Clear Sky Science · ru
Надёжное обнаружение текста в туманных дорожных сценах с использованием усовершенствованной модели CTPN и предобработки удаления тумана
Видеть знаки сквозь мглу
В туманный рассвет даже знакомые дороги кажутся неопределёнными: дорожные указатели теряются в сером, разметка полос становится неясной, а цифровые дисплеи трудно прочитать. Как для человека, так и для автоматизированных систем способность надёжно обнаруживать текст в таких условиях жизненно важна для безопасности. В этой работе показан метод, который позволяет компьютерам «увидеть» письменную информацию — например дорожные знаки и другие текстовые элементы на дороге — даже когда густой туман делает изображения мутными и с низкой контрастностью.
Почему туман сбивает с толку умные камеры
Современные автомобили, уличные камеры и доставочные роботы всё чаще полагаются на компьютерное зрение для чтения надписей в повседневных сценах. Системы глубокого обучения стали очень эффективны в обнаружении текста на чётких изображениях, от витрин до номерных знаков. Но туман по-прежнему остаётся упрямой проблемой. Он снижает контраст, стирает цвета и смягчает края, превращая резкие буквы в размазанные бледные формы. Многие передовые алгоритмы обнаружения текста либо пропускают эти тусклые следы написанного, либо принимают яркие, но несущественные области — например блики или части автомобилей — за текст. В результате системы, обученные на стандартных наборах данных для ясной погоды, могут давать сбои в тумане, именно тогда, когда надёжная информация особенно важна.
Очистить изображение перед чтением
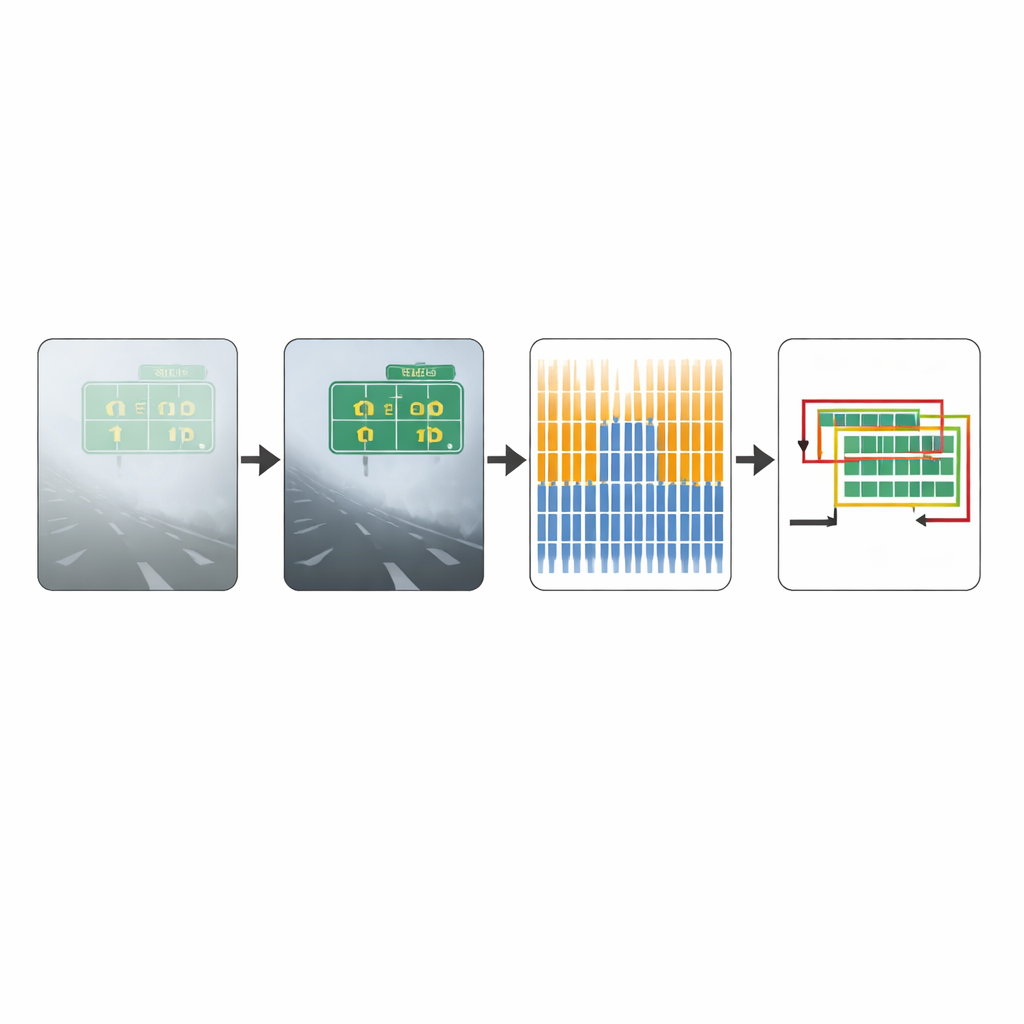
Авторы подошли к задаче, опираясь на широко используемую архитектуру для обнаружения текста — Connectionist Text Proposal Network (CTPN). Вместо того чтобы подавать в сеть исходные туманные кадры, они сначала прогоняют каждое изображение через специализированный этап «удаления тумана». Этот этап основан на атмосферной модели, описывающей, как свет рассеивается в запылённом или туманном воздухе. Сравнивая, насколько тёмными разные участки изображения должны быть в нормальных условиях, алгоритм оценивает, сколько тумана находится перед каждым пикселем, и затем математически «вычитает» дымку. В результате получается более чёткое изображение с повышенным контрастом, где буквы и цифры чётче выделяются на фоне, давая сети обнаружения гораздо лучший старт.
Обучение сети следовать линиям текста
После очистки изображения улучшенная модель CTPN анализирует его маленькими вертикальными срезами, просматривая сцену в поисках текстовых строк. Она использует глубокий извлекатель признаков, изначально разработанный для распознавания объектов на фотографиях, чтобы улавливать детальные шаблоны краёв и текстур. Сверху на этом модуле работает двунаправленный последовательный блок, который учится, как соседние срезы объединяются вдоль линии текста, помогая отличать реальные надписи от рассыпавшихся форм, лишь отдалённо напоминающих символы. Сеть затем предлагает кандидаты-прямоугольники, которые могут содержать текст, и уточняет их положения и высоты с повышенной точностью, даже когда буквы частично размыты или размещены неравномерно.
Более разумная фильтрация перекрывающихся боксов
Обнаружение текста — это только половина задачи; компьютерам также нужно решить, какие из множества перекрывающихся предложений областей текста действительно корректны. Традиционные методы выбирают самый сильный бокс и удаляют соседние на основе фиксированного порога перекрытия. Новая техника, называемая Soft-NMS, плавно снижает уверенность в перекрывающихся боксах вместо их полного удаления, что часто сохраняет плотно расположенный текст. Однако у каждого подхода есть слабые стороны: строгая фильтрация может отрезать части реальных слов, тогда как мягкая — оставить слишком много перекрывающихся боксов или выделить не-текстовые объекты. В этой работе сочетаются сильные стороны обоих методов. Авторы получают результаты каждым способом отдельно, сравнивают различия в предлагаемых боксах и затем объединяют координаты согласно выученному правилу. Такое гибридное пост-обработка сохраняет горизонтальные текстовые боксы аккуратными и уменьшает как пропуски обнаружений, так и ложные срабатывания.
Испытание метода на практике
Чтобы оценить эффективность подхода, авторы протестировали его на двух наборах изображений. Первый — стандартный бенчмарк повседневных фотографий — в основном содержит сцены при ясной погоде. Второй, собранный командой, сосредоточен на реальных туманных дорожных снимках и специально предназначен для проверки качества работы в условиях плохой видимости. На этом наборе с сильным туманом улучшенный метод обнаружил значительно больше реальных текстовых областей, чем оригинальный CTPN, при этом слегка повысилась и точность корректных срабатываний. В целом комбинированная метрика, уравновешивающая пропуски и ложные обнаружения, заметно выросла, что указывает на существенное улучшение надёжности в неблагоприятных условиях. Визуальные примеры показывают, что там, где исходная модель пропускала дорожные знаки или ошибочно принимала части автомобилей за текст, улучшенная система чище выделяет настоящие надписи.
Более явные предупреждения в критические моменты
Проще говоря, в статье показано, что обучение компьютеров сначала приводить изображение в более чистый вид, устраняя туман, а затем более интеллектуально фильтровать свои гипотезы позволяет существенно улучшить обнаружение текста на дороге. Улучшенная система способна выделять слова на знаках и другой дорожной текст в сценах, которые для человеческого глаза почти непрозрачны. Такие достижения могут помочь автономным транспортным средствам лучше понимать окружение в плохую погоду, поддержать системы мониторинга трафика и даже помочь спасательным операциям, когда инструкции или предупреждения нужно прочесть сквозь дым или мглу. Авторы отмечают, что предстоит доработать скорость работы и интеграцию всех этапов в единый оптимизированный модуль, но их результаты демонстрируют перспективный путь к более безопасному и устойчивому к погодным условиям машинному зрению.
Цитирование: Han, C., Xiong, Z., Liu, Y. et al. Robust text detection in foggy traffic scenes using an enhanced CTPN model with de-fogging pre-processing. Sci Rep 16, 13335 (2026). https://doi.org/10.1038/s41598-026-43357-3
Ключевые слова: обнаружение текста в сцене, туманные дорожные изображения, удаление тумана из изображения, глубокое обучение в компьютерном зрении, восприятие для автономного вождения