Clear Sky Science · fr
Détection robuste de texte dans des scènes de circulation brumeuses à l’aide d’un modèle CTPN amélioré avec prétraitement de désembuage
Voir les panneaux à travers la brume
Par un matin brumeux, même des routes familières peuvent sembler incertaines : les panneaux d’autoroute se fondent dans le gris, les marquages de voie s’estompent et les affichages numériques deviennent difficiles à lire. Pour les conducteurs humains comme pour les systèmes automatisés, pouvoir repérer de manière fiable du texte dans une telle faible visibilité est crucial pour la sécurité. Cette étude présente une méthode pour apprendre aux ordinateurs à « voir » les informations écrites — comme les panneaux routiers et autres textes liés à la circulation — même lorsque un épais brouillard rend les images trouble et peu contrastées.
Pourquoi la brume perturbe les caméras intelligentes
Les voitures modernes, les caméras de surveillance et les robots de livraison s’appuient de plus en plus sur la vision par ordinateur pour lire des mots dans des scènes quotidiennes. Les systèmes d’apprentissage profond sont devenus remarquablement bons pour détecter du texte sur des images nettes, des devantures de magasins aux plaques d’immatriculation. Mais le brouillard reste un problème tenace. Il réduit le contraste, atténue les couleurs et adoucit les contours, transformant des lettres nettes en formes pâles et floues. De nombreuses méthodes de détection de texte performantes manquent ces traces faibles d’écriture ou confondent des régions brillantes mais non pertinentes — comme des reflets ou des parties de véhicules — avec du texte. En conséquence, les systèmes entraînés sur des jeux de données en conditions claires peuvent échouer lorsque l’air devient brumeux, précisément quand l’information fiable est la plus importante.
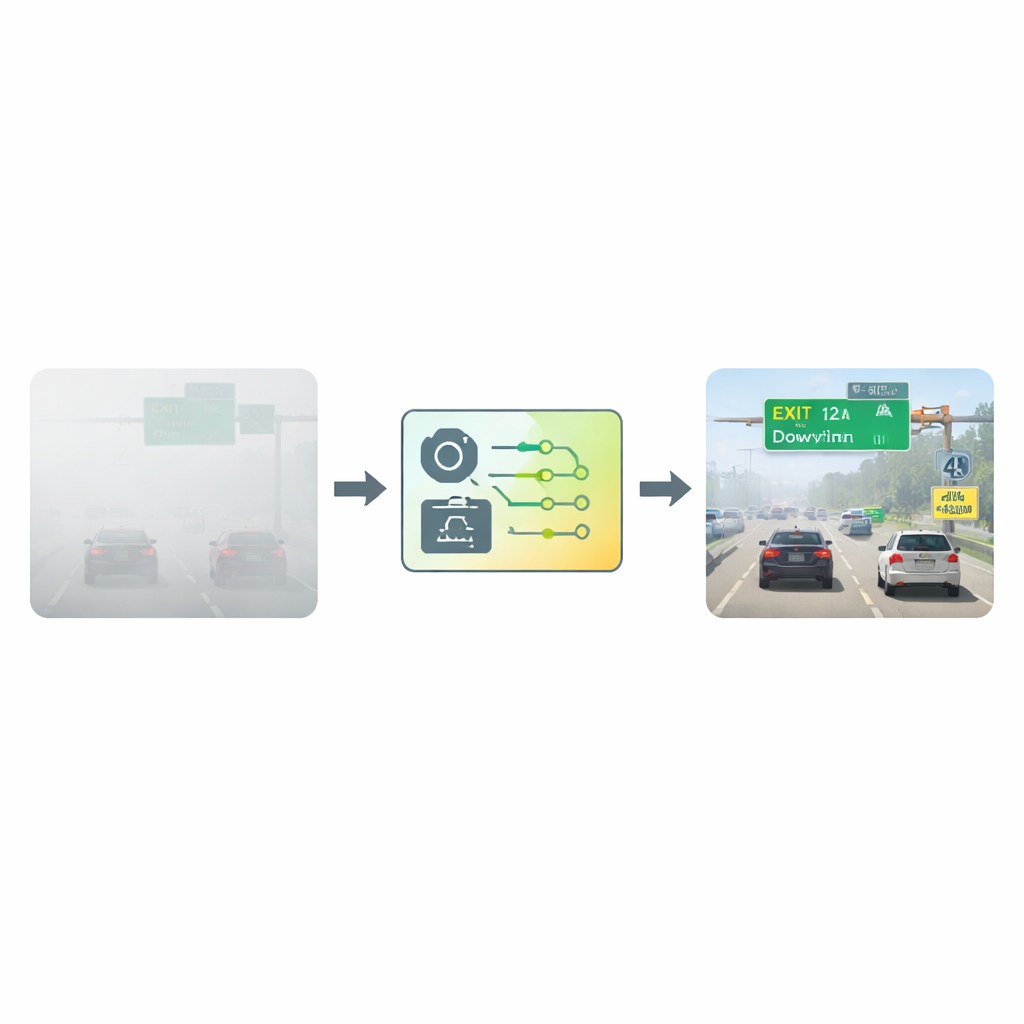
Nettoyer la vue avant de lire
Les chercheurs ont abordé ce défi en s’appuyant sur un cadre de détection de texte largement utilisé, le Connectionist Text Proposal Network (CTPN). Plutôt que d’alimenter le réseau avec les images brumeuses brutes, ils soumettent d’abord chaque image à une étape spécialisée de « désembuage ». Cette étape repose sur un modèle atmosphérique qui décrit la diffusion de la lumière dans un air brumeux. En comparant l’assombrissement attendu de différentes parties de l’image en conditions normales, l’algorithme estime la quantité de brouillard devant chaque pixel puis « soustrait » mathématiquement la brume. Le résultat est une image plus claire et à contraste augmenté où les lettres et les chiffres se détachent plus nettement de leur arrière-plan, offrant au réseau de détection un point de départ beaucoup meilleur.
Apprendre au réseau à suivre des lignes de texte
Une fois l’image nettoyée, le modèle CTPN amélioré l’analyse par petites tranches verticales, parcourant la scène pour repérer des lignes de texte. Il utilise un extracteur de caractéristiques profondes, initialement conçu pour reconnaître des objets dans des photographies, afin de capturer des motifs détaillés d’arêtes et de textures. Par-dessus cela, un module séquentiel bidirectionnel apprend comment les tranches voisines s’assemblent le long d’une ligne de texte, l’aidant à distinguer un véritable écrit d’éléments épars qui ressemblent seulement à des caractères. Le réseau propose alors des boîtes candidates susceptibles de contenir du texte et estime leurs positions et hauteurs avec une précision affinée, même lorsque les lettres sont partiellement floues ou disposées de façon irrégulière.
Filtrage plus intelligent des boîtes qui se chevauchent
Détecter du texte n’est que la moitié de l’histoire ; les ordinateurs doivent aussi décider lesquelles des nombreuses propositions chevauchantes pour des régions de texte sont réellement correctes. Les méthodes traditionnelles choisissent la boîte la plus forte et éliminent les voisines selon un seuil de recouvrement fixe. Une approche plus récente, appelée Soft-NMS, réduit progressivement la confiance des boîtes chevauchantes au lieu de les supprimer complètement, ce qui préserve souvent du texte étroitement espacé. Toutefois, chaque méthode a ses faiblesses : un filtrage strict peut couper des parties de mots réels, tandis qu’un filtrage « doux » peut laisser trop de boîtes chevauchantes ou mettre en avant des objets non textuels. Ce travail combine les forces des deux stratégies. Il calcule les résultats avec chaque méthode séparément, compare la divergence de leurs boîtes proposées, puis fusionne les coordonnées selon une règle apprise. Ce post-traitement hybride maintient les boîtes de texte horizontales propres et réduit à la fois les détections manquées et les fausses alertes.
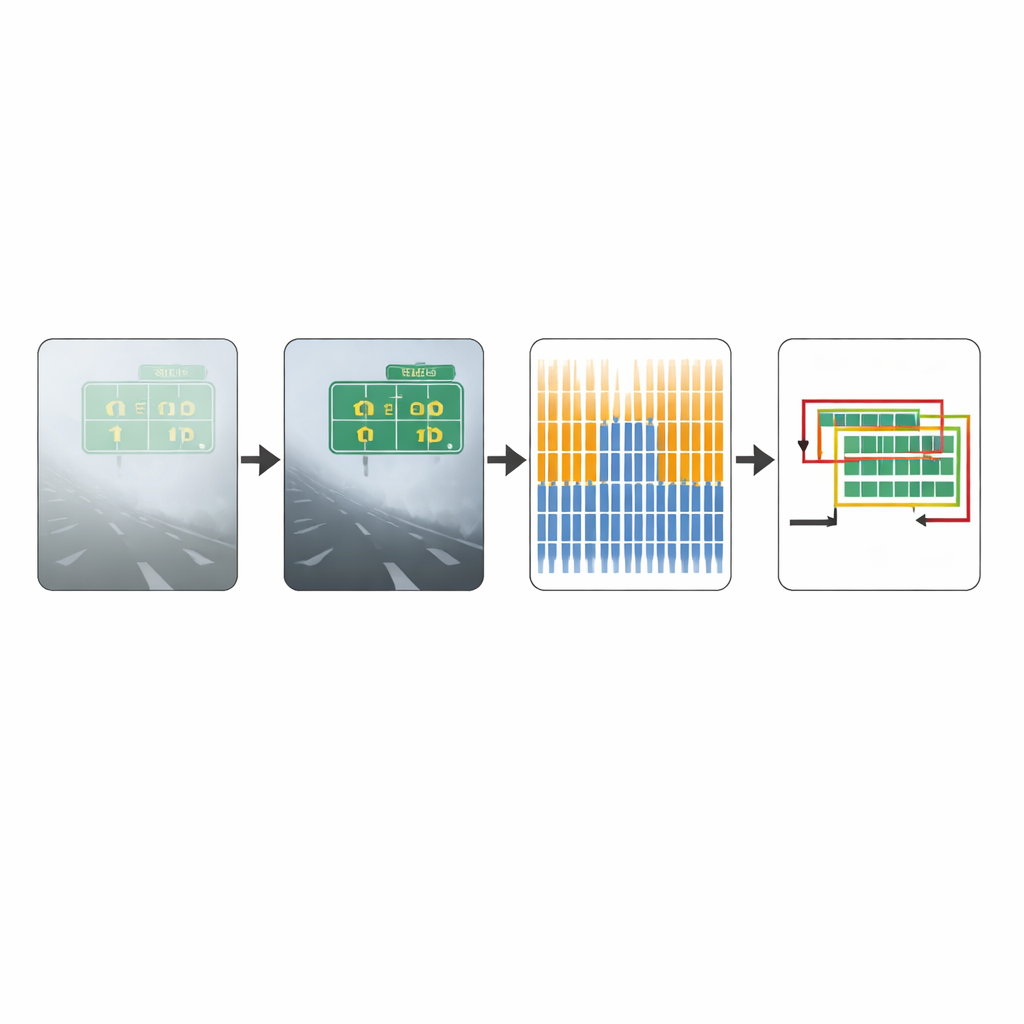
Mettre la méthode à l’épreuve
Pour évaluer l’efficacité de leur approche, les auteurs l’ont testée sur deux collections d’images. La première, une référence standard de photographies quotidiennes, contient majoritairement des scènes par temps clair. La seconde, créée par l’équipe, se concentre sur des images de circulation réellement brumeuses et a été conçue spécifiquement pour mesurer les performances en faible visibilité. Sur ce jeu de données fortement affecté par le brouillard, la méthode améliorée a détecté beaucoup plus de régions de texte réelles que le CTPN d’origine, tout en améliorant légèrement la précision des détections correctes. Dans l’ensemble, un score combiné qui équilibre les détections manquées et erronées a augmenté de manière notable, indiquant un gain substantiel de fiabilité dans des conditions défavorables. Des exemples visuels montrent que là où le modèle original ignore des panneaux routiers ou confond des parties de véhicules avec du texte, le système amélioré trace plus proprement l’écriture réelle.
Alerter plus clairement quand cela compte le plus
En termes simples, cet article montre que faire d’abord disparaître la brume d’une image puis filtrer plus intelligemment les hypothèses permet aux ordinateurs d’être bien meilleurs pour repérer du texte sur la route. Le système amélioré peut extraire des mots sur des panneaux et d’autres textes liés à la circulation dans des scènes presque opaques à l’œil nu. De telles avancées pourraient aider les véhicules autonomes à mieux comprendre leur environnement par mauvais temps, soutenir les systèmes de surveillance du trafic et même assister les opérations de secours où des consignes ou avertissements doivent être lus à travers de la fumée ou de la brume. Bien que les auteurs notent qu’il reste du travail pour accélérer le procédé et intégrer toutes les étapes dans un modèle unique et optimisé, leurs résultats démontrent une voie prometteuse vers une vision machine plus sûre et plus résistante aux intempéries.
Citation: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Mots-clés: détection de texte en scène, images de circulation brumeuses, désembuage d’image, vision par apprentissage profond, perception pour conduite autonome