Clear Sky Science · it
Rilevamento robusto del testo in scene di traffico nebbiose usando un modello CTPN potenziato con pre-elaborazione di de-fogging
Vedere i segnali attraverso la nebbia
In una mattina nebbiosa anche strade familiari possono apparire insicure: i cartelli autostradali si dissolvono nel grigio, le linee di carreggiata si sfumano e i display digitali diventano difficili da leggere. Per i conducenti umani e per i sistemi automatizzati è cruciale poter individuare con affidabilità il testo in condizioni di visibilità scarsa per motivi di sicurezza. Questo studio presenta un metodo per insegnare ai computer a "vedere" le informazioni scritte — come segnali stradali e altri testi di traffico — anche quando la fitta nebbia rende le immagini torbide e a basso contrasto.
Perché la nebbia confonde le telecamere intelligenti
Le auto moderne, le telecamere del traffico e i robot per le consegne fanno sempre più affidamento sulla visione artificiale per leggere parole nelle scene quotidiane. I sistemi di deep learning sono diventati particolarmente abili nel rilevare il testo in immagini nitide, dalle vetrine alle targhe. Tuttavia la nebbia rimane un problema ostinato. La nebbia riduce il contrasto, annebbia i colori e ammorbidisce i bordi, trasformando lettere nette in forme sfocate e pallide. Molti dei principali metodi di rilevamento del testo non riconoscono queste tracce sbiadite o confondono regioni chiare ma irrilevanti — come riflessi o parti di veicoli — con il testo. Di conseguenza, i sistemi addestrati su dataset standard in condizioni di bel tempo possono fallire quando l’atmosfera diventa nebbiosa, proprio quando l’informazione affidabile sarebbe più utile.
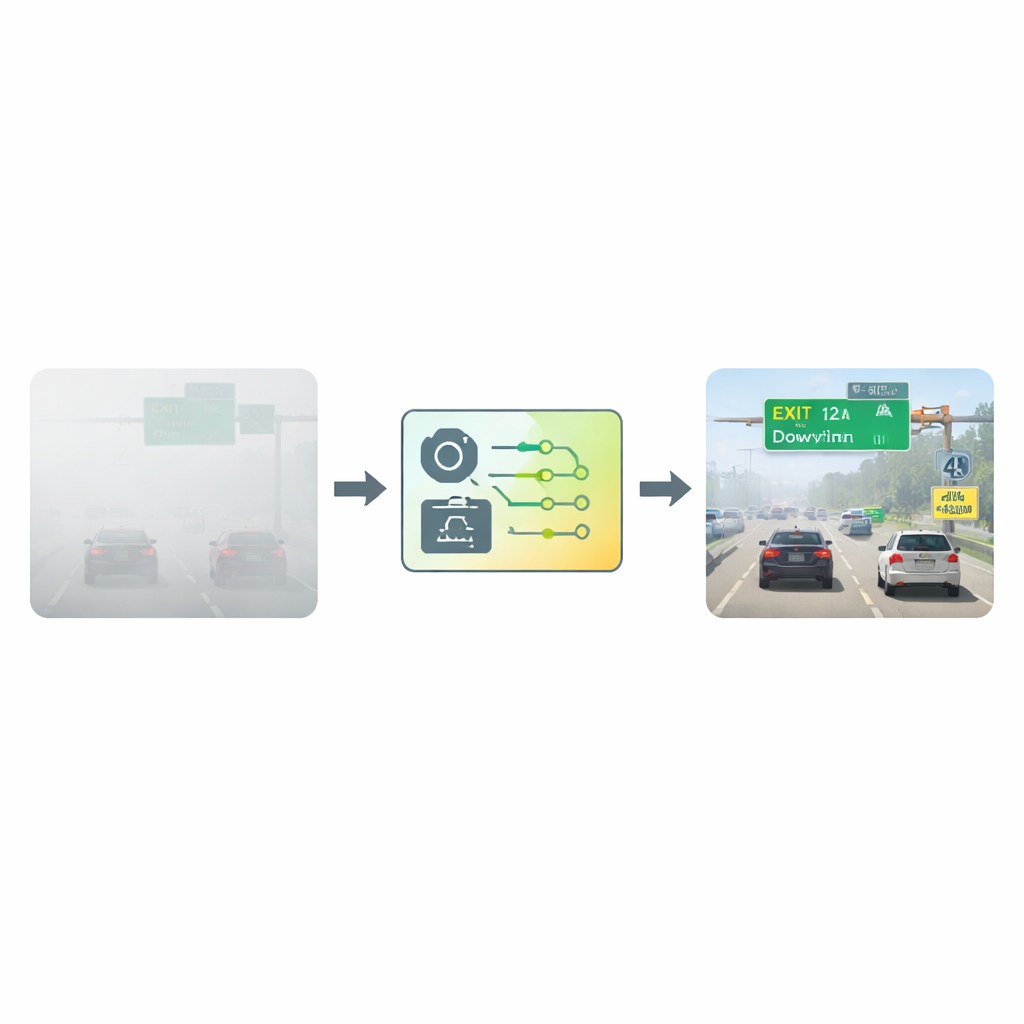
Pulire l’immagine prima di leggere
I ricercatori hanno affrontato questa sfida partendo da un framework di rilevamento del testo ampiamente usato chiamato Connectionist Text Proposal Network, o CTPN. Invece di fornire alla rete immagini nebbiose grezze, ogni immagine viene prima elaborata con un passaggio specializzato di "de-fogging". Questo passaggio si basa su un modello atmosferico che descrive come la luce si disperde in aria nebulosa. Confrontando quanto dovrebbero essere scure diverse parti dell’immagine in condizioni normali, l’algoritmo stima la quantità di nebbia davanti a ciascun pixel e poi ne sottrae matematicamente l’effetto. Il risultato è un’immagine più chiara e ad alto contrasto in cui lettere e numeri risaltano più nettamente sullo sfondo, offrendo alla rete di rilevamento un punto di partenza molto migliore.
Insegnare alla rete a seguire le linee di testo
Una volta ripulita l’immagine, il modello CTPN migliorato la analizza in piccole fette verticali, scansionando la scena per trovare linee di testo. Usa un estrattore di feature profondo, originariamente progettato per riconoscere oggetti nelle fotografie, per catturare pattern dettagliati di bordi e texture. Su questo livello, un modulo sequenziale bidirezionale apprende come le fette vicine si concatenano lungo una linea di testo, aiutando a distinguere la scrittura reale da forme sparse che solo assomigliano a caratteri. La rete propone quindi box candidati che potrebbero contenere testo e stima con maggiore precisione le loro posizioni e altezze, anche quando le lettere sono parzialmente sfocate o disposte in modo irregolare.
Filtraggio più intelligente dei box sovrapposti
Rilevare il testo è solo metà della storia; i computer devono anche decidere quali tra le molte proposte sovrapposte di regioni testuali siano effettivamente corrette. I metodi tradizionali scelgono il box più forte e scartano quelli vicini basandosi su una soglia fissa di sovrapposizione. Un approccio più recente, chiamato Soft-NMS, riduce gradualmente la confidenza dei box sovrapposti invece di eliminarli del tutto, spesso preservando il testo ravvicinato. Tuttavia ogni metodo ha punti deboli: un filtro troppo severo può troncare parti di parole reali, mentre il filtraggio soft può lasciare troppi box sovrapposti o evidenziare oggetti non testuali. Questo lavoro combina i punti di forza di entrambe le strategie. Calcola i risultati usando ciascun metodo separatamente, confronta come differiscono i box suggeriti e poi fonde le coordinate secondo una regola appresa. Questo post-processing ibrido mantiene ordinati i riquadri di testo orizzontale e riduce sia i mancati rilevamenti sia i falsi allarmi.
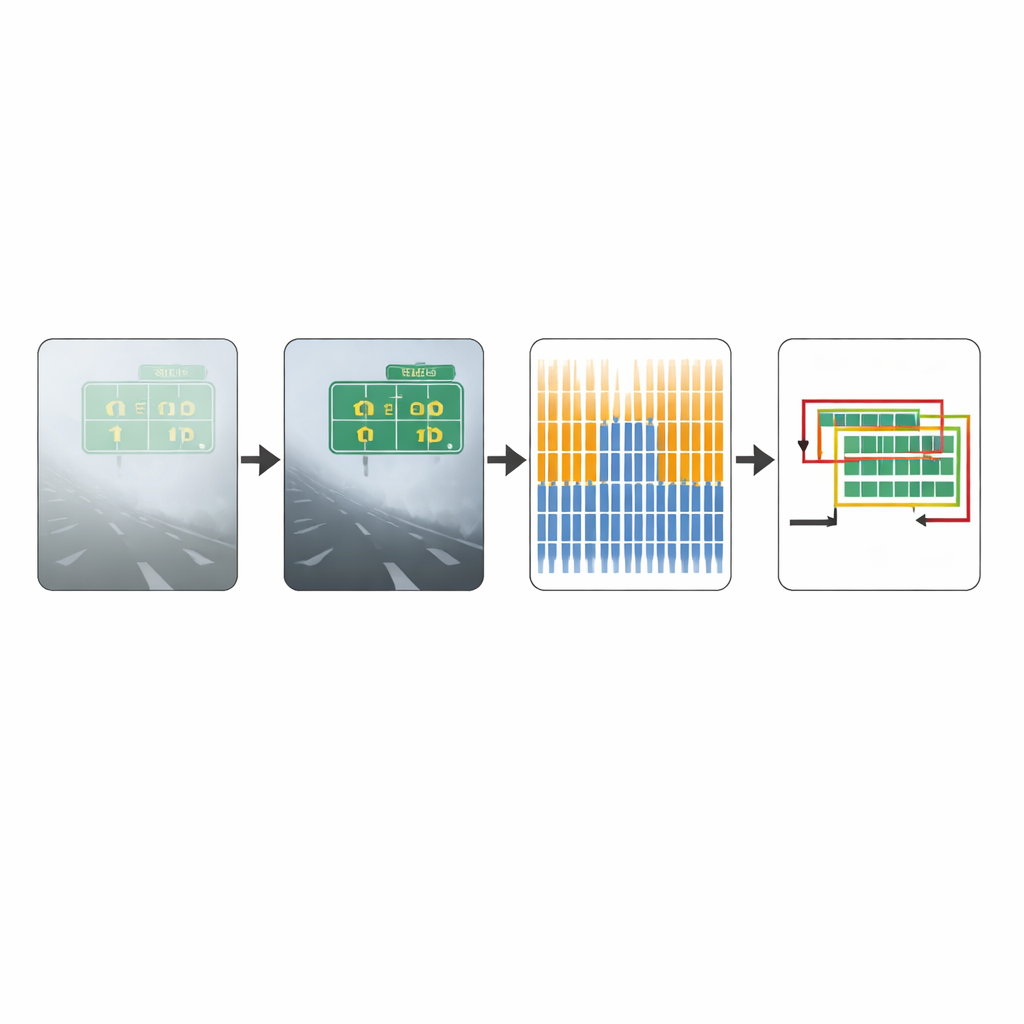
Mettere il metodo alla prova
Per valutare l’efficacia dell’approccio, gli autori lo hanno testato su due raccolte di immagini. La prima, un benchmark standard di fotografie quotidiane, contiene per lo più scene in condizioni di bel tempo. La seconda, creata dal team, è incentrata su immagini reali di traffico nebbioso ed è specificamente pensata per testare le prestazioni in visibilità difficili. Su questo dataset con forte presenza di nebbia, il metodo potenziato ha rilevato molte più regioni testuali vere rispetto al CTPN originale, migliorando anche lievemente la precisione delle rilevazioni. Nel complesso, un punteggio combinato di accuratezza che bilancia rilevamenti mancati e errati è aumentato in modo significativo, indicando un sensibile guadagno di affidabilità in condizioni avverse. Esempi visivi mostrano che, dove il modello originale trascura segnali stradali o scambia parti di veicoli per testo, il sistema migliorato delimita più nettamente la scrittura reale.
Avvisi più chiari quando conta di più
In termini semplici, questo articolo dimostra che insegnare ai computer a prima eliminare la nebbia in un’immagine e poi a filtrare le proprie ipotesi in modo più intelligente può renderli molto più efficaci nel riconoscere il testo sulla strada. Il sistema migliorato è in grado di individuare parole su cartelli e altri testi legati al traffico in scene quasi opache a occhio nudo. Tali progressi potrebbero aiutare i veicoli autonomi a comprendere meglio l’ambiente in condizioni meteorologiche avverse, supportare i sistemi di monitoraggio del traffico e persino assistere le operazioni di soccorso dove istruzioni o avvertimenti devono essere letti attraverso fumo o foschia. Pur notando che sono necessari ulteriori lavori per velocizzare il processo e integrare tutti i passaggi in un unico modello più snello, gli autori mostrano un percorso promettente verso una visione artificiale più sicura e resistente alle condizioni atmosferiche.
Citazione: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Parole chiave: rilevamento del testo in scena, immagini di traffico nebbiose, de-fogging delle immagini, visione deep learning, percezione guida autonoma