Clear Sky Science · pl
Odporny na mgłę wykrywacz tekstu w scenach drogowych oparty na ulepszonym modelu CTPN z wstępnym odmgławianiem
Widzieć znaki przez mgłę
Pewnego mgławego poranka nawet znane drogi mogą wydawać się niepewne: znaki autostradowe zlewają się z popiołowym tłem, oznakowanie pasa rozmywa się, a wyświetlacze stają się trudne do odczytania. Zarówno dla kierowców, jak i systemów zautomatyzowanych, możliwość niezawodnego wykrywania tekstu przy słabej widoczności jest kluczowa dla bezpieczeństwa. W tym badaniu przedstawiono metodę uczenia komputerów „czytania” informacji — takich jak znaki drogowe i inne napisy związane z ruchem — nawet gdy silna mgła powoduje, że obrazy są zamglone i o niskim kontraście.
Dlaczego mgła myli inteligentne kamery
Nowoczesne samochody, kamery drogowe i roboty dostawcze coraz częściej polegają na widzeniu komputerowym, by odczytywać napisy w codziennych scenach. Systemy głębokiego uczenia znacznie polepszyły wykrywanie tekstu na wyraźnych obrazach — od witryn sklepowych po tablice rejestracyjne. Pogoda mglista wciąż jednak stwarza uporczywy problem. Mgła zmniejsza kontrast, wypłukuje kolory i zmiękcza krawędzie, zmieniając ostre litery w rozmyte, blade kształty. Wiele czołowych metod wykrywania tekstu albo pomija te słabe ślady pisma, albo myli jasne, nieistotne rejony — na przykład odbicia czy fragmenty pojazdów — z tekstem. W rezultacie systemy trenowane na standardowych, pogodowo klarownych zbiorach danych zawodzą, gdy warunki stają się mgliste, czyli właśnie wtedy, gdy niezawodna informacja może być najważniejsza.
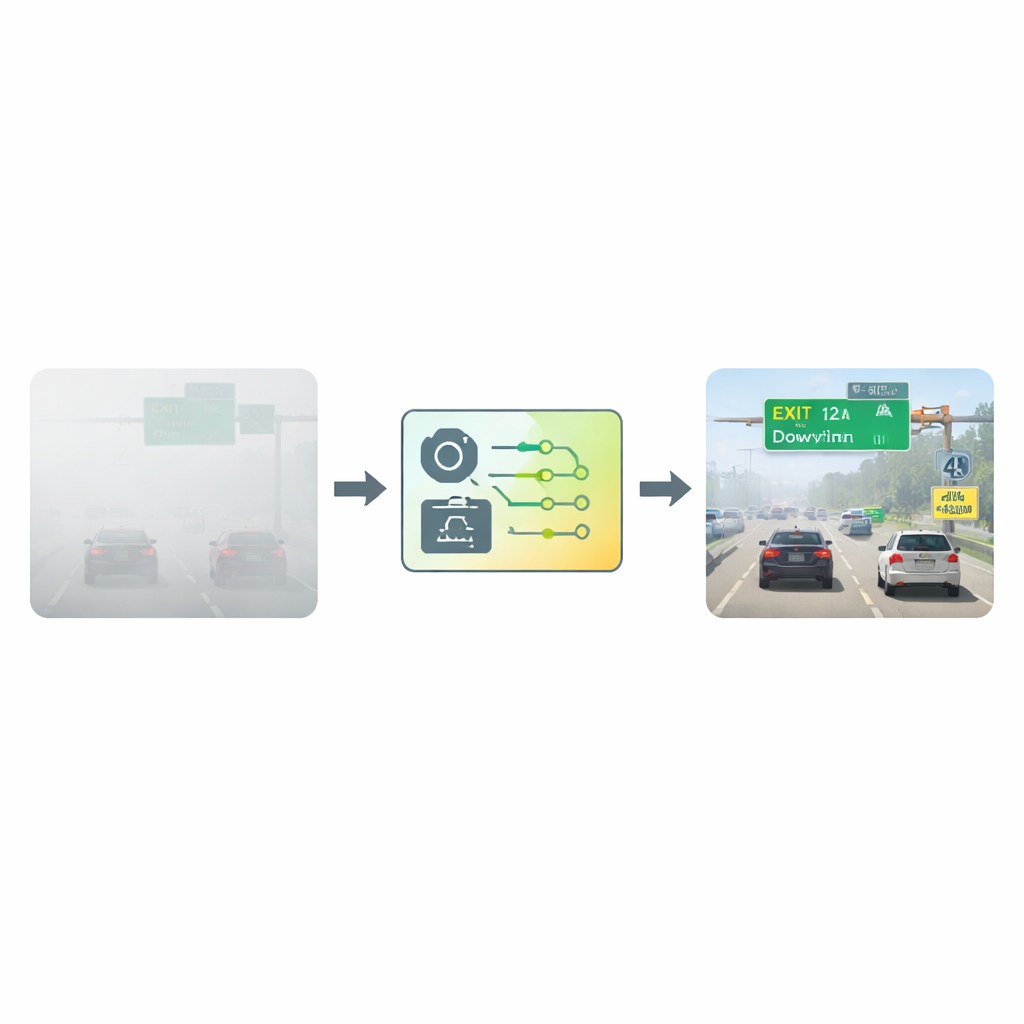
Oczyszczanie obrazu przed czytaniem
Badacze podjęli to wyzwanie, rozwijając powszechnie stosowane ramy wykrywania tekstu znane jako Connectionist Text Proposal Network (CTPN). Zamiast podawać sieci surowe, zamglone obrazy, najpierw każdą klatkę poddają specjalnemu etapowi „odmgławiania”. Etap ten opiera się na modelu atmosferycznym opisującym, jak światło rozprasza się w zawilgoconym powietrzu. Porównując, jak ciemne powinny być różne części obrazu w normalnych warunkach, algorytm oszacowuje, ile mgły znajduje się przed każdym pikselem, a następnie matematycznie „odejmuje” tę zamglenie. Efektem jest jaśniejszy, wyższy kontrast obraz, na którym litery i cyfry wybijają się wyraźniej na tle, dając sieci detekcyjnej znacznie lepszy punkt wyjścia.
Uczenie sieci śledzenia linii tekstu
Po oczyszczeniu obrazu ulepszony model CTPN analizuje go w wąskich, pionowych fragmentach, skanując scenę w poszukiwaniu linii tekstu. Wykorzystuje głęboki ekstraktor cech, pierwotnie zaprojektowany do rozpoznawania obiektów na fotografiach, aby uchwycić szczegółowe wzorce krawędzi i tekstur. Na tej bazie moduł sekwencyjny dwukierunkowy uczy się, jak sąsiednie wycinki łączą się wzdłuż linii tekstu, co pomaga odróżnić prawdziwe pismo od rozproszonych kształtów przypominających znaki. Sieć proponuje następnie kandydackie ramki mogące zawierać tekst i precyzyjniej oszacowuje ich pozycje oraz wysokości, nawet gdy litery są częściowo rozmyte lub nieregularnie rozmieszczone.
Inteligentniejsze filtrowanie nakładających się ramek
Wykrywanie tekstu to tylko połowa problemu; komputery muszą też zdecydować, które z wielu nakładających się propozycji regionów tekstowych są rzeczywiście poprawne. Tradycyjne metody wybierają najsilniejszą ramkę i odrzucają sąsiednie na podstawie stałego progu nakładania. Nowsze podejście, zwane Soft-NMS, łagodnie obniża zaufanie do nakładających się ramek zamiast usuwać je całkowicie, często zachowując blisko rozmieszczony tekst. Każda metoda ma jednak słabości: rygorystyczne filtrowanie może obcinać części rzeczywistych słów, podczas gdy miękkie filtrowanie może pozostawiać zbyt wiele nakładających się ramek lub uwypuklać obiekty nie będące tekstem. W tej pracy połączono zalety obu strategii. Oblicza się wyniki osobno dla każdej metody, porównuje proponowane przez nie ramki, a następnie miesza współrzędne według wyuczonej reguły. To hybrydowe post-processowanie utrzymuje poziome ramki tekstowe w porządku i redukuje zarówno utracone wykrycia, jak i fałszywe alarmy.
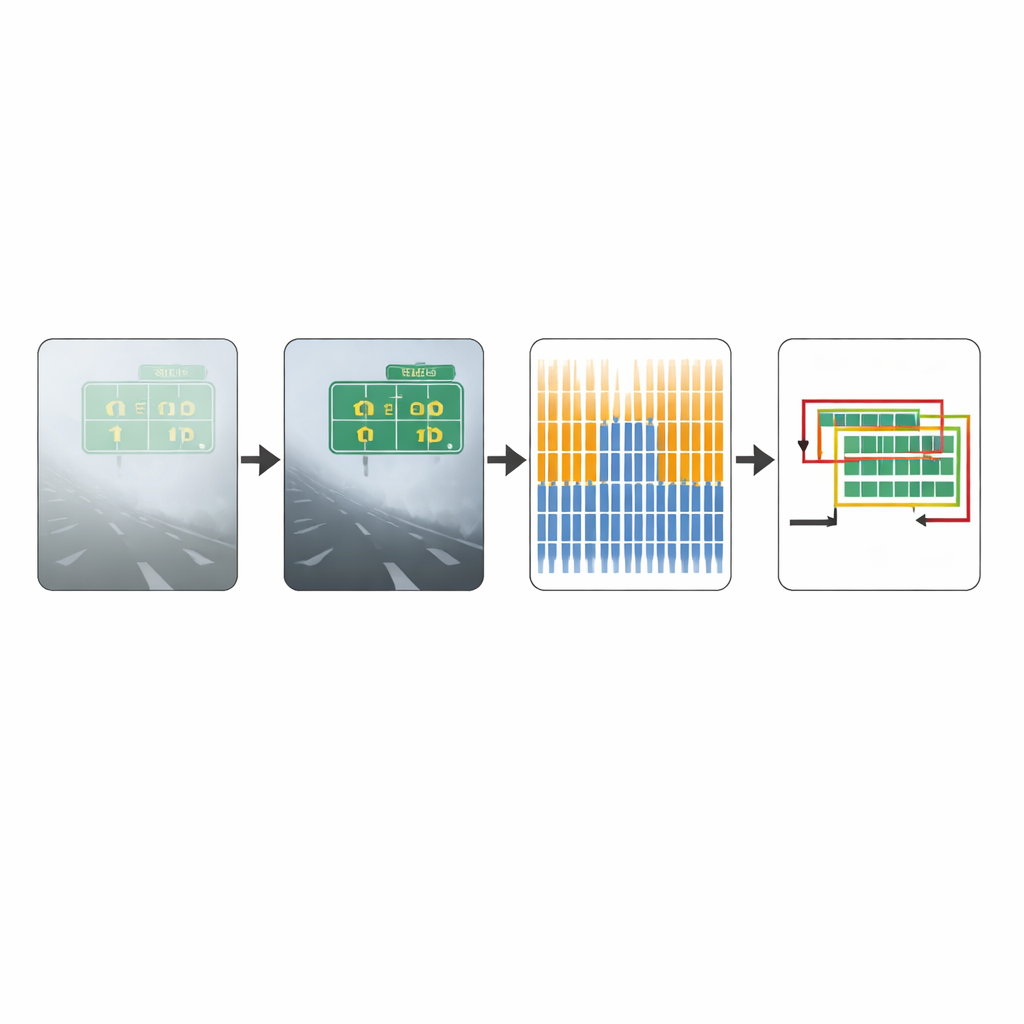
Testowanie metody
Aby ocenić skuteczność swojego podejścia, autorzy przetestowali je na dwóch zbiorach obrazów. Pierwszy, standardowy benchmark codziennych fotografii, zawiera w większości sceny w jasnej pogodzie. Drugi, stworzony przez zespół, koncentruje się na rzeczywistych mgłowych obrazach drogowych i został zaprojektowany specjalnie do testowania wydajności przy trudnej widoczności. Na tym, obfitującym w mgłę zbiorze, ulepszona metoda wykryła znacznie więcej prawdziwych regionów tekstowych niż oryginalny CTPN, jednocześnie nieznacznie poprawiając wskaźnik poprawnych wykryć. Ogólnie rzecz biorąc, złożony wynik dokładności, balansujący pominięcia i błędne wykrycia, wzrósł zauważalnie, co wskazuje na istotny wzrost niezawodności w trudnych warunkach. Przykłady wizualne pokazują, że tam, gdzie oryginalny model pomijał znaki drogowe lub błędnie identyfikował fragmenty pojazdów jako tekst, ulepszony system czyściej obrysowuje rzeczywiste napisy.
Wyraźniejsze ostrzeżenia, gdy są najbardziej potrzebne
Prosto mówiąc, artykuł pokazuje, że nauczenie komputerów najpierw oczyszczania obrazu z mgły, a potem inteligentniejszego filtrowania swoich propozycji, może znacząco poprawić wykrywanie tekstu na drodze. Ulepszony system potrafi wyłapać słowa na znakach i inne teksty związane z ruchem w scenach, które dla oka są prawie nieprzejrzyste. Takie postępy mogą pomóc pojazdom autonomicznym lepiej rozumieć otoczenie w złej pogodzie, wspierać systemy monitoringu ruchu i pomagać w działaniach ratowniczych, gdzie instrukcje lub ostrzeżenia trzeba odczytać przez dym czy mgłę. Autorzy zauważają, że konieczne są dalsze prace nad przyspieszeniem procesu i zintegrowaniem wszystkich etapów w jeden, spójny model, jednak ich wyniki pokazują obiecującą drogę ku bezpieczniejszemu, bardziej odpornemu na warunki atmosferyczne widzeniu maszynowemu.
Cytowanie: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Słowa kluczowe: wykrywanie tekstu w scenie, mgłowe obrazy ruchu drogowego, odmgławianie obrazu, widzenie komputerowe oparte na głębokim uczeniu, percepcja w pojazdach autonomicznych