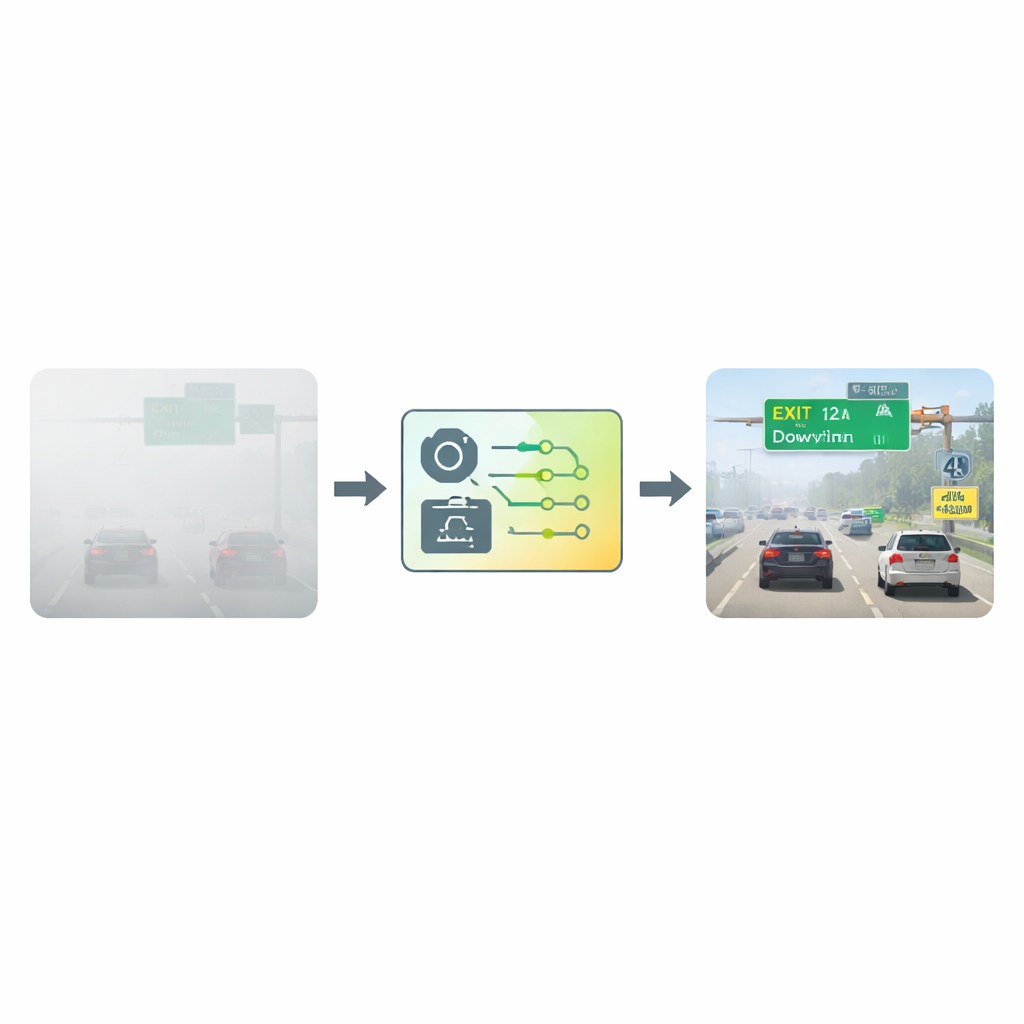
Cleaning Up the View Before Reading
The researchers tackled this challenge by building on a widely used text-detection framework called the Connectionist Text Proposal Network, or CTPN. Instead of feeding the network raw foggy images, they first pass each image through a specialized "defogging" step. This step is based on an atmospheric model that describes how light scatters in hazy air. By comparing how dark different parts of the image should be in normal conditions, the algorithm estimates how much fog is in front of each pixel and then mathematically "subtracts" the haze. The result is a clearer, higher-contrast image where letters and numbers stand out more sharply from their backgrounds, giving the detection network a much better starting point.
Teaching the Network to Follow Text Lines
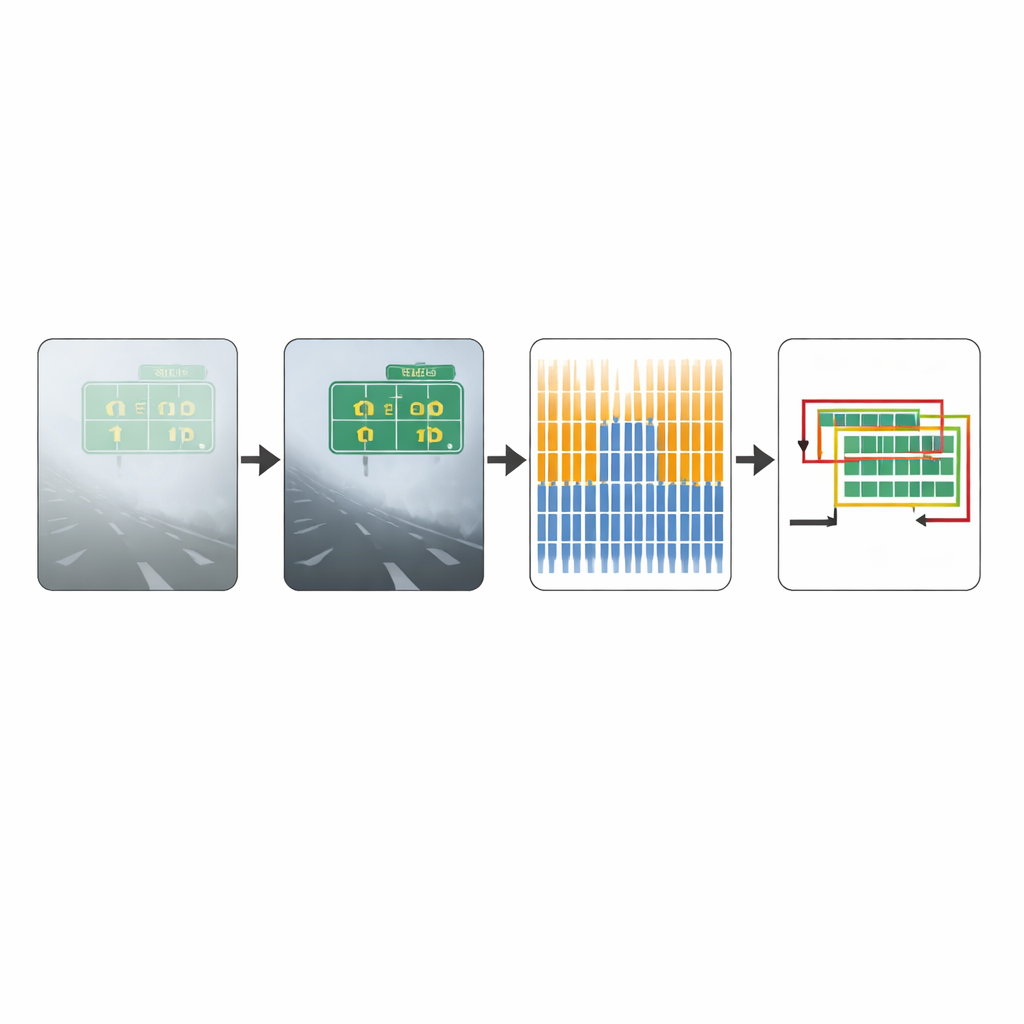
Once the image is cleaned up, the improved CTPN model analyzes it in small vertical slices, scanning across the scene to find text lines. It uses a deep feature extractor, originally designed for recognizing objects in photographs, to capture detailed patterns of edges and textures. On top of this, a bidirectional sequence module learns how neighboring slices fit together along a line of text, helping it distinguish real writing from scattered shapes that merely resemble characters. The network then proposes candidate boxes that might contain text and estimates their positions and heights with refined accuracy, even when the letters are partly blurred or irregularly arranged.
Smarter Filtering of Overlapping Boxes
Detecting text is only half the story; computers also need to decide which of many overlapping suggestions for text regions are actually correct. Traditional methods choose the strongest box and discard neighboring ones based on a fixed overlap threshold. A newer approach, called Soft-NMS, gently reduces the confidence of overlapping boxes instead of deleting them outright, often preserving closely spaced text. However, each method has weaknesses: strict filtering can cut off parts of real words, while soft filtering can leave too many overlapping boxes or highlight non-text objects. This work combines the strengths of both strategies. It computes results using each method separately, compares how their suggested boxes differ, and then blends the coordinates according to a learned rule. This hybrid post-processing keeps horizontal text boxes neat and reduces both missed detections and false alarms.
Putting the Method to the Test
To see how well their approach works, the authors evaluated it on two image collections. The first, a standard benchmark of everyday photographs, mostly contains clear-weather scenes. The second, created by the team, focuses on real foggy traffic images and is specifically designed to test performance in difficult visibility. On this fog-heavy dataset, the enhanced method detected many more true text regions than the original CTPN, while also slightly improving how often detections were correct. Overall, a combined accuracy score that balances missed and mistaken detections rose notably, indicating a substantial gain in reliability under adverse conditions. Visual examples show that where the original model overlooks road signs or misidentifies parts of vehicles as text, the improved system more cleanly outlines the actual writing.
Clearer Warnings When It Matters Most
In simple terms, this paper shows that teaching computers to first clear away fog in an image and then to filter their guesses more intelligently can make them much better at spotting text on the road. The improved system can pick out words on signs and other traffic-related text in scenes that are almost opaque to the naked eye. Such advances could help autonomous vehicles better understand their surroundings in poor weather, aid traffic monitoring systems, and even assist rescue operations where instructions or warnings must be read through smoke or haze. While the authors note that more work is needed to speed up the process and integrate all steps into one streamlined model, their results demonstrate a promising path toward safer, more weather-resilient machine vision.
Citering: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Nyckelord: scene text detection, foggy traffic images, image defogging, deep learning vision, autonomous driving perception