Clear Sky Science · pt
Detecção robusta de texto em cenas de trânsito com neblina usando um modelo CTPN aprimorado com pré-processamento de desembaçamento
Enxergando placas através da névoa
Em uma manhã enevoada, até estradas familiares podem parecer incertas: placas de rodovia se perdem no cinza, a sinalização de faixas se torna borrada e displays digitais ficam difíceis de ler. Para motoristas humanos e sistemas automatizados, conseguir localizar texto de forma confiável nessas condições de pouca visibilidade é crucial para a segurança. Este estudo apresenta uma maneira de ensinar computadores a “ver” informações escritas — como placas de trânsito e outros textos relacionados ao tráfego — mesmo quando neblina densa torna as imagens turvas e de baixo contraste.
Por que a névoa confunde câmeras inteligentes
Carros modernos, câmeras de tráfego e robôs de entrega dependem cada vez mais de visão computacional para ler palavras em cenas cotidianas. Sistemas de deep learning tornaram-se extraordinariamente bons em detectar texto em imagens claras, de vitrines a placas de veículos. Mas o tempo com neblina ainda representa um problema persistente. A névoa reduz o contraste, apaga cores e amolece contornos, transformando letras nítidas em formas esmaecidas e borradas. Muitos métodos de detecção de texto líderes ou deixam passar esses vestígios tênues de escrita, ou confundem regiões brilhantes irrelevantes — como reflexos ou partes de veículos — com texto. Como resultado, sistemas treinados em conjuntos de dados de condições claras podem falhar quando o cenário fica enevoado, justamente quando a informação confiável pode ser mais necessária.
Limpar a imagem antes de ler
Os pesquisadores abordaram esse desafio partindo de um arcabouço de detecção de texto amplamente usado chamado Connectionist Text Proposal Network, ou CTPN. Em vez de alimentar a rede com imagens enevoadas brutas, eles primeiro passam cada imagem por uma etapa especializada de “desembaçamento”. Essa etapa é baseada em um modelo atmosférico que descreve como a luz se dispersa em ar turvo. Comparando quão escuras diferentes partes da imagem deveriam ser em condições normais, o algoritmo estima quanto de névoa está à frente de cada pixel e então “subtrai” matematicamente a névoa. O resultado é uma imagem mais clara e de maior contraste, onde letras e números se destacam com mais nitidez do fundo, fornecendo à rede de detecção um ponto de partida muito melhor.
Ensinando a rede a seguir linhas de texto
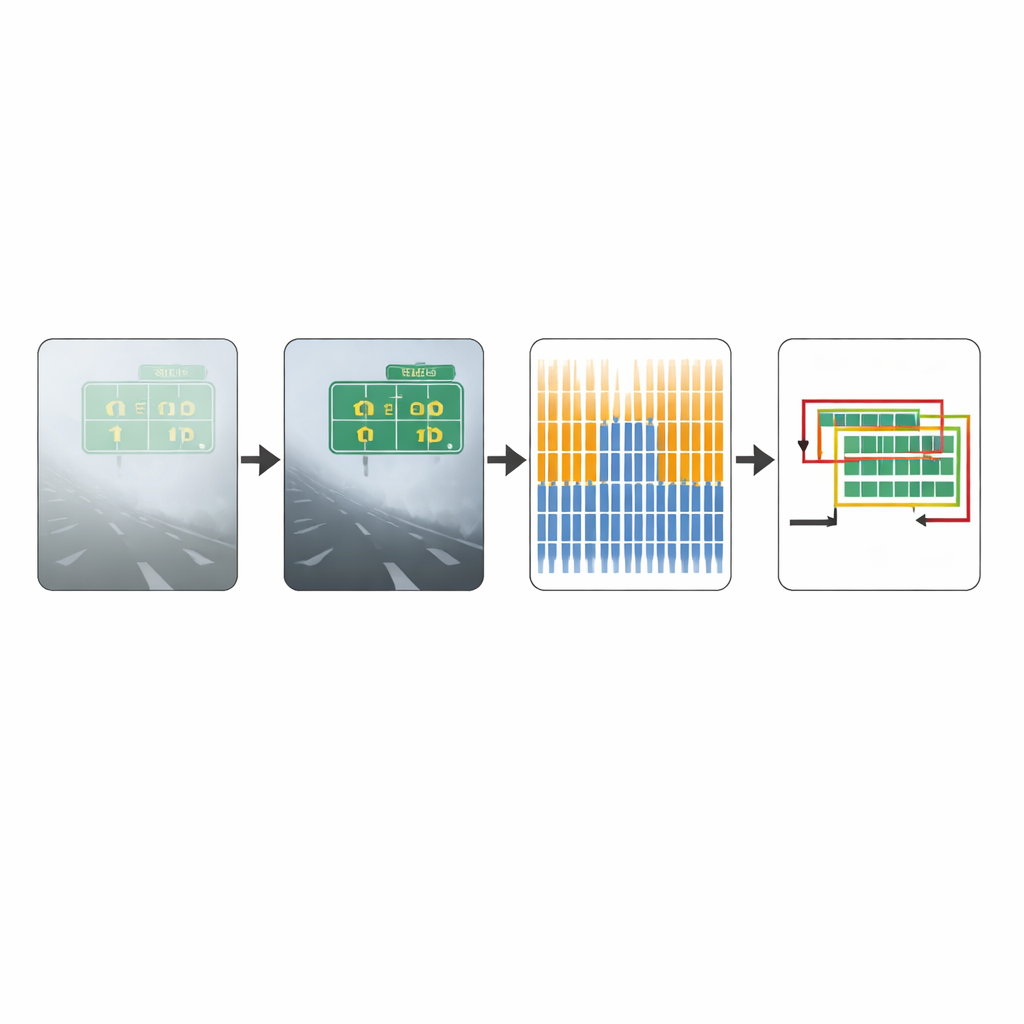
Uma vez que a imagem é limpa, o modelo CTPN aprimorado a analisa em pequenas fatias verticais, escaneando a cena à procura de linhas de texto. Ele usa um extrator profundo de características, originalmente projetado para reconhecer objetos em fotografias, para capturar padrões detalhados de bordas e texturas. Sobre isso, um módulo sequencial bidirecional aprende como fatias vizinhas se articulam ao longo de uma linha de texto, ajudando a distinguir escrita real de formas dispersas que apenas se assemelham a caracteres. A rede então propõe caixas candidatas que podem conter texto e estima suas posições e alturas com precisão refinada, mesmo quando as letras estão parcialmente borradas ou dispostas de forma irregular.
Filtragem mais inteligente de caixas sobrepostas
Detectar texto é só metade da história; os computadores também precisam decidir quais das muitas sugestões sobrepostas de regiões de texto são realmente corretas. Métodos tradicionais escolhem a caixa mais forte e descartam as vizinhas com base em um limiar fixo de sobreposição. Uma abordagem mais recente, chamada Soft-NMS, reduz suavemente a confiança de caixas sobrepostas em vez de eliminá-las por completo, frequentemente preservando textos próximos entre si. Contudo, cada método tem fraquezas: filtragem rigorosa pode cortar partes de palavras reais, enquanto filtragem suave pode deixar caixas sobrepostas demais ou destacar objetos não textuais. Este trabalho combina os pontos fortes de ambas as estratégias. Ele computa resultados usando cada método separadamente, compara como suas caixas sugeridas diferem e então combina as coordenadas segundo uma regra aprendida. Esse pós-processamento híbrido mantém as caixas de texto horizontais organizadas e reduz tanto detecções perdidas quanto alarmes falsos.
Testando o método
Para avaliar a eficácia da abordagem, os autores a testaram em duas coleções de imagens. A primeira, um benchmark padrão de fotografias do dia a dia, contém majoritariamente cenas em tempo claro. A segunda, criada pela equipe, foca em imagens reais de tráfego com neblina e foi projetada especificamente para testar desempenho em baixa visibilidade. Nesse conjunto pesado em névoa, o método aprimorado detectou muito mais regiões de texto verdadeiras do que o CTPN original, ao mesmo tempo em que melhorou ligeiramente a taxa de correção das detecções. No geral, uma pontuação combinada de acurácia, que equilibra detecções perdidas e equivocadas, aumentou de forma notável, indicando um ganho substancial em confiabilidade sob condições adversas. Exemplos visuais mostram que onde o modelo original ignorava placas de trânsito ou identificava partes de veículos como texto, o sistema melhorado contorna mais claramente as escritas reais.
Avisos mais claros quando importa
De forma simples, este artigo demonstra que ensinar computadores a primeiro limpar a névoa na imagem e depois filtrar suas suposições de forma mais inteligente pode torná-los muito melhores em localizar texto na via. O sistema aprimorado consegue identificar palavras em placas e outros textos relacionados ao tráfego em cenas quase opacas ao olho nu. Avanços assim podem ajudar veículos autônomos a entender melhor seu entorno em mau tempo, auxiliar sistemas de monitoramento de tráfego e até apoiar operações de resgate onde instruções ou avisos precisam ser lidos através de fumaça ou névoa. Embora os autores ressaltem que mais trabalho é necessário para acelerar o processo e integrar todas as etapas em um único modelo enxuto, seus resultados demonstram um caminho promissor rumo a uma visão de máquina mais segura e resistente às condições meteorológicas.
Citação: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Palavras-chave: detecção de texto em cena, imagens de trânsito com neblina, remoção de neblina em imagens, visão por computador com deep learning, percepção para direção autônoma