Clear Sky Science · de
Robuste Texterkennung in nebligen Verkehrsszenen mittels eines verbesserten CTPN-Modells mit Entnebelungs-Vorverarbeitung
Schilder durch den Dunst erkennen
An einem nebligen Morgen können selbst vertraute Straßen unsicher wirken: Autobahnschilder verblassen im Grau, Fahrbahnmarkierungen verschwimmen und digitale Anzeigen werden schwer lesbar. Für menschliche Fahrer und automatisierte Systeme ist es entscheidend, Text auch bei so schlechter Sicht zuverlässig zu erkennen. Diese Studie stellt einen Ansatz vor, Computern das „Sehen“ geschriebener Informationen – etwa Verkehrsschilder und andere Verkehrsaufschriften – beizubringen, selbst wenn dichter Nebel Bilder trübt und den Kontrast verringert.
Warum Nebel intelligente Kameras verwirrt
Moderne Autos, Verkehrskameras und Lieferroboter verlassen sich zunehmend auf Computer Vision, um Schrift in Alltagsszenen zu lesen. Tiefenlernende Systeme sind auf klaren Bildern schon sehr gut darin, Texte zu erkennen – von Schaufenstern bis zu Nummernschildern. Nebelwetter bleibt jedoch ein hartnäckiges Problem. Nebel reduziert den Kontrast, wäscht Farben aus und weicht Kanten auf, sodass scharfe Buchstaben zu verwaschenen, blassen Formen werden. Viele führende Texterkennungsverfahren übersehen diese schwachen Schriftspuren oder verwechseln helle, irrelevante Bereiche – etwa Reflexionen oder Fahrzeugteile – mit Text. Daher versagen Systeme, die auf Standarddatensätzen mit klarem Wetter trainiert wurden, oft dann, wenn die Sicht trüb wird – gerade in Situationen, in denen verlässliche Informationen am wichtigsten sind.
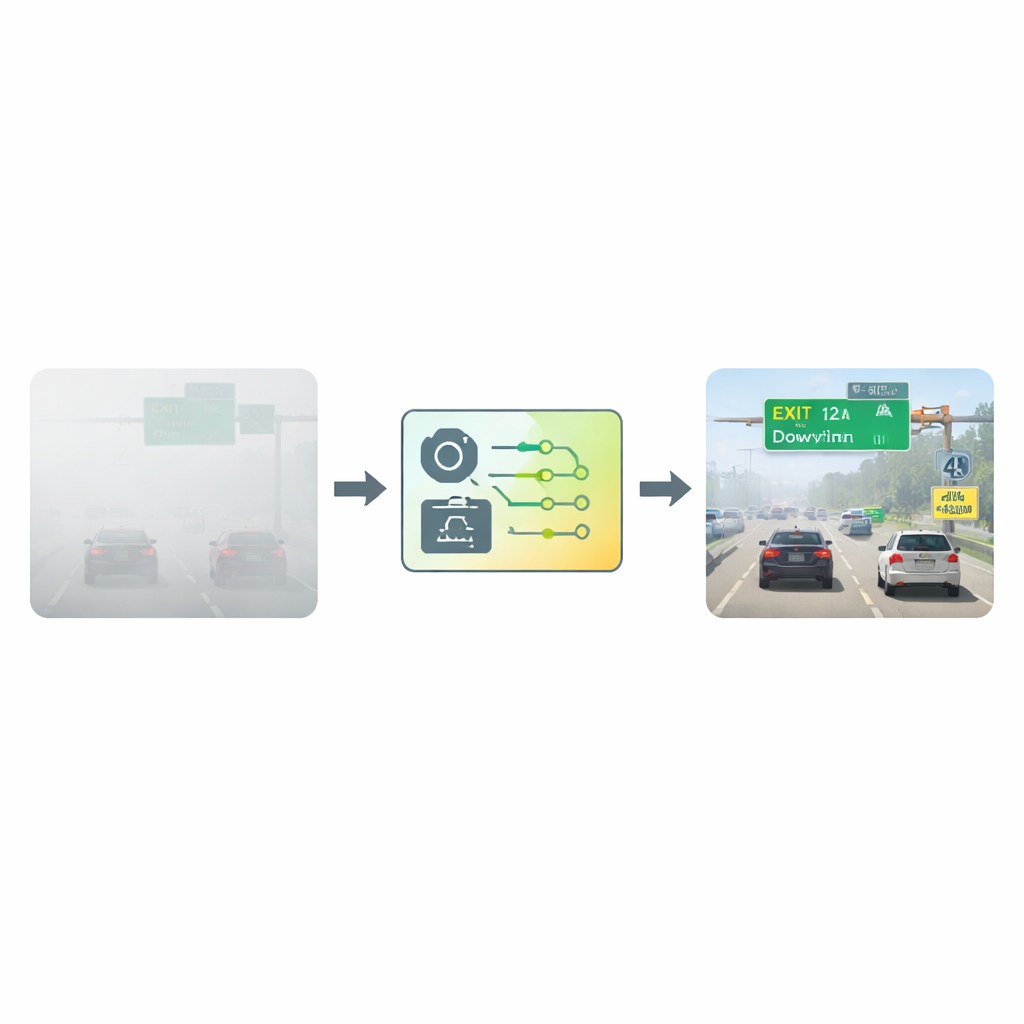
Vor dem Lesen die Sicht säubern
Die Forschenden griffen das Problem auf und bauten auf einem weit verbreiteten Texterkennungsrahmen namens Connectionist Text Proposal Network (CTPN) auf. Anstatt dem Netzwerk rohe neblige Bilder zu übergeben, leiten sie jedes Bild zunächst durch einen spezialisierten Entnebelungsschritt. Dieser Schritt basiert auf einem atmosphärischen Modell, das beschreibt, wie Licht in nebliger Luft gestreut wird. Indem es vergleicht, wie dunkel verschiedene Bildbereiche unter normalen Bedingungen sein sollten, schätzt der Algorithmus, wie viel Nebel vor jedem Pixel liegt, und „subtrahiert“ dann rechnerisch den Dunst. Das Ergebnis ist ein klareres, kontrastreicheres Bild, in dem Buchstaben und Zahlen deutlicher vom Hintergrund abheben und dem Erkennungsnetz einen wesentlich besseren Ausgangspunkt bieten.
Dem Netzwerk beibringen, Textzeilen zu verfolgen
Ist das Bild bereinigt, analysiert das verbesserte CTPN-Modell es in kleinen vertikalen Segmenten und scannt die Szene, um Textzeilen zu finden. Es nutzt einen tiefen Merkmalsextraktor, ursprünglich für die Objekterkennung in Fotografien entwickelt, um feinere Muster von Kanten und Texturen zu erfassen. Darüber lernt ein bidirektionales Sequenzmodul, wie benachbarte Segmente entlang einer Textzeile zusammenpassen, was hilft, echten Text von verstreuten Formen zu unterscheiden, die Buchstaben nur ähneln. Das Netzwerk schlägt dann Kandidatenrahmen vor, die Text enthalten könnten, und schätzt ihre Positionen und Höhen mit verbesserter Genauigkeit, selbst wenn Zeichen teilweise verschwommen oder unregelmäßig angeordnet sind.
Klügere Filterung überlappender Rahmen
Texterkennung ist nur die halbe Miete; Computer müssen auch entscheiden, welche aus vielen überlappenden Vorschlägen wirklich korrekt sind. Traditionelle Methoden wählen den stärksten Rahmen und verwerfen Nachbarrahmen anhand einer festen Überlappungsschwelle. Ein neuerer Ansatz, Soft-NMS, reduziert stattdessen die Vertrauenswerte überlappender Rahmen sanft, statt sie komplett zu löschen, und erhält so häufig eng beieinander stehenden Text. Beide Verfahren haben jedoch Nachteile: strikte Filterung kann Teile echter Wörter abschneiden, während weiche Filterung zu vielen überlappenden Rahmen oder zur Hervorhebung von Nicht-Text führen kann. Diese Arbeit kombiniert die Stärken beider Strategien: Sie berechnet Ergebnisse mit beiden Methoden getrennt, vergleicht die vorgeschlagenen Rahmen und mischt die Koordinaten nach einer gelernten Regel. Diese hybride Nachverarbeitung hält horizontale Textfelder sauber und reduziert sowohl verpasste Erkennungen als auch Fehlalarme.
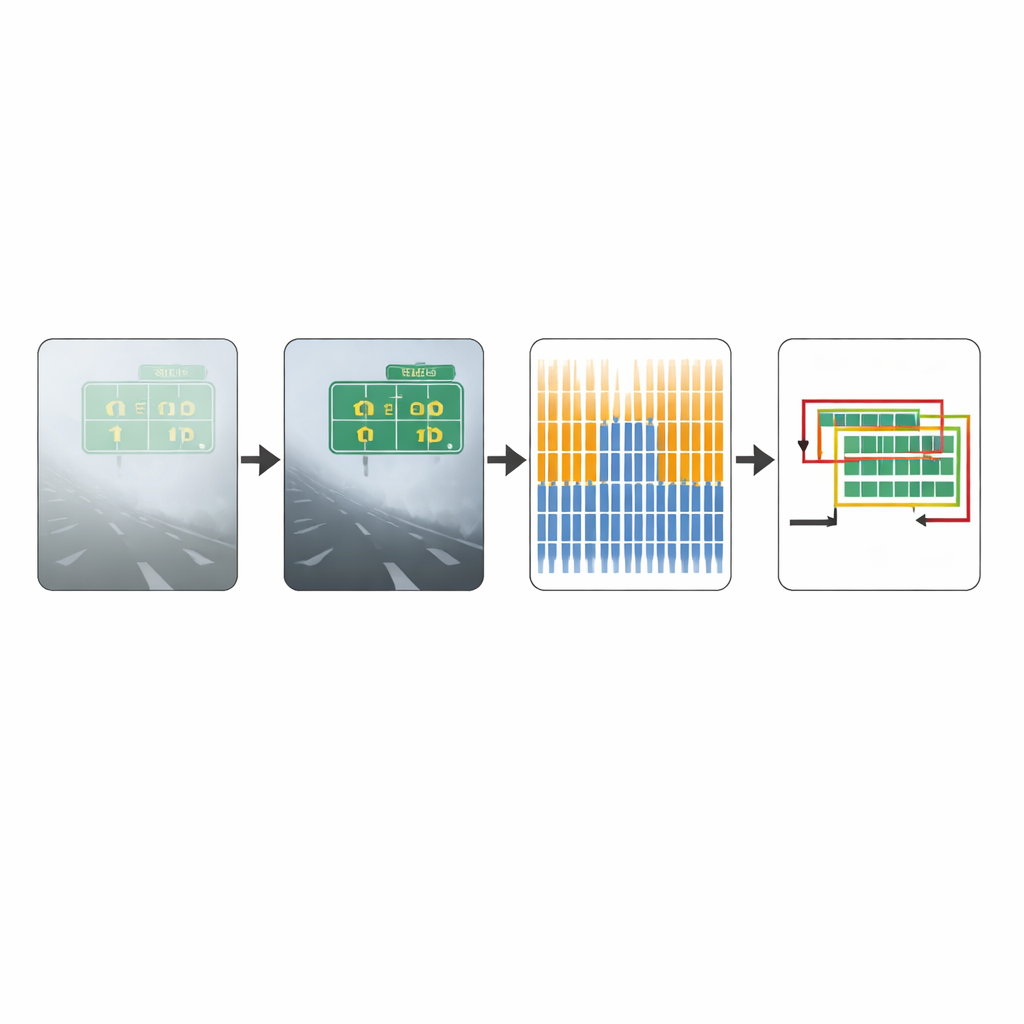
Prüfung der Methode
Um die Leistungsfähigkeit ihres Ansatzes zu prüfen, evaluierten die Autorinnen und Autoren ihn an zwei Bildsammlungen. Die erste, ein Standard-Benchmark alltäglicher Fotografien, enthält überwiegend Szenen bei klarem Wetter. Die zweite, vom Team erstellte Sammlung, konzentriert sich auf echte neblige Verkehrsaufnahmen und wurde speziell entworfen, Leistung bei schlechter Sicht zu testen. In diesem nebelintensiven Datensatz erkannte die verbesserte Methode deutlich mehr echte Textfelder als das ursprüngliche CTPN und verbesserte zugleich leicht die Präzision der Erkennungen. Insgesamt stieg ein kombinierter Genauigkeitswert, der verpasste und falsche Erkennungen ausbalanciert, spürbar an, was auf einen erheblichen Zugewinn an Zuverlässigkeit unter widrigen Bedingungen hinweist. Visuelle Beispiele zeigen, dass dort, wo das Originalmodell Verkehrsschilder übersieht oder Fahrzeugteile als Text fehlinterpretiert, das verbesserte System die tatsächliche Schrift sauberer umreißt.
Deutlichere Warnungen, wenn es am wichtigsten ist
Kurz gesagt: Diese Arbeit zeigt, dass es Rechenmodellen hilft, zunächst den Nebel in einem Bild zu entfernen und ihre Vermutungen anschließend intelligenter zu filtern, um Texte auf der Straße deutlich besser aufzuspüren. Das verbesserte System erkennt Worte auf Schildern und andere verkehrsbezogene Texte in Szenen, die für das bloße Auge fast undurchsichtig sind. Solche Fortschritte könnten autonomen Fahrzeugen helfen, ihre Umgebung bei schlechtem Wetter besser zu verstehen, Verkehrskontrollsysteme unterstützen und sogar Rettungseinsätze erleichtern, wenn Anweisungen oder Warnungen durch Rauch oder Dunst gelesen werden müssen. Die Autorinnen und Autoren merken an, dass weitere Arbeit nötig ist, um den Prozess zu beschleunigen und alle Schritte in ein einheitliches Modell zu integrieren, doch ihre Ergebnisse weisen einen vielversprechenden Weg zu sichererer, wetterresistenterer maschineller Vision.
Zitation: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Schlüsselwörter: Szenntext-Erkennung, neblige Verkehrsaufnahmen, Bildentnebelung, Tiefenlern-Computer-Vision, Wahrnehmung für autonomes Fahren