Clear Sky Science · sv
En hybrid SMOTE- och Gaussisk blandningsmodell-baserad optimerad XGBoost-ram för upptäckt av bipolär sjukdom
Varför detta är viktigt för vardaglig mental hälsa
Bipolär sjukdom kan kraftigt störa en persons liv, men upptäcks eller felbedöms ofta först efter flera år. Många upplever växlingar mellan intensiva uppvarvade perioder och förkrossande nedstämdhet innan de får rätt hjälp. Denna studie undersöker hur avancerade datoriserade metoder kan sålla i rutinmässiga kliniska frågeformulär och journaler för att i ett tidigare skede och mer pålitligt markera personer som kan ha bipolär sjukdom. Arbetet pekar mot beslutsstödsverktyg som kan fungera vid sidan av kliniker, hjälpa dem att hitta mönster som människor lätt förbiser men som är avgörande för att ge vård i tid.

Utmaningen att upptäcka dolda humörsvängningar
Bipolär sjukdom ser inte likadan ut hos alla. Symptom kan överlappa med depression, ångest och andra tillstånd, och många bedömningar bygger på vad patienter minns och hur läkare tolkar korta besök. Som en följd missas viktiga varningstecken och patienter kan få behandlingar som inte passar deras verkliga tillstånd. Dessutom innehåller medicinska databaser vanligtvis långt färre bekräftade bipolära fall än icke-bipolära, vilket försvårar för vanliga datoriserade modeller att lära sig hur bipolär sjukdom verkligen yttrar sig. Författarna menar att vi behöver verktyg som kan hantera denna obalans, upptäcka dolda patientundergrupper och ändå vara förståeliga för kliniker.
En smart pipeline byggd av enkla byggstenar
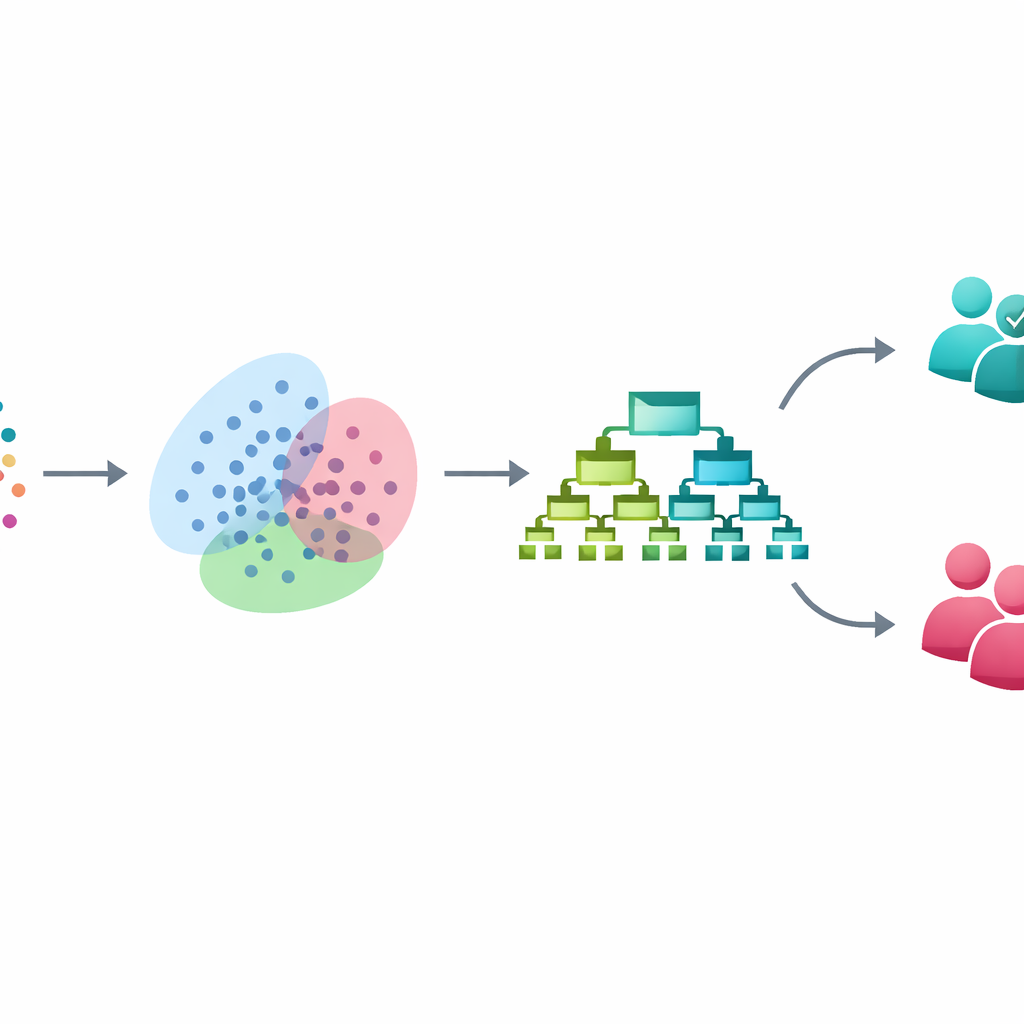
I stället för att vända sig till svårgenomträngliga djupa inlärningssystem bygger forskarna en steg-för-steg-pipeline av tre väletablerade tekniker, där varje teknik löser ett specifikt problem. Först rensar och standardiserar de en datamängd med 3 753 personer, vardera beskrivna av 54 kliniska och frågeformsbaserade variabler relaterade till humör, sömn, beteende och funktionsnivå. Därefter hanterar de den ojämna fördelningen mellan bipolära och icke-bipolära fall med en metod kallad SMOTE. Istället för att enkelt kopiera sällsynta bipolära fall skapar SMOTE nya "mellanliggande" exempel genom att försiktigt interpolera mellan verkliga bipolära patienter, vilket ger datorn en mer balanserad erfarenhet av båda grupperna under träningen samtidigt som testdata lämnas orörda.
Att hitta dolda grupper i data
Efter att ha balanserat datan tillämpar pipelinen Gaussisk blandningsmodellering, en flexibel klustringsmetod som söker naturliga grupperingar bland patienterna utan att använda diagnosetiketterna. I stället för att tvinga varje person in i en enda låda tilldelar metoden sannolikheter för tillhörighet i flera överlappande grupper, vilket speglar de suddiga gränser som ofta ses i verklig psykiatrisk praktik. Dessa sannolikheter läggs därefter till som nya, subtila funktioner som beskriver varje patients position bland dessa dolda undergrupper. I praktiken lär sig modellen inte bara av det som frågeformulären direkt mäter, utan också från djupare likhetsmönster som kan motsvara olika symtombilder eller sjukdomsstadier.
Att omvandla mönster till praktiska förutsägelser
Med denna berikade beskrivning av varje patient använder det sista steget XGBoost, en kraftfull ensemble av beslutsträd som är särskilt effektiv för tabellformad klinisk data. Forskarna finjusterar modellen med korsvalidering och håller alla balanserings- och klustringssteg strikt inom träningsprocessen för att undvika läckage till testuppsättningen. På osedd data klassificerar deras system korrekt bipolära kontra icke-bipolära fall 93 % av gångerna. Det identifierar 97 % av verkliga bipolära fall (hög känslighet) samtidigt som det upprätthåller 93 % precision och en stark balans mellan att fånga verkliga fall och undvika falska larm. Jämfört med välkända metoder som logistisk regression, beslutsträd, supportvektormaskiner och random forest förbättrar den nya ramen prestandan med 6 till 12 procentenheter, beroende på jämförelsen.
Vad detta innebär för patienter och kliniker
För en lekmannapublik är huvudslutsatsen att detta hybrida tillvägagångssätt erbjuder ett mer pålitligt tidigt varningssystem, inte en ersättning för en psykiater. Genom att balansera datan, avslöja dolda patientundergrupper och använda en tolkbar träd-baserad modell kan ramen flagga individer som sannolikt har bipolär sjukdom så att kliniker kan undersöka vidare med etablerade diagnostiska riktlinjer som DSM-5 eller ICD-11. Författarna betonar att verktyget är tillräckligt transparent för att visa vilka kliniska och undergruppsfunktioner som är viktigast, vilket gör det lättare att lita på och integrera i verklig vård. Även om studien är baserad på en enda datamängd och behöver prövas över flera sjukhus och populationer, visar den att en genomtänkt kombination av flera blygsamma tekniker kan ge ett praktiskt, skalbart stöd för tidigare och mer träffsäker screening av bipolär sjukdom.
Citering: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Nyckelord: upptäckt av bipolär sjukdom, screening av mental hälsa, maskininlärning inom psykiatri, kliniskt beslutsstöd, obalanserade medicinska data