Clear Sky Science · es
Detección robusta de texto en escenas de tráfico con niebla mediante un modelo CTPN mejorado con preprocesamiento de eliminación de niebla
Ver señales a través de la niebla
En una mañana brumosa, incluso carreteras familiares pueden resultar inciertas: las señales de la autopista se desvanecen en gris, las marcas de carril se difuminan y las pantallas digitales se vuelven difíciles de leer. Tanto para conductores humanos como para sistemas automatizados, poder localizar texto de forma fiable en condiciones de baja visibilidad es crucial para la seguridad. Este estudio presenta una forma de enseñar a las máquinas a “ver” información escrita—como señales de tráfico y otros textos viales—incluso cuando la densa niebla hace que las imágenes sean turbias y de bajo contraste.
Por qué la niebla confunde a las cámaras inteligentes
Los coches modernos, las cámaras de tráfico y los robots repartidores dependen cada vez más de la visión por ordenador para leer palabras en escenas cotidianas. Los sistemas de deep learning se han vuelto notablemente buenos detectando texto en imágenes claras, desde escaparates hasta matrículas. Pero la niebla sigue siendo un problema persistente. La niebla reduce el contraste, blanquea los colores y suaviza los bordes, convirtiendo letras nítidas en formas apagadas y difusas. Muchos métodos líderes de detección de texto o bien no detectan estos rastros tenues de escritura o confunden regiones brillantes pero irrelevantes—como reflejos o partes de vehículos—con texto. Como resultado, los sistemas entrenados con conjuntos de datos en condiciones claras pueden fallar cuando el clima se vuelve brumoso, justo cuando la información fiable puede ser más importante.
Limpiar la vista antes de leer
Los investigadores abordaron este desafío partiendo de un marco de detección de texto ampliamente usado, la Red de Propuestas de Texto Conexionista, o CTPN. En lugar de alimentar la red con imágenes brumosas en bruto, primero pasan cada imagen por un paso especializado de “eliminación de niebla”. Este paso se basa en un modelo atmosférico que describe cómo la luz se dispersa en el aire con niebla. Comparando cuán oscuras deberían ser distintas partes de la imagen en condiciones normales, el algoritmo estima cuánto haze hay delante de cada píxel y luego “resta” matemáticamente la neblina. El resultado es una imagen más clara y de mayor contraste donde letras y números resaltan con mayor nitidez respecto al fondo, dando a la red de detección un mejor punto de partida.
Enseñar a la red a seguir líneas de texto
Una vez que la imagen está limpiada, el modelo CTPN mejorado la analiza en pequeñas rebanadas verticales, explorando la escena para encontrar líneas de texto. Emplea un extractor profundo de características, diseñado originalmente para reconocer objetos en fotografías, para capturar patrones detallados de bordes y texturas. Encima de esto, un módulo de secuencia bidireccional aprende cómo las rebanadas vecinas encajan a lo largo de una línea de texto, ayudando a distinguir la escritura real de formas dispersas que solo se asemejan a caracteres. La red propone entonces cajas candidatas que podrían contener texto y estima sus posiciones y alturas con mayor precisión refinada, incluso cuando las letras están parcialmente borrosas o dispuestas de forma irregular.
Filtrado más inteligente de cajas solapadas
Detectar texto es solo la mitad de la tarea; los sistemas también deben decidir cuáles de las muchas sugerencias solapadas para regiones de texto son realmente correctas. Los métodos tradicionales eligen la caja de mayor puntuación y descartan las vecinas según un umbral fijo de solapamiento. Un enfoque más reciente, llamado Soft-NMS, reduce suavemente la confianza de las cajas solapadas en lugar de eliminarlas por completo, preservando a menudo texto muy cercano. Sin embargo, cada método tiene debilidades: el filtrado estricto puede recortar partes de palabras reales, mientras que el filtrado suave puede dejar demasiadas cajas solapadas o resaltar objetos no textuales. Este trabajo combina las fortalezas de ambas estrategias. Calcula resultados usando cada método por separado, compara cómo difieren sus cajas propuestas y luego mezcla las coordenadas según una regla aprendida. Este posprocesado híbrido mantiene las cajas horizontales ordenadas y reduce tanto las detecciones perdidas como las falsas alarmas.
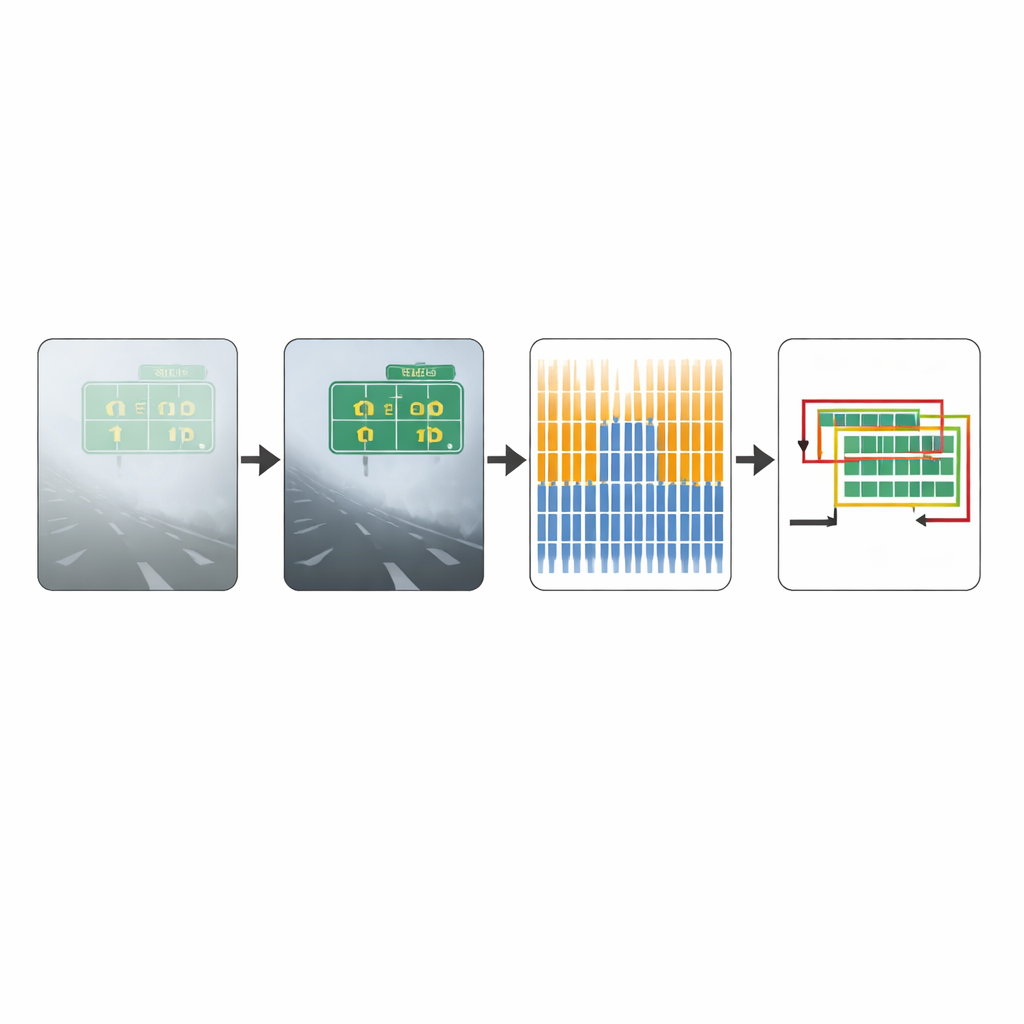
Poner el método a prueba
Para evaluar el rendimiento de su enfoque, los autores lo probaron en dos colecciones de imágenes. La primera, un benchmark estándar de fotografías cotidianas, contiene mayormente escenas en buen tiempo. La segunda, creada por el equipo, se centra en imágenes reales de tráfico con niebla y está diseñada específicamente para evaluar el rendimiento en visibilidad difícil. En este conjunto con alta presencia de niebla, el método mejorado detectó muchas más regiones de texto reales que el CTPN original, al mismo tiempo que mejoró ligeramente la proporción de detecciones correctas. En conjunto, una medida combinada de precisión que equilibra detecciones perdidas y erróneas aumentó de forma notable, indicando una ganancia sustancial en fiabilidad bajo condiciones adversas. Ejemplos visuales muestran que donde el modelo original omite señales viales o identifica por error partes de vehículos como texto, el sistema mejorado delimita con mayor claridad la escritura real.
Advertencias más claras cuando importan más
En términos sencillos, este artículo demuestra que enseñar a las máquinas a primero despejar la niebla de una imagen y luego filtrar sus supuestos de forma más inteligente puede mejorar mucho su capacidad para detectar texto en la carretera. El sistema mejorado puede identificar palabras en señales y otros textos relacionados con el tráfico en escenas que son casi opacas para el ojo humano. Tales avances podrían ayudar a que los vehículos autónomos comprendan mejor su entorno en mal tiempo, apoyar sistemas de monitoreo de tráfico e incluso asistir en operaciones de rescate donde sea necesario leer instrucciones o advertencias a través del humo o la neblina. Aunque los autores señalan que hace falta trabajo adicional para acelerar el proceso e integrar todos los pasos en un único modelo optimizado, sus resultados muestran un camino prometedor hacia una visión por máquina más segura y resistente a las inclemencias meteorológicas.
Cita: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Palabras clave: detección de texto en escena, imágenes de tráfico con niebla, eliminación de niebla en imágenes, visión por deep learning, percepción en conducción autónoma